Agents are finding more vulnerabilities than ever. But it turns out there are gaps in existing vulnerability discovery. Over the past 90 days vs. a year ago, web vulnerabilities (XSS/SQLi/CSRF) are down 66% and memory safety exploitability is down 3.5x.
We built the Agentic Vulnerability Coverage Map to track it all, updated daily. Introducing the Berkeley Vulnerability Initiative: https://t.co/qiZ4eThb0n. ⤵️
We release Recon — a new approach to reasoning synthesis for user modeling.
The key insight: post-hoc rationalization ≠ reasoning.
We propose using action reconstruction as a scoring criterion for synthesized reasoning traces, yielding more causally faithful reasoning and improved downstream action prediction across user modeling tasks.
Paper and project page in 🧵
Excited to share that MAP has been selected for ✨ICML Oral✨
We look forward to sharing the insights in the paper with the community
And much much appreciations to everyone who participated in our study ❤️ MAP won’t be possible without your contribution to open science
Open-ended coding training data may no longer be the bottleneck: AI can scale open-ended tasks—and even outperform human-expert curation.
FrontierCS team is releasing FrontierSmith: a system for synthesizing open-ended coding problems at scale. Starting from closed-ended coding tasks, FrontierSmith mutates, filters, and builds runnable optimization environments for long-horizon coding agents. In our experiments, FrontierSmith data trains stronger models than human-curated open-ended data on FrontierCS and ALE-bench.
Blog: https://t.co/mhdDsBnfTQ
Paper: https://t.co/4CDVvNGZZ4
Code: https://t.co/90FjTjAjnv
Model: https://t.co/Mf5qalg4Ll
🚀 Excited to release mKernel: a set of fast multi-node, multi-GPU fused kernels.
💻 Code: https://t.co/y2WfdMVTfC
📝 Blog: https://t.co/wGomxmeRxr
mKernel fuses compute + communication into one persistent GPU kernel, covering both intra/inter-node with GPU-initiated communication.
Amazing team: @yangzhouy, Chon Lam Lao, Costin Raiciu, Scott Shenker, @istoica05
Learning from rich textual feedback (errors, traces, partial reasoning) beats scalar reward alone for LLM optimization. GEPA demonstrated this for context-space optimization (prompts and agent harnesses), delivering frontier results at a fraction of the cost of RL.
But context-only optimization is bounded by the base model's capability ceiling; weight updates can reach further.
Very excited about this new line of work on Fast-Slow Training (FST), which interleaves context and model weight optimization!
The idea is a clean division of labor between two interleaved loops:
🔹 Fast loop (context): GEPA reads rich rollout feedback updating the context layer. The context becomes a fast-updating scratchpad of what the model needs to know about this task, right now.
🔹 Slow loop (model parameters): RL updates the model's parameters conditioned on the evolving context. Because the prompt already carries task-specific nuances, the model parameters are freed from absorbing them and focus on what actually generalizes across tasks and pushes the frontier.
⦁ 3× more sample-efficient than RL on math, code, and physics reasoning
⦁ ~70% lower KL divergence from base at matched accuracy
⦁ Plasticity preserved: FST checkpoints respond better to additional RL on new tasks than RL-only ones
⦁ Continual learning across changing tasks (HoVer → CodeIO → Physics) where RL stalls the moment the task switches
FST is a direction towards:
⦁ Addressing RL's pain points: entropy collapse, sparse rewards, long-horizon exploration
⦁ Providing a clean channel for rich feedback into weight updates
⦁ Demonstrating model-harness co-evolution
⦁ Discovery: Using fast context updates for broad exploration, while leveraging a continually improving model.
Check out the full thread below:
1/ Thrilled to introduce T³: a corpus for RAG over reasoning tasks, built from thinking traces.
We show that surprisingly RAG can improve reasoning— with the right corpus.
Rag with Transformed Thinking Traces T³ gain by up to 43.9% on AIME 2025-2026.
🔗 https://t.co/9GPxKnszte 🧵
Today, we’re releasing Continual Learning Bench 1.0: the first, realistic benchmark for measuring how AI systems can improve in online settings.
Benchmarks today assume models are stateless. Each example is independent, and once a system finishes a task, it moves on as if nothing happened.
But deployed AI systems should learn from experience. We tested 10+ frontier systems against novel, expert-validated tasks and find there’s still plenty of headroom for learning. (1/n)
Agent harness is as important as the model for cybersecurity.
$300 in compute, 9 OSS-Fuzz projects, 14 security issues and 5 CVEs.
The key lesson: you don’t need a secret model to find real security issues. You need an effective, affordable, reliable harness.
5 takeaways 🧵
Excited to announce that FrontierCS has been accepted to ICML 2026! 🚀
We are scaling our open-ended task set to 250 tasks (100 new tasks in 2026 Q1🔥), featuring long-horizon agent settings in Harbor and integration into real-world human contests. More exciting updates to come! Huge thanks to all our collaborators.
#ICML2026 #AI #MachineLearning
Excited to share: MAP has been accepted as 🌟 ICML Spotlight 🌟
We hope MAP can provide data-driven insights that help the communities to work on various under-explored research directions around agent systems!
Huge thanks & congrats to my amazing co-authors. See you all at Seoul! 🫡
What if one person could run a unicorn company?
Today we're open-sourcing OMAR — a TUI that lets a single engineer orchestrate hundreds of AI coding agents in deep, recursive hierarchies.
Built at Berkeley. Powered by tmux.
https://t.co/EPjIRCJRj7 🧵
Would you trust an AI agent to negotiate on your country's behalf at the G20?
Real coordination is long-horizon, asymmetric, and non-binding; current multi-agent evaluations miss this.
We build Cooperate to Compete (C2C): a testbed for LM agents coordinating with rivals. 🤝🔪🎭
Congratulations to Matei Zaharia on being awarded the ACM Prize in Computing! His development of open-source systems helped enable large-scale machine learning, analytics and AI at a global scale.
@matei_zaharia@UCBerkeley
🔗 Read more: https://t.co/42jdeVI2A3
🎯 One Year of AI-Driven Research at Berkeley
[ADRS Blog #20] For the past year at Berkeley, we have been working on automating discovery with AI. In our blog post this week, we provide an overview of these efforts: the key problems we’re tackling, the frameworks and solutions we’ve built so far, and how these efforts fit into a broader vision for AI-driven scientific discovery.
✍️ Read the blog: https://t.co/IuusXWz5at
📖 ADRS Blog Series: https://t.co/UxujLFWX8b
Introducing M²RNN: Non-Linear RNNs with Matrix-Valued States for Scalable Language Modeling
We bring back non-linear recurrence to language modeling and show it's been held back by small state sizes, not by non-linearity itself.
📄 Paper: https://t.co/AS8e2tNrRa
💻 Code: https://t.co/LMvBcI22Du
🤗 Models: https://t.co/NCmjrpNriq
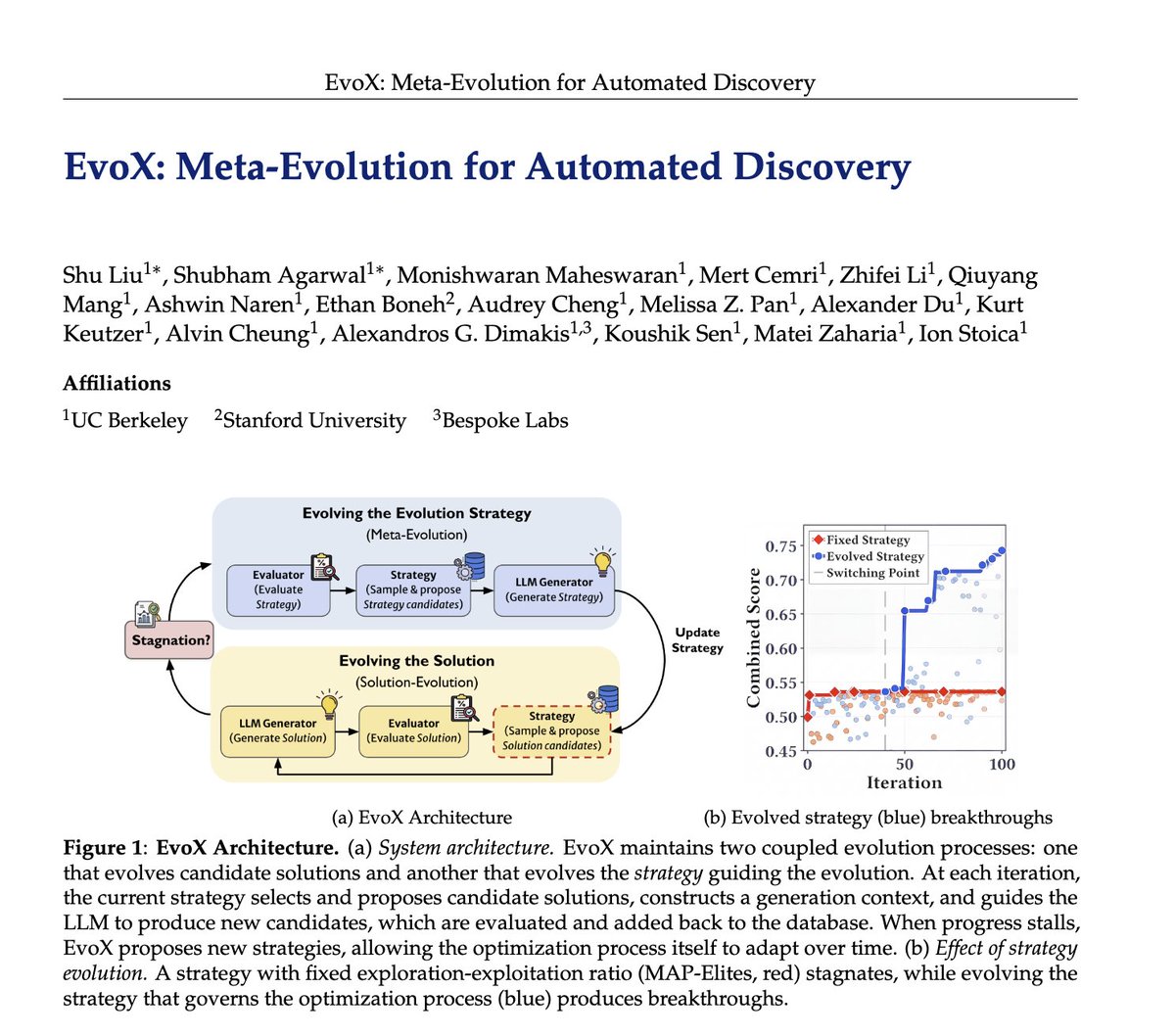
Researchers spend hours and hours hand-crafting the strategies behind LLM-driven optimization systems like AlphaEvolve: deciding which ideas to reuse, when to explore vs exploit, and what mutations to try.
🤖But what if AI could evolve its own evolution process?
We introduce EvoX, a meta-evolution pipeline that lets AI evolve the strategy guiding the optimization. It achieves high-quality solutions for <$5, while existing open systems and even Claude Code often cost 3-5× more on some tasks.
Across ~200 optimization problems, EvoX delivers the strongest overall results: often outperforming AlphaEvolve, OpenEvolve, GEPA, and ShinkaEvolve on math and systems tasks, exceeding human SOTA, and improving median performance by up to 61% on 172 competitive programming problems. 👇
@karpathy Very nice results and great project!
Sharing some of our experience with similar agentic frameworks at UC Berkeley:
ADRS blog series: https://t.co/zPgAVq8Y8X
GEPA: https://t.co/48xGJPmqnZ
KISS: https://t.co/QwRug6JLz5
AlphaEvolve is closed-source. We release 🌟SkyDiscover🌟, a flexible, modular open-source framework with two new adaptive algorithms that match or exceed AlphaEvolve on many benchmarks and outperform OpenEvolve, GEPA, and ShinkaEvolve across 200+ optimization tasks.
Our new algorithms dynamically adapt their search strategy, and can even let the AI optimize its own optimization process on the fly!
Results:
📊 +34% median score improvement on 172 Frontier-CS problems.
🧮 Matches/exceeds AlphaEvolve on many math benchmarks
⚙️ Discovers system optimizations beyond human-designed SOTA
🧵👇
We identified an issue with the Mamba-2 🐍 initialization in HuggingFace and FlashLinearAttention repository (dt_bias being incorrectly initialized).
This bug is related to 2 main issues:
1. init being incorrect (torch.ones) if Mamba-2 layers are used in isolation without the Mamba2ForCausalLM model class (this has been already fixed: https://t.co/oahfxjIsKb).
2. Skipping initialization due to meta device init for DTensors with FSDP-2 (https://t.co/hLC8nnQFc3 will fix this issue upon merging).
The difference is substantial. Mamba-2 seems to be quite sensitive to the initialization.
Check out our experiments at the 7B MoE scale: https://t.co/n8iuUICRux
Special thanks to @kevinyli_, @bharatrunwal2, @HanGuo97, @tri_dao and @_albertgu 🙏
Also thanks to @SonglinYang4 for quickly helping in merging the PR.

































![ai4research_ucb's tweet photo. 🎯 One Year of AI-Driven Research at Berkeley
[ADRS Blog #20] For the past year at Berkeley, we have been working on automating discovery with AI. In our blog post this week, we provide an overview of these efforts: the key problems we’re tackling, the frameworks and solutions we’ve built so far, and how these efforts fit into a broader vision for AI-driven scientific discovery.
✍️ Read the blog: https://t.co/IuusXWz5at
📖 ADRS Blog Series: https://t.co/UxujLFWX8b](https://pbs.twimg.com/media/HE7T0mfb0AAWfZA.png)