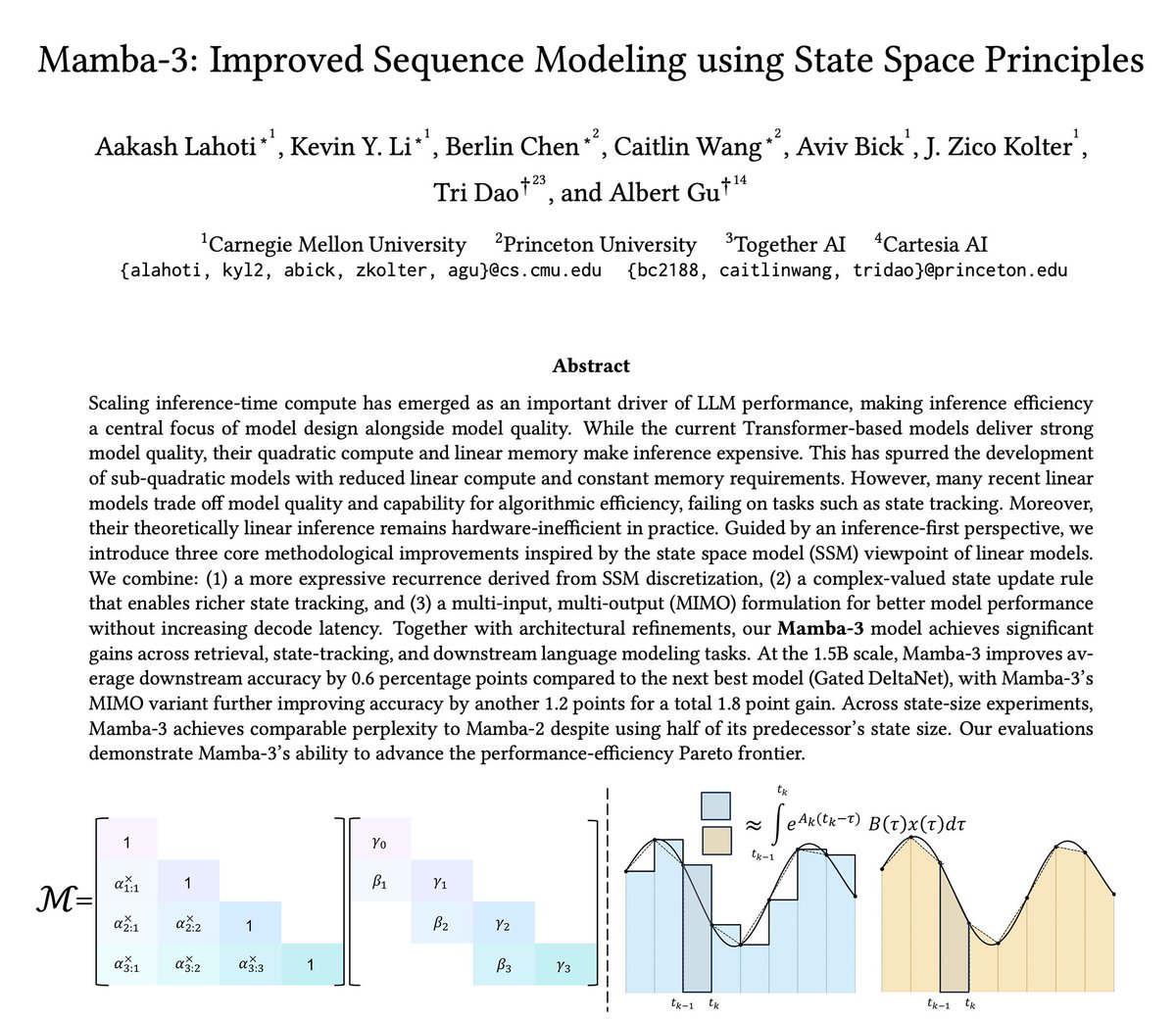
The newest model in the Mamba series is finally here 🐍
Hybrid models have become increasingly popular, raising the importance of designing the next generation of linear models.
We've introduced several SSM-centric ideas to significantly increase Mamba-2's modeling capabilities without compromising on speed. The resulting Mamba-3 model has noticeable performance gains over the most popular previous linear models (such as Mamba-2 and Gated DeltaNet) at all sizes.
This is the first Mamba that was student led: all credit to @aakash_lahoti@kevinyli_@_berlinchen@caitWW9, and of course @tri_dao!
Our new model Ink-2 tops AA's leaderboard for streaming speech-to-text!
Ink-2 comes with plenty of features optimized for real-time voice agents. With top-class models for both TTS and STT, the team at @cartesia keeps pushing the frontier of models for interactive intelligence.
Cartesia Ink-2 debuts as #1 for accuracy on the brand-new streaming speech-to-text leaderboard from @ArtificialAnlys! We designed Ink-2 from the ground up for voice agents - with low latency, eager transcripts, and semantic endpointing.
Today, @MichaelElabd, @QuantumArjun, and I are excited to announce Trajectory.
We are a research lab and product company building the platform for Continual Learning.
Our platform unlocks the signal already sitting in product usage, so companies can continuously post-train large-scale agentic models that outperform the frontier. @trajectorylabs
We’ve raised $15M from @Conviction, @BessemerVP, @radicalvcfund, @jeffdean, @drfeifei and more.
We’re partnering with some of the best AI-native companies: @ClayRunHQ@Harvey, @DecagonAI, @mercor_ai, @RogoAI to power their agentic systems, some of which we are already in production with.
We’ve brought together a world class research team from DeepMind, OpenAI, Apple, Meta Superintelligence, Amazon AGI, Scale AI, and an elite product team from Stripe and Figma.
AI will never again start on day one. Every correction, every retry, every edit will make products smarter. This is Continual Learning.
Extremely proud of the team @cartesia for launching Sonic 3.5, which sets a new state of the art for TTS
I personally led the technical direction of this model; we built it ground up from first principles, and it contains multiple non-trivial ideas that differ substantially from anything we’ve seen in the literature. It’s been very gratifying to see research bets play out and the strong research team at Cartesia continue to grow!
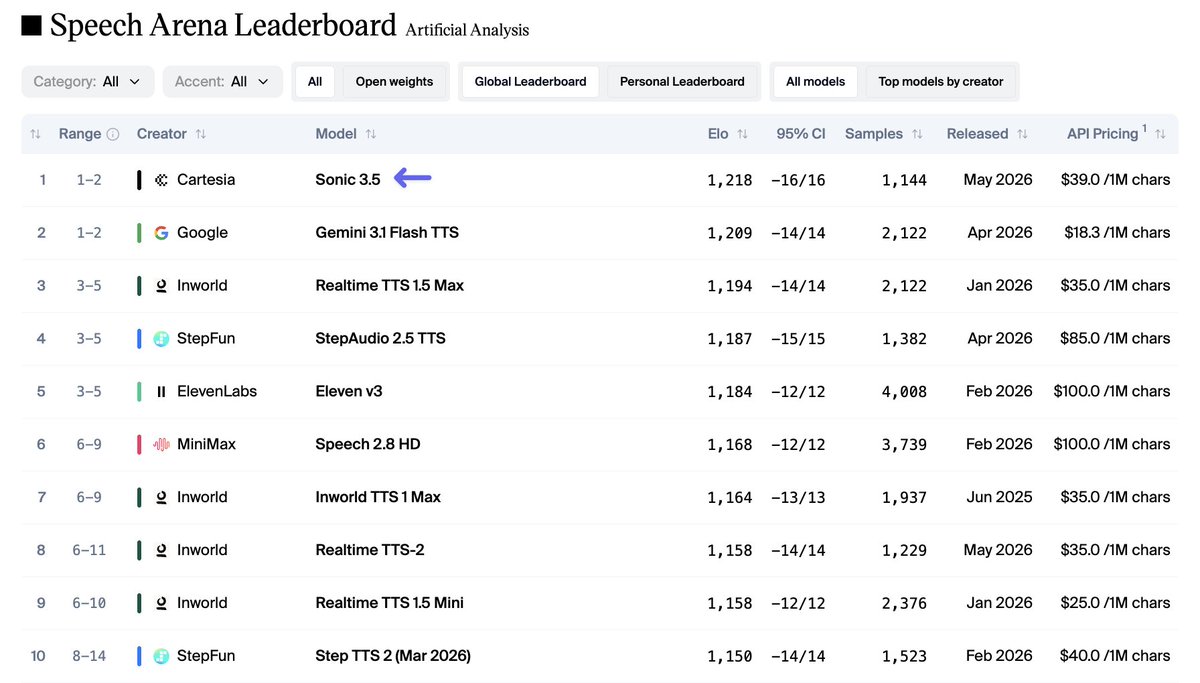
Cartesia’s Sonic-3.5 takes the #1 spot on the Artificial Analysis Speech Arena Leaderboard, surpassing Inworld Realtime TTS 1.5 Max and Google’s Gemini 3.1 Flash TTS
Sonic-3.5 is the latest TTS model from @cartesia . It supports 42 languages, including 9 Indian languages, with 500+ voices available out of the box. The model has been highly preferred among voters in the TTS Arena, with its demonstrated naturalness and accurate transcript following.
Key takeaways:
➤ Quality: Sonic-3.5 has an Elo score of 1,218 (+16/-16) based on 1,144 arena appearances, placing it ahead of Inworld Realtime TTS 1.5 Max at 1,194 and Gemini 3.1 Flash TTS at 1,209
➤ Pricing: Sonic-3.5 is priced at $39/1M characters, a premium compared to Gemini 3.1 Flash TTS at $18.3/1M characters, and Inworld Realtime TTS 1.5 Max at $35/1M characters
➤ Speed: 105.5 characters per second, compared to 205 characters per second for Inworld Realtime TTS 1.5 Max and 26.3 characters per second for Gemini 3.1 Flash TTS
See more details and listen to samples below 🧵
After some mathematical rewrite, turns out all of transformer is a series of gemm + epilogue. Given a few optimized primitives, LLMs (and novice humans) can write speed-of-light kernels for all transformer ops!
In SuperBPE we found: as tokenizer compression increases, the compute-optimal ratio of train tokens to model params decreases — and remarkably, corresponds to the same underlying ratio of train *bytes* / param! Our new work makes it official: scaling laws depend on compression.
Attention @arxiv authors: Our Code of Conduct states that by signing your name as an author of a paper, each author takes full responsibility for all its contents, irrespective of how the contents were generated. 1/
Higher-Order Linear Attention Models Are RNNs/SSMs:
Generalizing State-Space Duality to higher-order linear attention.
It’s getting wild.
https://t.co/vUBN3nDFMy
Introducing a new sequence model Raven which pushes the boundary of fixed-state-size sequence models!
Raven bridges popular linear-time models with constant state capacity, like SSMs and sliding window attention (SWA). Like SWA, its state is a finite set of slots; unlike SWA, Raven learns to selectively choose which slots to update with each new token it caches. This is a much more principled update mechanism that leads to dramatically better retrieval abilities than prior linear models.
I personally don't think SWA is a very principled model - but it's convenient and works well empirically - and am most excited to see Raven be used as a strictly better drop-in replacement. More broadly the framework it develops hopefully introduces more ideas to combine the strengths of SSM-like and attention-like models.
This work was led by @rshia_afz and @avivbick
1/ SSMs struggle on recall benchmarks due to their fixed-size state. But are current models actually storing context “wisely”?
Introducing Raven 🐦⬛, the first SSM with selective memory allocation! Raven achieves SOTA performance on recall-heavy tasks with the highest length generalization, extending up to 16× beyond its training sequence length. Raven is a strict upgrade over SWA in the way it stores past context!
This is the most elegant model I’ve been involved in designing so far shoutout to @avivbick and @_albertgu for their trust and amazing work!
Check out how Raven bridges between SWA and SSM👇
SSMs fail on recall tasks they have the capacity to solve. The two dominant approaches today, SSMs and sliding-window attention, both lack persistence: memory either decays over time or gets evicted.
We built Raven to fix this, surpassing all prior linear models even at 16× their training sequence length. 🧵🐦⬛
27x faster Attention Residuals!!! 🚀
We implemented Block AttnRes as a pip-installable package.
!pip install flash-attn-res
No annoying kernel nonsense.
No compile/autograd plumbing.
Call it like a regular PyTorch op.
It just works.
Methodology:
🔹 fused triton kernels
🔹 batched attention over residual blocks
🔹 online-softmax merge
🔹 flash attention-style split-KV reduction
Thanks @LLMenjoyer and @cartesia for the support and guidance✌️
Excited to announce that dnaHNet has been accepted as an ICML 2026 Spotlight paper!
Very grateful to my coauthors @victor_ljz and team, plus our remarkable supervisors @_albertgu and @genophoria.
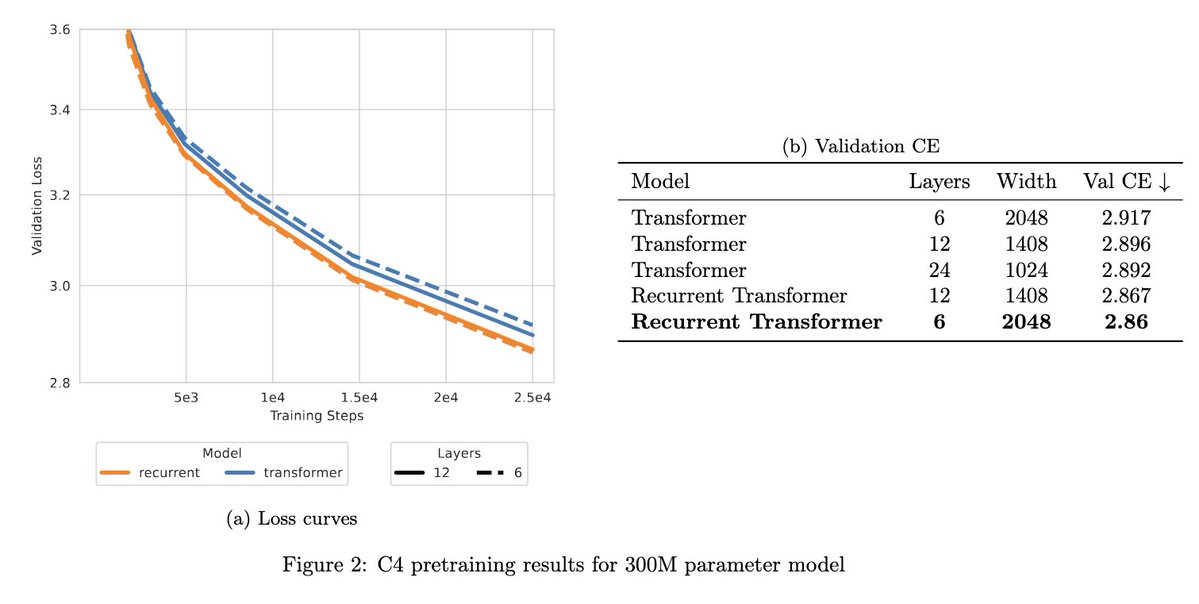
1/8 Introducing Recurrent Transformer (RT). At 300M params, RT improves validation CE over standard Transformers. The best RT model is only 6 layers, but wider at 2048 — beating deeper 12- and 24-layer Transformers by trading depth for width.
I am in Rio for #ICLR2026 🇧🇷
@fluorane@_albertgu and I will be presenting H-Net at [Pavilion3 P3-#1015] 3:15-5:45 today (Thursday). Stop by our poster to see why we’re so excited about the future of H-Net!
I will also be happy to talk to new people over the week. Let me know if you‘d like to grab a coffee, DMs open
We're open-sourcing FlashKDA — our high-performance CUTLASS-based implementation of Kimi Delta Attention kernels. Achieves 1.72×–2.22× prefill speedup over the flash-linear-attention baseline on H20, and works as a drop-in backend for flash-linear-attention.
Explore on github: https://t.co/sf4UohXDWY
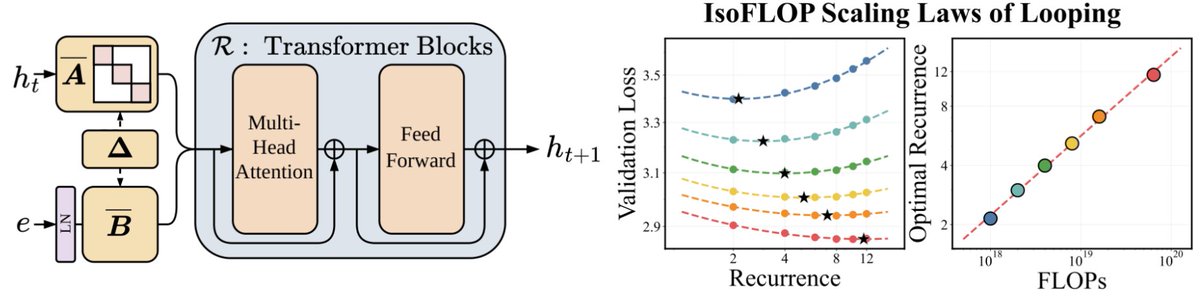
a dynamical systems point of view, which looks like an SSM applied along the residual stream, informs more principled ways to scale looped architectures
We’ve been thinking a lot about scaling laws, wondering if there is a more effective way to scale FLOPs without increasing parameters.
Turns out the answer is YES – by looping blocks of layers during training. We find that predictable scaling laws exist for layer looping, allowing us to use looping to achieve the quality of a Transformer twice the size.
Our scaling laws suggest that for a fixed parameter budget, data and looping should be increased in tandem!
🧵👇