One of the new, buzzy jobs in Silicon Valley is the AI Forward Deployed Engineer (FDE), an engineer who is embedded within a client organization to help customize solutions, such as building and tuning agentic workflows that suit the client’s particular needs. I’ve heard from people who are wondering anew about the FDE career path since OpenAI and Anthropic started building new teams to place FDEs within client organizations.
The rise of FDEs for AI workloads is one way AI is creating new jobs (and why the jobpolcalypse narrative of upcoming job market collapse is false -- there will be many AI and non-AI jobs). However, I believe there will be far more AI Engineer jobs than FDEs, as I explain below.
The FDE role was pioneered about two decades ago by Palantir, which sent engineers to government locations to work on secure, air-gapped networks. In addition to having good technical skills, FDEs need communication skills and sometimes business skills. For example, they may need to speak with clients to understand their needs, formulate a strategy to prioritize projects, explain complex technology, and respectfully push back if a client asks for something unrealistic. They’re enjoying a resurgence because of the amount of work involved in taking an off-the-shelf LLM and building it into a custom agentic workflow that fits particular business needs.
However, I believe the number of AI Engineer jobs will be far larger. A company might accept a few FDEs to be embedded within its organization. But most companies will want far more of their own employees working on their projects. While my organizations do hire FDEs, we hire far more AI Engineers! Also, a common client concern is that it is hard to find vendor-neutral FDEs — they are, after all, there to deeply integrate a particular vendor’s product into a company. In this moment when it’s hard to predict which AI service will be the best one in a year’s time, optionality (the ability to pick whatever vendor turns out to fit best in the future) is very valuable. In contrast, letting FDEs tightly bind a company’s processes significantly reduces optionality.
Right now, I see surging demand for AI Engineers who can build software applications using AI software components (like LLM prompting, agentic frameworks, evals, etc.) and effectively use AI coding agents (like Claude Code, Codex, Antigravity CLI, and OpenCode). As the AI Engineer role matures, I expect it to fragment into more specialized roles, like the generic Software Engineer role from decades ago fragmented into frontend, backend, mobile, data engineering, devops, and so on.
What will be the future, specialized AI engineering roles? I don’t know. Perhaps there will be AI FDEs, LLMOps Engineers, Evals Engineers, AI Data Engineers, Harness Engineers, and other roles we don’t have names for yet. But for now, I see a lot of AI engineers who are generalists create a lot of value. Skilled AI Engineers are in very high demand! As our field continues to mature over the coming decade, I look forward to new specializations within AI Engineering that create even more job opportunities.
[Original text: The Batch newsletter]
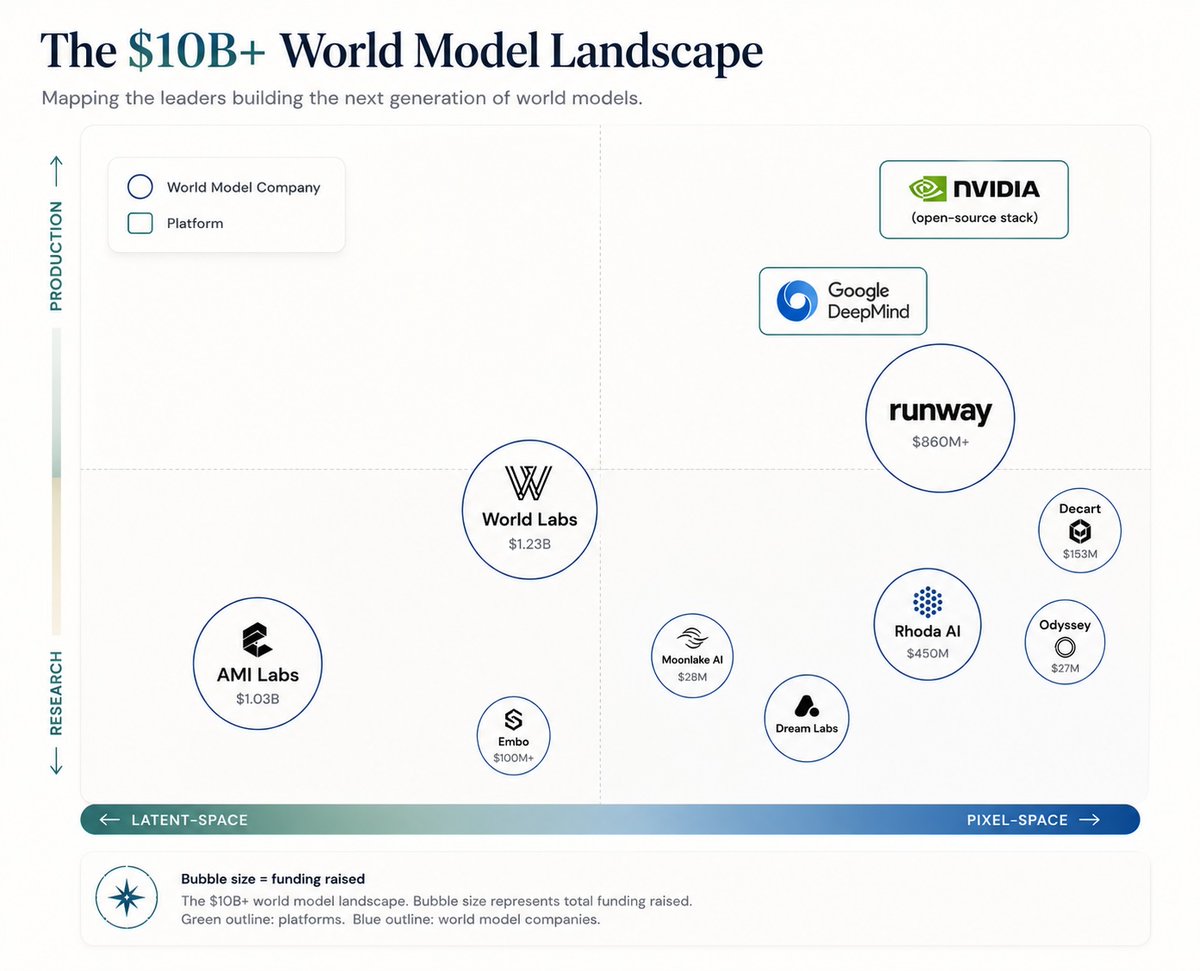
This is the single best read on World Models and one of the most important reads in AI.
$10B has flowed into "world models" in the last 18mos, from Yann LeCun to FeiFei Li. The promise is, like LLMs, world models will provide the data it takes to scale robotics foundation models, and solve robotics.
..but the word has been abused to mean one of many things.
This post unpacks:
– What 5 traits makes a world model?
– How do the different approaches stack up?
– What is it used for within and beyond robotics?
– Where is the opportunity?
– Citations to research, news and blog posts
Companies / products in the space include:
– BigCo products: Google Genie, Tesla Optimus, Nvidia DreamDojo, DreamZero, Microsoft Muse
– Pure world model: AMI Labs, World Labs, Runway, Rhoda, Decart, Spaitial, Odyssey, Embo, Dream Labs, OneWorld
– Robot foundation model cos: Skild, Physical Intelligence, Figure, Mind
Very likely one of the seminal technologies of the next decade.
Peter Thiel just put $140 million into a startup that wants to run AI inside giant steel orbs floating in the ocean. Almost half of America's AI data centers planned for this year have already been cancelled or delayed. The grid cannot handle them.
A single big AI data center uses as much electricity as a small city, around the clock. America was not wired for that. In America's biggest power market, which stretches from New Jersey to Illinois, the cost of reserving future power has jumped from $29 to $329 in two years. That is more than ten times higher. And if you order one of the giant transformers a data center needs to plug into the grid, you now wait up to four years to get it.
So a small Oregon company called Panthalassa raised the cash. Their hardware looks like a giant steel orb floating on the surface, with the rest of the body extending 80 meters down into deep water. Waves push water through internal channels to spin a turbine, and the electricity runs AI chips right there on the platform. Answers travel back to land by satellite. The company is now worth roughly $1 billion. Backers include John Doerr (an early Google and Amazon investor), Marc Benioff (Salesforce's founder), and Peter Thiel's own venture firm Founders Fund.
The second problem ocean-AI solves is heat. AI chips run scorching. Cooling them on land is so thirsty that a large data center drinks 5 million gallons of water a day, the same as a town of 50,000 people. Microsoft already proved the ocean fixes this. A few years back they sealed 864 servers inside a steel tube and sank it off the coast of Scotland. The cold seawater cooled them for free. They used zero water from any town, and the servers had 8 times fewer breakdowns than the same machines on land.
There is also nobody to argue with out at sea. Just last week, two companies pulled their plans to build data centers in Seattle because locals fought back. Those facilities alone would have eaten about a third of the city's daily power.
Of course, this could still fail. Saltwater eats steel. Big storms break things. Earlier wave-power companies have burned through hundreds of millions of dollars and never made it to commercial scale. Panthalassa's first real ocean test has not happened yet. Paying customers are not promised until 2027.
But the math has flipped. If grid power costs ten times what it did, the transformer arrives in four years, and the neighbors will not let you build, then floating computers in the open ocean stops looking ridiculous and starts looking like the only door still open.
Hamming's talk is so important that I reproduced it on my site. It's one of the only things on my site written by someone else.
https://t.co/kWvKdwIiOm
Urban planning models just crossed 90% accuracy using free map data anyone can edit.
A new paper builds a single deep learning pipeline that turns OpenStreetMap into a full urban intelligence system. Land use, buildings, traffic, and air quality all predicted together, not separately. 
Most studies treat these as isolated problems. One model for land use. Another for traffic. Another for pollution.
This one connects them.
The system fuses three data layers:
• OpenStreetMap for structure
• Satellite imagery for surface detail
• Environmental and demographic data for context 
Then assigns each task a specialised model:
• CNNs for land use
• U-Net for building footprints
• LSTMs for traffic
• Hybrid models for air quality 
Each model solves its own problem. The pipeline ties them into one view of the city.
The results are pretty strong:
• Land use classification: 91.6% accuracy
• Building detection: 94.0% accuracy
• Traffic prediction error: 3.6 vehicles per hour
• Air quality prediction error: 2.3 µg/m³ 
These sit at the upper end of current GeoAI benchmarks.
The improvement comes from integration.
OpenStreetMap gives topology.
Satellite data gives physical signals.
Environmental data gives dynamics.
Each fills gaps in the others.
That reduces ambiguity where models usually struggle. Mixed-use zones. Dense urban cores. Noisy or incomplete maps.
The system learns a more complete representation of the city.
The workflow is quite simple:
1.Collect multi-source data
2.Align and standardise it
3.Train task-specific models
4.Combine outputs into urban indicators 
Raw geodata in. Policy-relevant outputs out.
The implications are practical.
Traffic models identify congestion hotspots.
Land use maps reveal missing green space.
Building extraction supports infrastructure planning.
Air quality forecasts guide mitigation. 
All from largely open data.
The constraint is compute.
Training requires GPUs and careful preprocessing. Smaller cities may struggle to deploy this directly.
Data quality also matters. OpenStreetMap varies by location.
Even so, the direction is clear.
Urban planning is shifting from static GIS layers to integrated, predictive systems.
One pipeline. Multiple urban signals. Continuous updates.
Cities are becoming modelled environments, not just mapped ones.Urban planning models just crossed 90% accuracy using map data that anyone can edit.
A new paper builds a single deep learning pipeline that turns OpenStreetMap into a full urban intelligence system, predicting land use, buildings, traffic, and air quality together rather than treating them as separate problems. 
Most existing work fragments the city into isolated tasks. One model classifies land use. Another extracts buildings. A third forecasts traffic. This paper links them into a single system.
The key idea is simple. Combine three types of data that each see the city differently:
• OpenStreetMap provides structure such as roads, buildings, and land use
• Satellite imagery captures physical and spectral detail
• Environmental and demographic data add temporal and social context 
Each task is then handled by a model suited to its structure. CNNs for land use, U-Net for building footprints, LSTMs for traffic, and hybrid models for air quality. The novelty is that all outputs are combined into one coherent view of the city rather than analysed in isolation.
The performance is strong across the board. Land use classification reaches 91.6% accuracy. Building detection hits 94.0%. Traffic prediction errors fall to 3.6 vehicles per hour, and air quality prediction to 2.3 µg/m³. 
These results sit at the upper end of current GeoAI benchmarks, and the reason is not a single model improvement. It is the interaction between data sources.
OpenStreetMap encodes topology but misses detail. Satellite imagery captures detail but struggles with semantics. Environmental data adds dynamics but lacks spatial structure. When combined, each compensates for the others, reducing ambiguity in dense or mixed-use areas where models typically fail.
The workflow follows a clear pipeline. Multi-source data is collected, aligned, and standardised. Task-specific models are trained. Their outputs are then fused into multi-dimensional urban indicators that describe structure, function, mobility, and environment together. 
This produces something closer to a live model of the city rather than a static map.
The implications are practical. Traffic forecasts identify congestion hotspots. Land use maps reveal gaps in green space. Building extraction supports infrastructure planning. Air quality predictions guide mitigation strategies. 
All of this is built largely on open data.
People, listen to this. Posted by an actual climate scientist from IISC. Not a random 2 bit “aaj main climate specialist hoon” celeb who barely scored passing marks in science.
@GabbbarSingh Chinese Americans get huge benefits from the govt. if they return home from top Univs in the US. Not sure if it’s still there. I remember reading about this in Jack Ma’s biography.






















![AndrewYNg's tweet photo. One of the new, buzzy jobs in Silicon Valley is the AI Forward Deployed Engineer (FDE), an engineer who is embedded within a client organization to help customize solutions, such as building and tuning agentic workflows that suit the client’s particular needs. I’ve heard from people who are wondering anew about the FDE career path since OpenAI and Anthropic started building new teams to place FDEs within client organizations.
The rise of FDEs for AI workloads is one way AI is creating new jobs (and why the jobpolcalypse narrative of upcoming job market collapse is false -- there will be many AI and non-AI jobs). However, I believe there will be far more AI Engineer jobs than FDEs, as I explain below.
The FDE role was pioneered about two decades ago by Palantir, which sent engineers to government locations to work on secure, air-gapped networks. In addition to having good technical skills, FDEs need communication skills and sometimes business skills. For example, they may need to speak with clients to understand their needs, formulate a strategy to prioritize projects, explain complex technology, and respectfully push back if a client asks for something unrealistic. They’re enjoying a resurgence because of the amount of work involved in taking an off-the-shelf LLM and building it into a custom agentic workflow that fits particular business needs.
However, I believe the number of AI Engineer jobs will be far larger. A company might accept a few FDEs to be embedded within its organization. But most companies will want far more of their own employees working on their projects. While my organizations do hire FDEs, we hire far more AI Engineers! Also, a common client concern is that it is hard to find vendor-neutral FDEs — they are, after all, there to deeply integrate a particular vendor’s product into a company. In this moment when it’s hard to predict which AI service will be the best one in a year’s time, optionality (the ability to pick whatever vendor turns out to fit best in the future) is very valuable. In contrast, letting FDEs tightly bind a company’s processes significantly reduces optionality.
Right now, I see surging demand for AI Engineers who can build software applications using AI software components (like LLM prompting, agentic frameworks, evals, etc.) and effectively use AI coding agents (like Claude Code, Codex, Antigravity CLI, and OpenCode). As the AI Engineer role matures, I expect it to fragment into more specialized roles, like the generic Software Engineer role from decades ago fragmented into frontend, backend, mobile, data engineering, devops, and so on.
What will be the future, specialized AI engineering roles? I don’t know. Perhaps there will be AI FDEs, LLMOps Engineers, Evals Engineers, AI Data Engineers, Harness Engineers, and other roles we don’t have names for yet. But for now, I see a lot of AI engineers who are generalists create a lot of value. Skilled AI Engineers are in very high demand! As our field continues to mature over the coming decade, I look forward to new specializations within AI Engineering that create even more job opportunities.
[Original text: The Batch newsletter]](https://pbs.twimg.com/media/HJvWmCHagAAnTxQ.jpg)