vLLM has grown to 2000+ contributors scale with a diverse community of model, hardwares, and applications. I see @vllm_project on the path of becoming the world's inference engine and @inferact to accelerate AI progress. We cannot be more excited about the road ahead.
Today, we're proud to announce @inferact, a startup founded by creators and core maintainers of @vllm_project, the most popular open-source LLM inference engine.
Our mission is to grow vLLM as the world's AI inference engine and accelerate AI progress by making inference cheaper and faster.
The Challenge
Inference is not solved. It's getting harder.
Models grow larger. New architectures proliferate: mixture-of-experts, multimodal, agentic. Every breakthrough demands new infrastructure. Meanwhile, hardware fragments: more accelerators, more programming models, and more combinations to optimize.
The capability gap between models and the systems that serve them is widening. Left this way, the most capable models remain bottlenecked and with full scope of their capabilities accessible only to those who can build custom infrastructure. Close the gap, and we unlock new possibilities.
And the problem is growing. Inference is shifting from a fraction of compute to the majority: test-time compute, RL training loops, synthetic data.
We see a future where serving AI becomes effortless.
Today, deploying a frontier model at scale requires a dedicated infrastructure team. Tomorrow, it should be as simple as spinning up a serverless database. The complexity doesn't disappear; it gets absorbed into the infrastructure we're building.
Why Us
vLLM sits at the intersection of models and hardware: a position that took years to build.
When model vendors ship new architectures, they work with us to ensure day-zero support. When hardware vendors develop new silicon, they integrate with vLLM. When teams deploy at scale, they run vLLM, from frontier labs to hyperscalers to startups serving millions of users. Today, vLLM supports 500+ model architectures, runs on 200+ accelerator types, and powers inference at global scale. This ecosystem, built with 2,000+ contributors, is our foundation.
We've been stewards of this engine since its first commit. We know it inside out. We deployed it at frontier scale—in research and in production.
Open Source
vLLM was built in the open. That's not changing.
Inferact exists to supercharge vLLM adoption. The optimizations we develop flow back to the community. We plan to push vLLM's performance further, deepen support for emerging model architectures, and expand coverage across frontier hardware. The AI industry needs inference infrastructure that isn't locked behind proprietary walls.
Join Us
Through the open source community, we are fortunate to work with some of the best people we know. For @inferact, we're hiring engineers and researchers to work at the frontier of inference, where models meet hardware at scale. Come build with us.
We're fortunate to be supported by investors who share our vision, including @a16z and @lightspeedvp who led our $150M seed, as well as @sequoia, @AltimeterCap, @Redpoint, @ZhenFund, The House Fund, @strikervp, @LaudeVentures, and @databricks.
- @woosuk_k, @simon_mo_, @KaichaoYou, @rogerw0108, @istoica05 and the rest of the founding team
KV Cache re-use is the most important thing for agentic rollouts. We've integrated Mooncake Store into prime-rl with vLLM, you can now use it as a drop-in replacement for native CPU/Disk offloading, giving you cross-node prefix cache reuse to make your agents go brrr🚀
🚀 We're excited to partner with @NVIDIARTXSpark pushing local AI agents forward on DGX Spark + RTX!
This is exactly the direction explored in @Inferact's hands-on #vLLM + #DGXSpark blog—serving large NVFP4 models locally on NVIDIA DGX Spark. vLLM is an ideal fit, bringing streaming responses, paged KV cache, runtime tuning, and Prometheus metrics into a familiar serving workflow.
To put it to the test, the team built a live 20 Questions game—using DGX Spark as the local inference endpoint and vLLM telemetry to track real serving behavior.
Key takeaways:
🧠 DGX Spark brings large-model inference closer to developers
⚙️ Unified memory makes serving config especially important
📦 NVFP4 MoE models are a strong fit for Spark's local inference profile
📊 vLLM gives developers the tools and metrics to understand real serving behavior
Try it on your own Spark 👇
https://t.co/bWkBfpKf3M
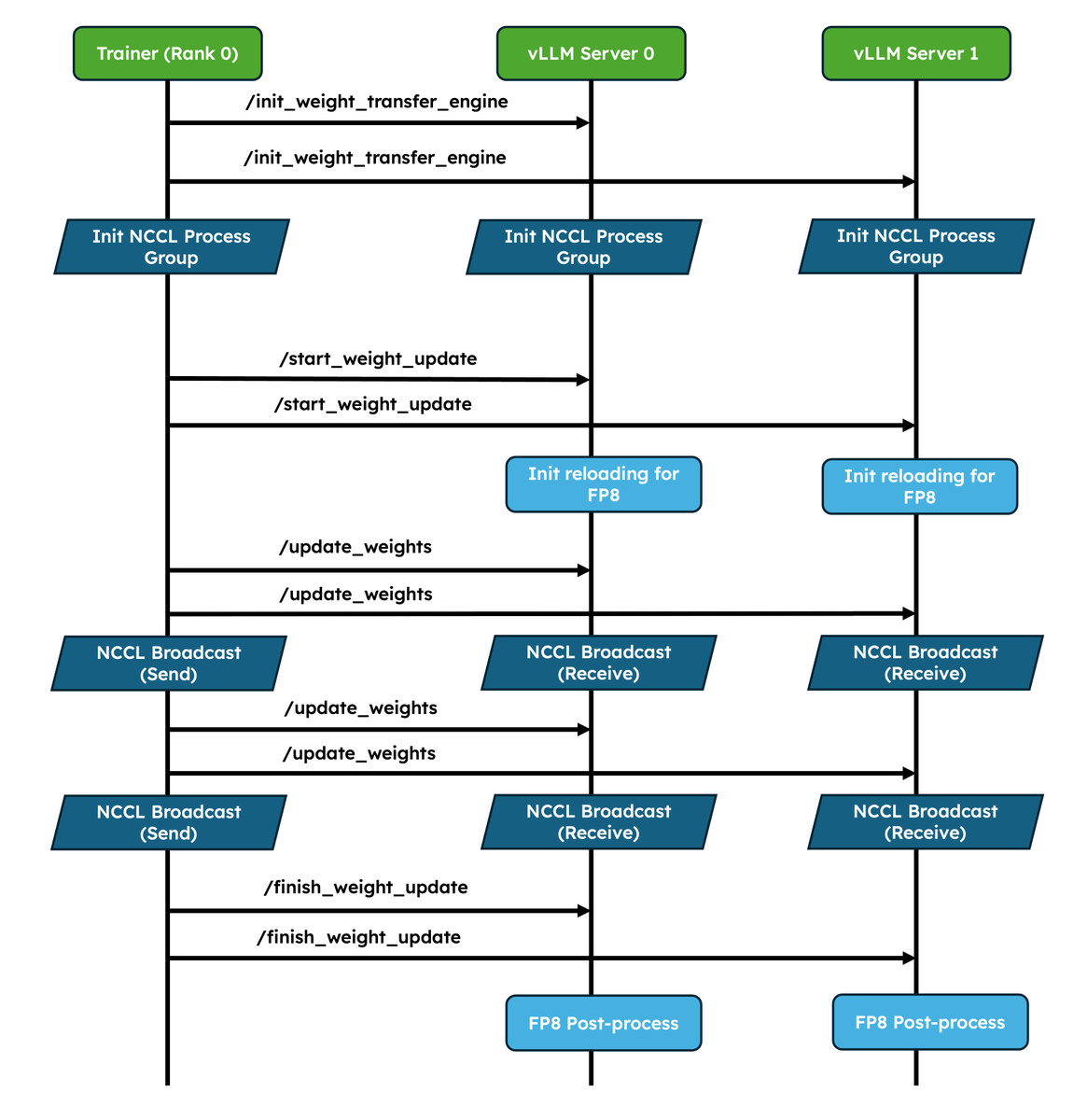
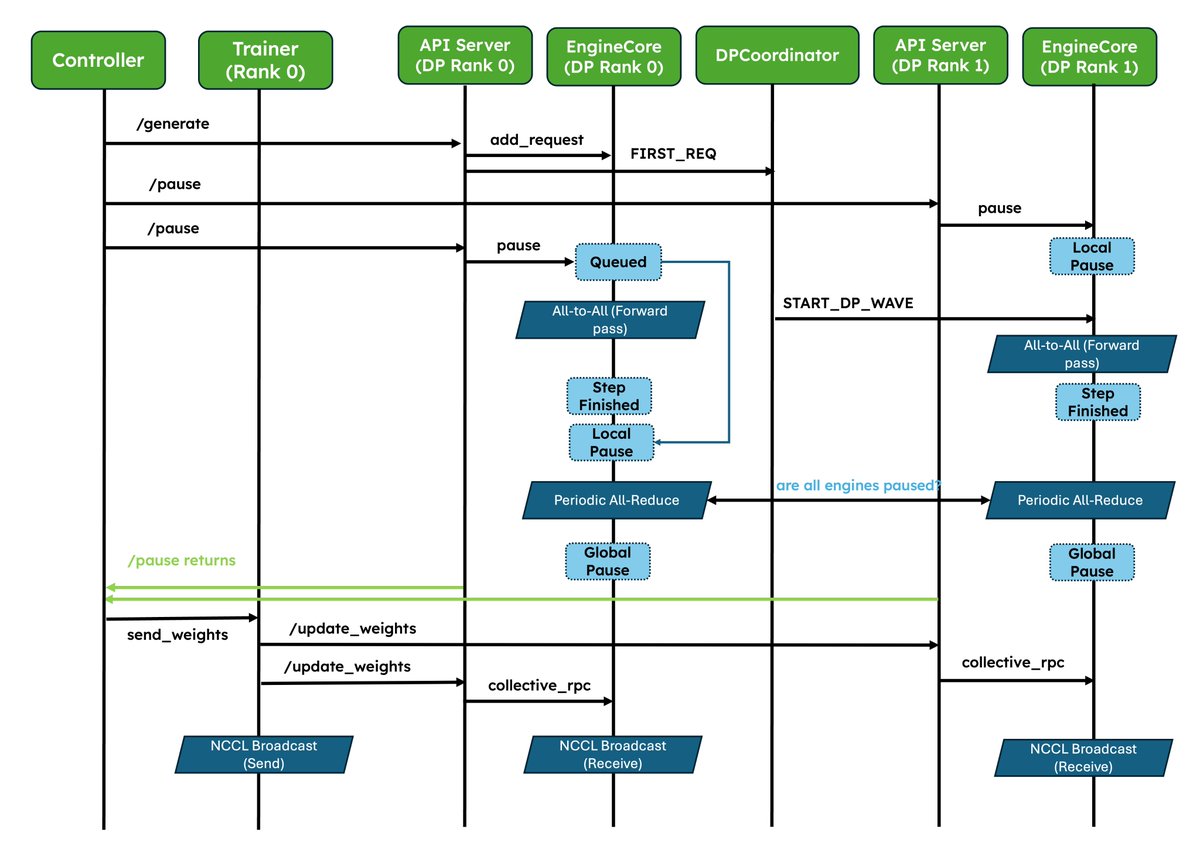
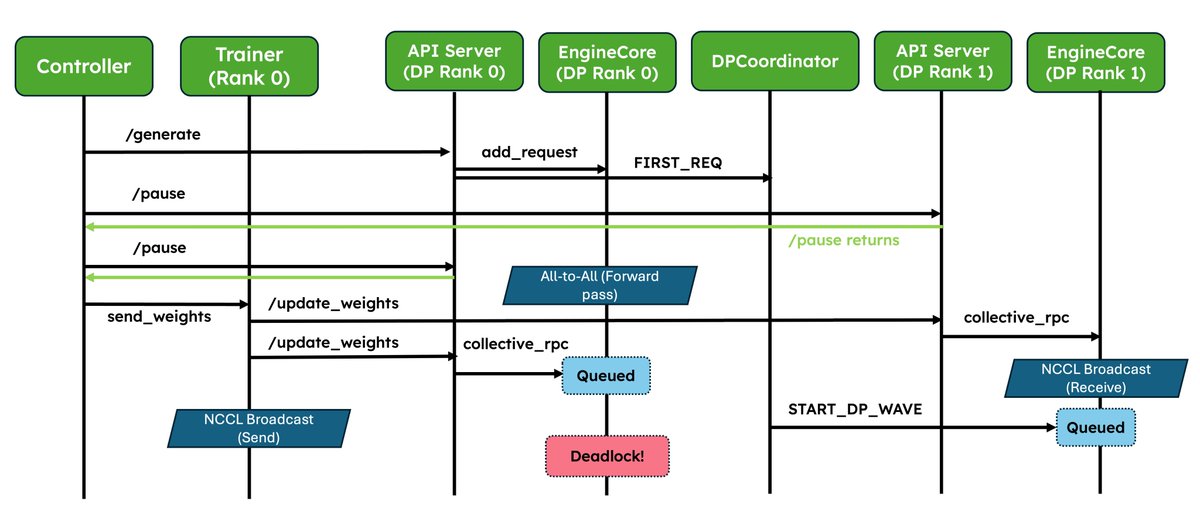
We've shipped two major upgrades for RL✨!
1. Native weight syncing APIs: Standardizes weight transfer, provides optimized implementations for NCCL and CUDA IPC out of the box, and also lets frameworks easily bring their own.
2. Improved pause/resume for Async RL: Careful coordination between DP ranks so that engines don’t deadlock. Validated at scale in P/D, wide-EP setups!
In collaboration with @anyscalecompute, @NovaSkyAI, and @RedHat.
More and more RL frameworks are using vLLM as the default for inference, details in the blog 👇
https://t.co/LLmL8zJLtR
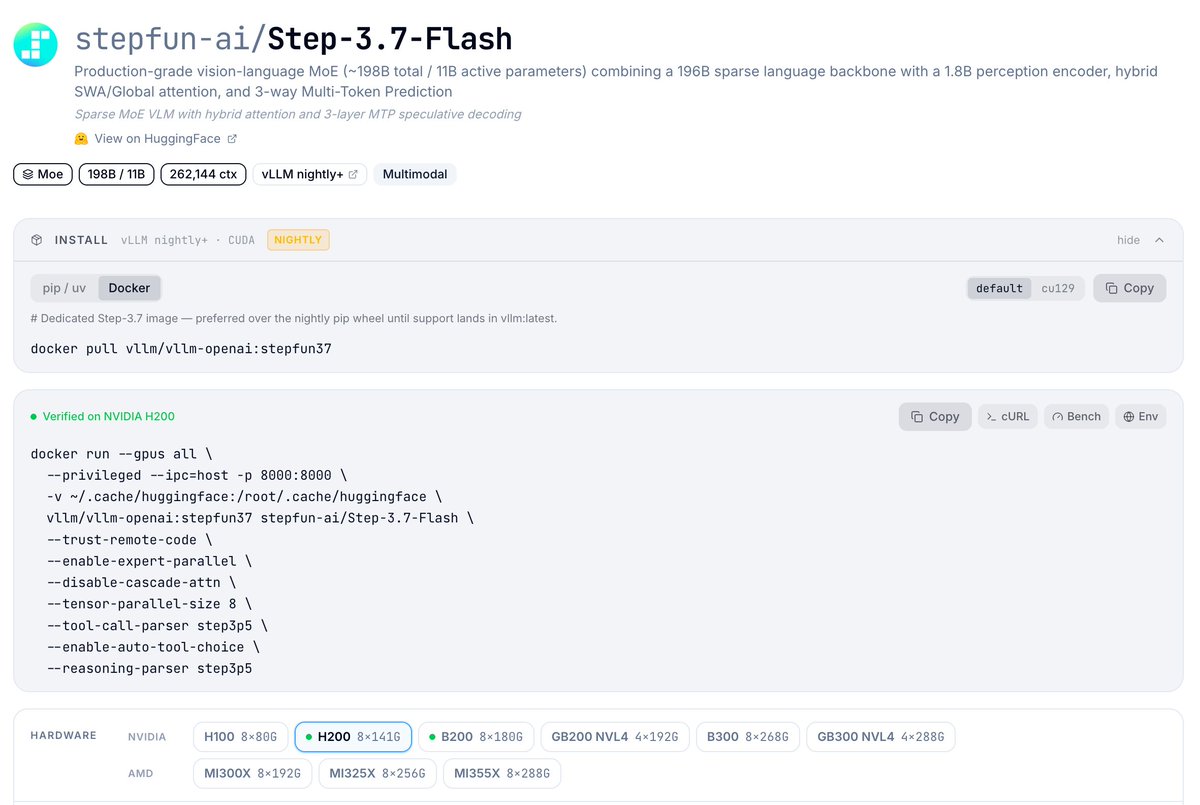
🎉 Congrats to @StepFun_ai on releasing Step-3.7-Flash, with day-0 support in vLLM.
- 198B sparse MoE vision-language model, ~11B active params per token, native image + text input
- 256K context window for long docs, multi-file repos, and dense visual interfaces
- FP8 and NVFP4 quantized weights ready to go
built-in MTP speculative decoding, native tool calling, and reasoning parsing. Serve it now!
🔗 https://t.co/XEqSqFEmVt
prime-rl is vLLM native - we are using vLLM as our engine of choice and the work the team does is legit amazing. It powers our large scale runs and we couldn't be happier with the collaboration we're having with the vLLM team 🙏
Amazing work! More and more RL frameworks are using vLLM as default. @vllm_project along with @anyscalecompute and @NovaSkyAI revamped weight syncing and improved wide-ep deployment for rollout!
Excited to share some of our work on improving vLLM for RL!
A number of RL frameworks, including SkyRL, use vLLM for inference, and we’ve noticed some common problems:
1. Weight syncing between training and inference is implemented in an ad-hoc fashion and duplicated across frameworks.
2. Asynchronous RL is prone to break at scale, especially in P/D and DPEP deployments.
We’ve been working on improving both!
Today, EAGLE powers some of the industry’s most formative AI infrastructure companies and teams.
With EAGLE 3.1, we’re taking another major step toward delivering a core piece of the fastest possible inference stack that exists, open to all.
By improving hidden-state feedback stability and mitigating attention drift across deeper decoding steps, EAGLE 3.1 significantly improves long-context acceptance length and serving robustness in real-world inference environments.
We are thrilled to collaborate with vLLM @vllm_project and TorchSpec @lightseekorg on advancing the next generation of inference acceleration infrastructure.
🦀 The Rust frontend is officially merged into vLLM!
As GPUs get faster, the frontend has become a real share of CPU time. The new Rust frontend is a drop-in alternative to the Python API server — same engine, same ZMQ boundary. Opt in with VLLM_USE_RUST_FRONTEND=1.
Early numbers: on a preprocess-heavy workload, ~837 req/s vs ~162 req/s for default Python — ~5x in a single process.
A few design choices we're excited about:
• Layered crates with clear boundaries
• Stream-native pipeline — non-streaming for free
• Builds on stable Rust
Huge thanks to @BugenZhao from @inferact for introducing the work at @PyTorch Meetup Singapore.
https://t.co/Tw8PoIjbH9
Elastic parallelism for wideEP deployments is critical for operating large-scale inference systems efficiently. What started as an idea at a Dynamo after-party nearly a year ago is now finally available to everyone.
Congratulations @nvidia dynamo nixl and @vllm_project team!
Giving a talk on behalf of @vllm_project about open source at #MLSys 2026 tomorrow and will be around in Bellevue May 18-21. https://t.co/SEyl6Y5HbZ
The @inferact crew will be here too with a booth! Come say hi!🤗
We're onto Inferact's second office this year! Yesterday, we finally broke it in with an office warming.
It's amazing to see how far we've come. The vLLM ecosystem has been growing at lightning pace, and we've been lucky to scale alongside it: helping teams serve inference faster, cheaper, and at scale.
Thank you to everyone who made it out yesterday — customers, partners, friends, and the whole Inferact team. It meant a lot to celebrate this milestone together.
We're hiring across all teams. If you want to join one of the fastest-growing AI infra companies and power the next generation of AI, check out our careers page or DM us.
Excited for many more office warmings to come!
Great work at @baseten running vLLM-Omni in production — open-source, production-grade, cost-efficient omni-modal serving 🎙️
Multi-stage audio, streaming multi-modal, real-time TTS — workloads where closed-source APIs have been the default.
→ https://t.co/c0J0nlXrFb
We're onto Inferact's second office this year! Yesterday, we finally broke it in with an office warming.
It's amazing to see how far we've come. The vLLM ecosystem has been growing at lightning pace, and we've been lucky to scale alongside it: helping teams serve inference faster, cheaper, and at scale.
Thank you to everyone who made it out yesterday — customers, partners, friends, and the whole Inferact team. It meant a lot to celebrate this milestone together.
We're hiring across all teams. If you want to join one of the fastest-growing AI infra companies and power the next generation of AI, check out our careers page or DM us.
Excited for many more office warmings to come!
We serve Qwen3-TTS on vLLM-Omni at $3 per 1M characters. That's 90% lower in cost than comparable closed-source TTS APIs.
Our engineers optimized a single-replica serving stack to get there. Details on the optimized stack and cost per concurrent stream here.
THE MORE U BUY, THE MORE U SAVE: By ganging up multiple B200 8-GPU machines together over RoCEv2 CX-7 ethernet with Tomahawk switches with an inference optimization called PD disaggregation, the per GPU token throughput increases up to 7x. By increasing per GPU token throughput by up to 7x, this decreases cost per million tokens by up to 7x also.
Great work to @inferact & @vllm_project for building this amazing OSS engine & for @NVIDIADC @KranenKyle for building dynamo inference orchestrator. More improvements to disagg b200 perf to come!
vLLM tops the Artificial Analysis leaderboard 🎉
vLLM tops @ArtificialAnlys on DeepSeek V3.2 and ranks among the top deployments of MiniMax-M2.5 and Qwen 3.5 397B.
The leading deployments of these models are now open source.
How each result was built:
🔹 DeepSeek V3.2 — Aggressive op fusion across the attention path collapsed ~33 per-layer kernels down toward ~10.
🔹 MiniMax-M2.5 — Custom EAGLE3 draft trained against the target's own token distribution via TorchSpec, plus a custom QK-norm fusion for MiniMax's TP-aware attention.
🔹 Qwen 3.5 397B — Targeted fusions plus a QK-norm fix for Qwen's linear-attention path.
Every optimization is in vLLM main or on its way upstream.
Huge thank you to @inferact, @digitalocean, @nvidia, @RedHat_AI, and the vLLM community 🙏
Full breakdown 👇
https://t.co/MzxANVvhHQ