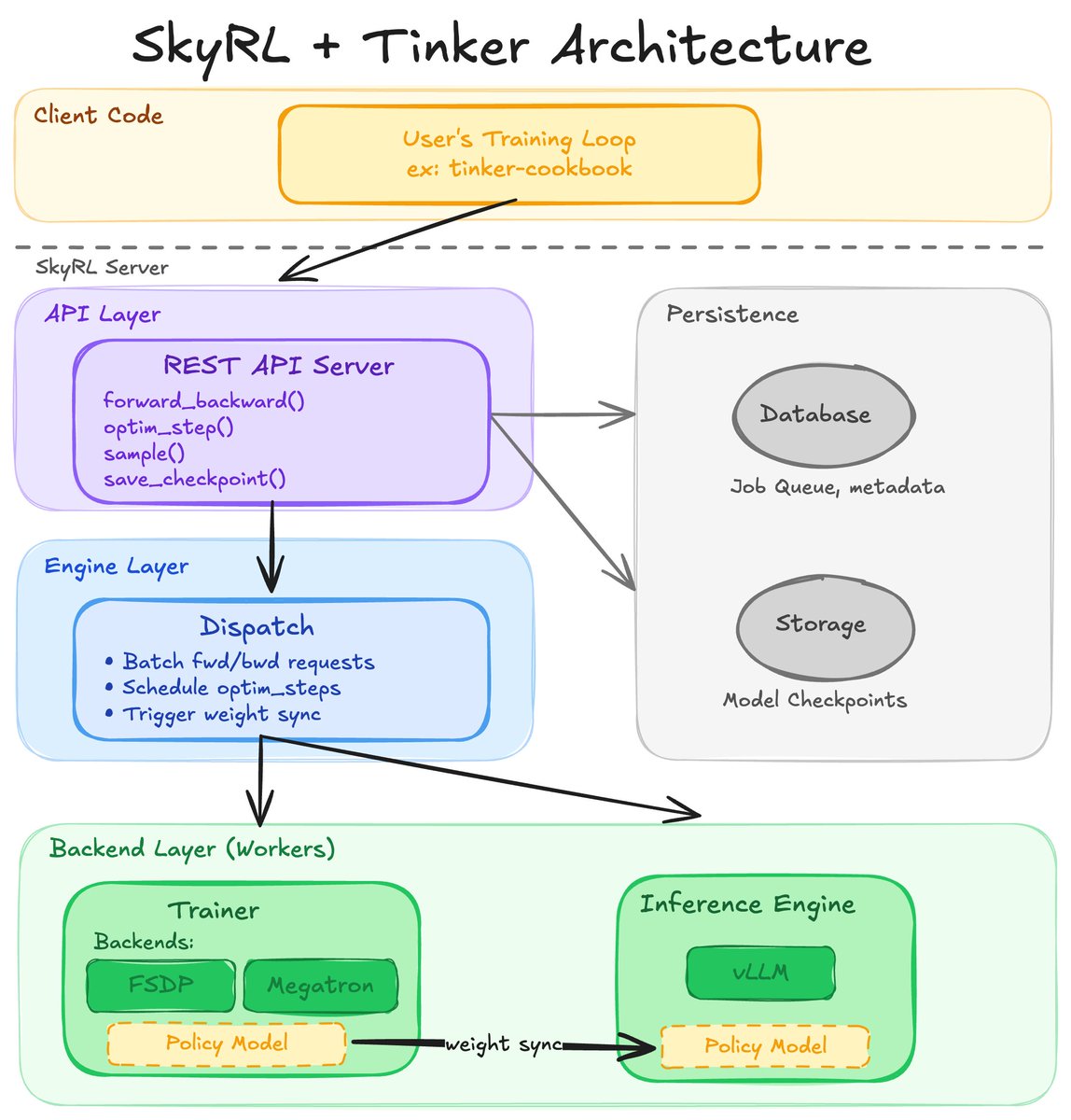
We are excited to announce that SkyRL now implements the Tinker API. Run Tinker training scripts on your own hardware with zero code changes.
Try it out today: https://t.co/uD5DlDjhnp
SkyRL now implements the Tinker API.
Now, training scripts written for Tinker can run on your own GPUs with zero code changes using SkyRL's FSDP2, Megatron, and vLLM backends.
Blog: https://t.co/GAtW81jM38
🧵
🏹5 Days of Trajectory.
Day 3 - An Open Source Training Stack for Continual Learning
Building the platform for continual learning requires both partnering with pioneering AI companies, as we showed on Day 2 with Harvey, and working toward frontier research, which we are highlighting today.
Continual learning means models that improve hourly from real production use. But with the size of frontier models, this becomes quite difficult. A Qwen-397b would need to spin up and tear down repeatedly across six GPU nodes, and that's valuable time gone.
Our contribution is Continual LoRA (C-LoRA): many lightweight adapters running at once on one shared base model. Our insight centers on where the parallelism lives: instead of splitting one giant job across nodes, we load-balance many small jobs over a single base.
The result: 2.81x experiment throughput over single-tenant training, with no regression on rewards.
We built this together, with @anyscalecompute, @NovaSkyAI, and generous support from @GoogleCloud and @GoogleStartups. We've open-sourced on SkyRL as one of the first multi-LoRA, RL training platforms, so that every team can get to continual learning faster.
We’re very excited to see what you build, please reach out!
We've shipped two major upgrades for RL✨!
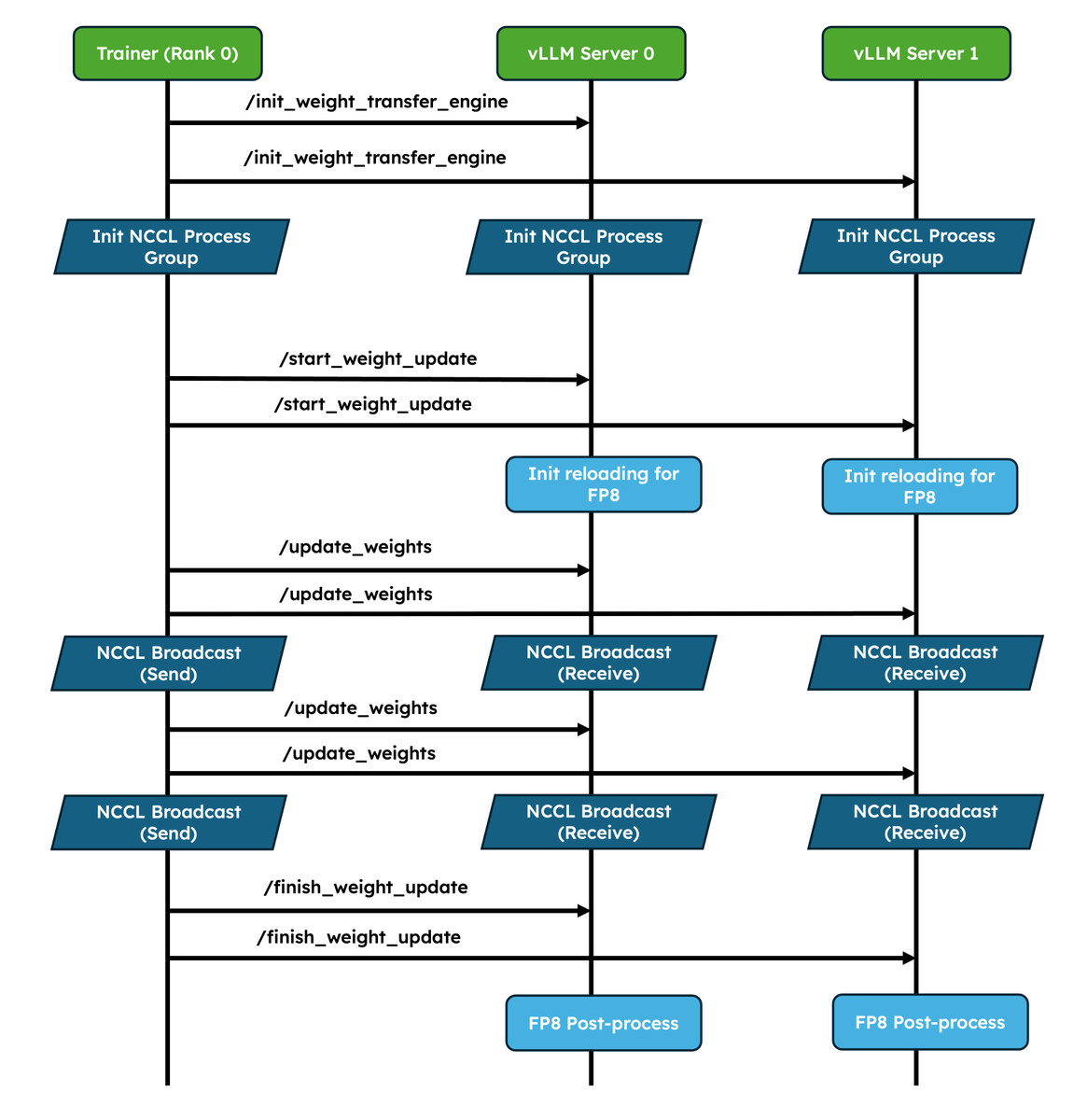
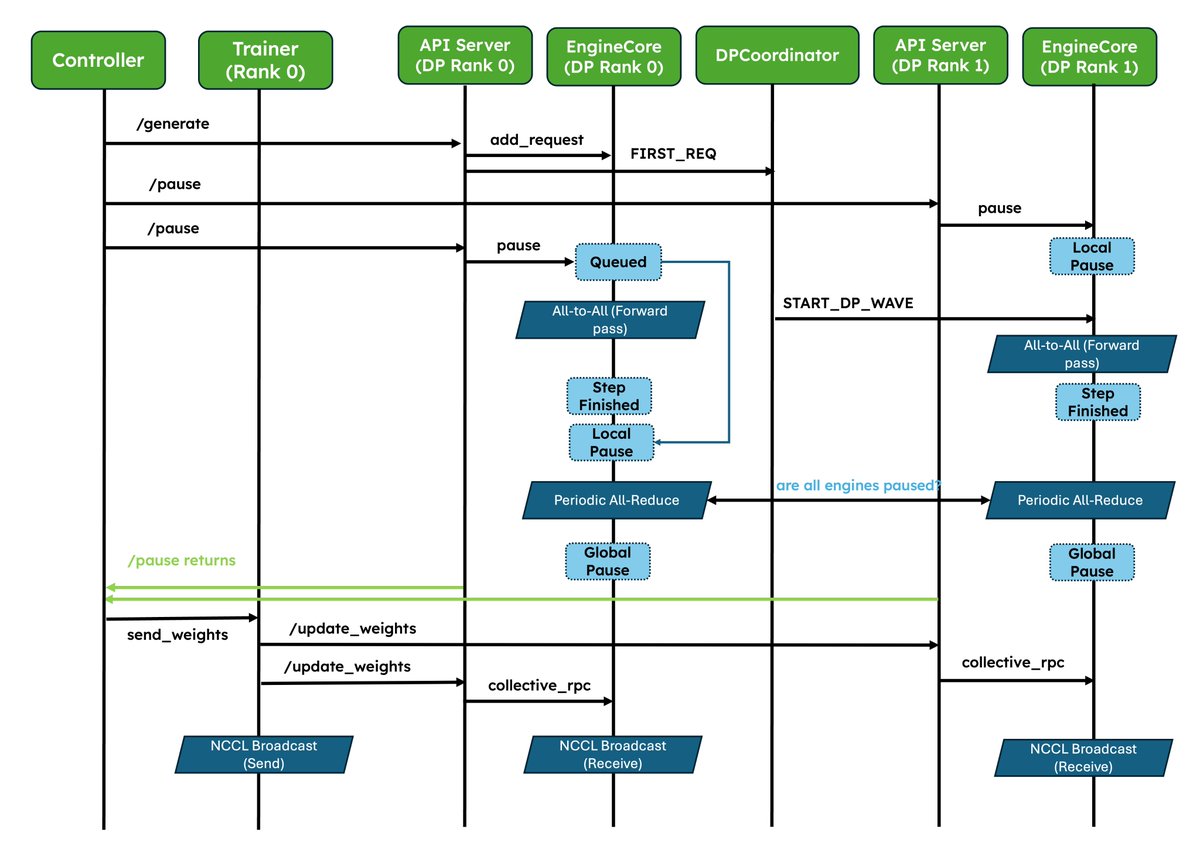
1. Native weight syncing APIs: Standardizes weight transfer, provides optimized implementations for NCCL and CUDA IPC out of the box, and also lets frameworks easily bring their own.
2. Improved pause/resume for Async RL: Careful coordination between DP ranks so that engines don’t deadlock. Validated at scale in P/D, wide-EP setups!
In collaboration with @anyscalecompute, @NovaSkyAI, and @RedHat.
More and more RL frameworks are using vLLM as the default for inference, details in the blog 👇
https://t.co/LLmL8zJLtR
Amazing work! More and more RL frameworks are using vLLM as default. @vllm_project along with @anyscalecompute and @NovaSkyAI revamped weight syncing and improved wide-ep deployment for rollout!
it's been a really great experience working w/ @j316chuck and the @trajectorylabs team on building out their post-training stack for continual learning on top of SkyRL
really excited to continue collaborating and seeing how the team can push the frontier for continual learning!
Today, @MichaelElabd, @QuantumArjun, and I are excited to announce Trajectory.
We are a research lab and product company building the platform for Continual Learning.
Our platform unlocks the signal already sitting in product usage, so companies can continuously post-train large-scale agentic models that outperform the frontier. @trajectorylabs
We’ve raised $15M from @Conviction, @BessemerVP, @radicalvcfund, @jeffdean, @drfeifei and more.
We’re partnering with some of the best AI-native companies: @ClayRunHQ@Harvey, @DecagonAI, @mercor_ai, @RogoAI to power their agentic systems, some of which we are already in production with.
We’ve brought together a world class research team from DeepMind, OpenAI, Apple, Meta Superintelligence, Amazon AGI, Scale AI, and an elite product team from Stripe and Figma.
AI will never again start on day one. Every correction, every retry, every edit will make products smarter. This is Continual Learning.
SkyRL now supports end-to-end vision-language post-training, from SFT to agentic RL, and adds vision model support to SkyRL’s Tinker interface! Existing multimodal cookbooks, e.g. VLM classification, work out of the box:
🚀 Excited to share the training & inference results for UCCL-EP: a portable, high-performance expert-parallel communication library across heterogeneous GPU + NIC hardware.
💻 Code: https://t.co/wVWiso8ajS
📝 Blog: https://t.co/PSRH7CQpK6
📈 Highlights:
• Up to 45% faster Megatron-LM training vs RCCL on 128 AMD GPUs
• Up to 40% faster SGLang inference vs NCCL on 32 H200 GPUs
• Up to 25% lower vLLM TPOT vs NCCL
• Up to 2.3x better EP dispatch/combine on AWS EFA
🔁 Fully portable across heterogeneous GPU/NIC hardware and a drop-in replacement for DeepEP
Amazing team: Chon Lam Lao, @yangzhouy, Yihan Zhang, Chihan Cui, Zhongjie Chen, Zhiying Xu, @KaichaoYou, Zhen Huang, Zhenyu Gu, Costin Raiciu, Scott Shenker, @istoica05
Great work from the @OpenHandsDev community and CMU! Open source SOTA on code localization via RL. Happy to see the beautiful reward curves trained with SkyRL!
Can we train code agents to search relevant locations in a codebase only using a terminal?
Introducing CodeScout: an effective RL recipe for code search 🚀
🏆 Outperforms 18x larger OSS LLMs
🔥 Comparable to proprietary LLMs
📈 SoTA on SWE-Bench Verified, Pro, & Lite
🧵 [1/N]
Excited to see SkyRL sharing their work on inference and vLLM in RL at the LLMs on Ray office hours this Thursday.
If you’re exploring using vLLM in RL workflows, this will be a great session to join.
See you there 👇
We’ve been consistently surprised lately by how capable frontier models are at handling complex kernel implementation and system optimization.
Check out this work as a step toward automating AI infrastructure building!
Introducing our new work K-Search: LLM Kernel Generation via Co-Evolving Intrinsic World Model — a new paradigm for automated GPU kernel generation, achieving SoTA results.
🔍 Big insight:
Traditional methods treat LLMs as stochastic code generators inside heuristic loops — but this misses a key point: LLMs are powerful planners with rich domain priors.
🧠 Core idea:
K-Search uses the LLM itself as a co-evolving world model — one that plans + updates beliefs + guides search decisions based on experience.
📌 This decouples high-level strategy (intent) from low-level code implementation, allowing the optimizer to pursue multi-step transformations even when intermediate implementations don’t immediately improve performance.
📈 Key results:
🔥 Our discovered kernels are ~2.10× average speedup vs state-of-the-art evolutionary search across 4 FlashInfer kernels on H100/B200.
🔥 Up to 14.3× gain on complex Mixture-of-Experts (MoE) kernels.
🔥 State-of-the-art performance on GPUMode TriMul (H100) task — beating both automated and human solutions.
🙏 Acknowledgements
This work is developed in @BerkeleySky, w/ the amazing @ziming_mao, @profjoeyg, and @istoica05. We thank @DachengLi177, @MayankMish98, @randwalk0, @pgasawa, @fangz_zzu, and @tian_xia_ for helpful discussion and feedback.
We also thank the generous compute support from @databricks, @awscloud, @anyscalecompute, @nvidia, @Google, @LambdaAPI, and @MayfieldFund.
👨💻 GitHub: https://t.co/YJJ9SYvTvD
📄 arXiv: https://t.co/JtZDnZBkKM
Introducing our new work K-Search: LLM Kernel Generation via Co-Evolving Intrinsic World Model — a new paradigm for automated GPU kernel generation, achieving SoTA results.
🔍 Big insight:
Traditional methods treat LLMs as stochastic code generators inside heuristic loops — but this misses a key point: LLMs are powerful planners with rich domain priors.
🧠 Core idea:
K-Search uses the LLM itself as a co-evolving world model — one that plans + updates beliefs + guides search decisions based on experience.
📌 This decouples high-level strategy (intent) from low-level code implementation, allowing the optimizer to pursue multi-step transformations even when intermediate implementations don’t immediately improve performance.
📈 Key results:
🔥 Our discovered kernels are ~2.10× average speedup vs state-of-the-art evolutionary search across 4 FlashInfer kernels on H100/B200.
🔥 Up to 14.3× gain on complex Mixture-of-Experts (MoE) kernels.
🔥 State-of-the-art performance on GPUMode TriMul (H100) task — beating both automated and human solutions.
🙏 Acknowledgements
This work is developed in @BerkeleySky, w/ the amazing @ziming_mao, @profjoeyg, and @istoica05. We thank @DachengLi177, @MayankMish98, @randwalk0, @pgasawa, @fangz_zzu, and @tian_xia_ for helpful discussion and feedback.
We also thank the generous compute support from @databricks, @awscloud, @anyscalecompute, @nvidia, @Google, @LambdaAPI, and @MayfieldFund.
👨💻 GitHub: https://t.co/YJJ9SYvTvD
📄 arXiv: https://t.co/JtZDnZBkKM
🔥Modifying 2 lines of code and get your agentic serving/rollout up to 3.9x faster losslessly!
⚡️Say hello to ThunderAgent, a fast, simple, and program-aware agentic Inference System.
🥇 We propose a program abstraction to schedule all GPU and CPU resources, the first principled approach for distributed agentic inference and rollout.
🌐 Blog: https://t.co/PAcgTZzlhD
💻 Code: https://t.co/nr7XJj1L7B
📜 Paper: https://t.co/aCD6POzwkU
#AI #ThunderAgent #LLMAgent #Mlsys
1/n
Releasing the official SkyRL + Harbor integration: a standardized way to train terminal-use agents with RL.
From the creators of Terminal-Bench, Harbor is a widely adopted framework for evaluating terminal-use agents on any task expressible as a Dockerfile + instruction + test script.
This integration extends it: the same tasks you evaluate on, you can now RL-train on.
Blog: https://t.co/yDyId02UfH
🧵
(1/9) We built Endless Terminals: a fully autonomous pipeline that procedurally generates terminal tasks for RL training with no human annotation needed.
Simple PPO + scaled environments give consistent improvements on downstream tasks like Terminal Bench 2.0!





















![Aditya_Soni_8's tweet photo. Can we train code agents to search relevant locations in a codebase only using a terminal?
Introducing CodeScout: an effective RL recipe for code search 🚀
🏆 Outperforms 18x larger OSS LLMs
🔥 Comparable to proprietary LLMs
📈 SoTA on SWE-Bench Verified, Pro, & Lite
🧵 [1/N] https://t.co/zBZP6axzzy](https://pbs.twimg.com/media/HD3KHN2bsAAyzLQ.jpg)































