Agreed. On top of that, many equate “scientific method” with “peer review academic publishing”. This is fundamentally broken in the new era of AI. It requires a set of average “human brains” that are supposed to not use “AI” because of academic ethics to check each others assumptions and results.
In the new era of complex dynamic systems and emergent properties, human brains are fundamentally limited. AI will find multidimensional non-linear relationships that are no longer fully understood by humans. This AI generated new “science” may never get through the human-referee-driven publishing bureaucracy. We will end up with new discoveries going directly from discovery → products or services - completely bypassing the human mind bottleneck.
There is no such thing as a scientific “method” in the sense of a reliable algorithm or repeatable process.
We’re taught in grade school that a scientist tabulates observations, then induces a theory from those observations, and then tests them to get to the truth.
But observations are themselves mini-theories (you never observe anything directly), induction from observations can’t give you novel theories (black swan problem), and testing can only eliminate competing theories, not prove them (error correction).
All you’re left with is creative guesswork and then eliminating the bad guesses to get you closer to the truth, but with no finality. Not much of a process or method.
“Scientists” have no special method or process that they employ. They’re doing what all of us do all day long to navigate the world, hopefully with more rigor and dedication, but it’s the exact same process at its core.
What made the scientific revolution possible was a philosophical shift in which parts of western society created social conventions around rigorous truth seeking rather than continuing to justify the beliefs of the ancients.
See Deutsch’s “The Beginning of Infinity” and Karl Popper’s writing, “On the Non-Existence of Scientific Method."
Agreed. On top of that, many equate “scientific method” with “peer review academic publishing”. This is fundamentally broken in the new era of AI. It requires a set of average “human brains” that are supposed to not use “AI” because of academic ethics to check each others assumptions and results.
In the new era of complex dynamic systems and emergent properties, human brains are fundamentally limited. AI will find multidimensional non-linear relationships that are no longer fully understood by humans. This AI generated new “science” may never get through the human-referee-driven publishing bureaucracy. We will end up with new discoveries going directly from discovery → products or services - completely bypassing the human mind bottleneck.
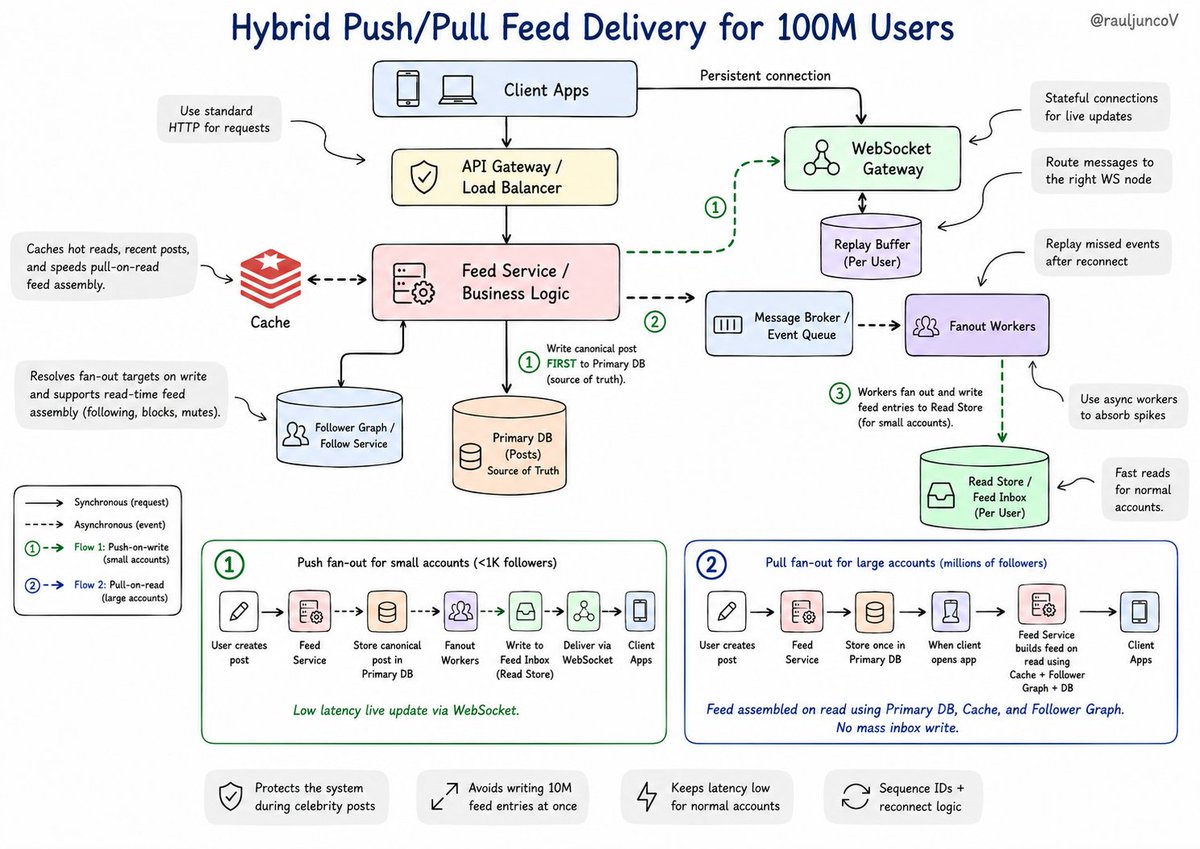
Many wonder why Silicon Valley engineers sometimes earn 10x or 100x more. They have learned how to scale to 100s of millions or billions of users. It is a different way of thinking and problem solving that would be an overkill in smaller scale projects.
Push-based systems come up in 90% of system design interviews.
Here's the exercise you should be able to solve:
Design a notification system for 100M users. Some have 50 followers. Some have 10M.
The instinct is to hold a WebSocket connection open to every active user and push updates as they arrive. Clean mental model. It collapses the moment a celebrity posts.
When someone with 10M followers posts, you push to 10M open connections simultaneously. Your message broker saturates. Your WebSocket servers fall over. The system fails at the exact moment it needs to work.
That's the fan-out problem. And it kills more interview answers than any other mistake.
The production answer: push and pull aren't binary. You pick based on follower count. Users with fewer than 1,000 followers get push fan-out. Each follower gets notified immediately.
Users with millions of followers get pull fan-out. Their feed assembles on read. Nobody gets a push. Followers see the post when they open the app.
Twitter built exactly this: push-on-write for small accounts, pull-on-read for large ones.
But fan-out is only half the problem.
Push means stateful connections. Your servers now need to know which connection lives on which machine. You can't route blindly. Most teams reach for Redis pub/sub here; the WebSocket server subscribes, the backend publishes, the message finds the right node.
Add a 3-second network drop and you have another layer: what did the client miss? Now you need sequence IDs, a message buffer, and reconnect logic that replays missed events.
"Push-based" became push with a pull fallback, a message broker, sticky routing, and a replay buffer.
Most engineers stop at the first diagram.
The ones who get the offer keep pulling the thread until the system breaks.
Reductionist thinking is limited in the type of problems it can solve.
All of our recent AI advances are emergent properties within dynamic complex systems. They cannot be understood or steered through reductionism.
The near future is all about steering complexity.
There are only two honest metrics when it comes to benchmarking intelligence: novelty and efficiency.
You don't need intelligence to solve a known problem (only memory). And you don't need intelligence to solve a problem via brute force. But to solve a novel problem efficiently, intelligence is the only way.
Polymarket prices are highly accurate in predicting future events. The source of that accuracy is less obvious.
In a new working paper, we find it is not the “wisdom of crowds,” but a small minority of informed traders.
Fewer than 3% of accounts appear to drive price discovery; most perform no better than chance.
The majority generates most of the volume but little of the information, effectively funding the informed minority.
Check the paper here: https://t.co/z5VsKzb1CE
If you figure out how a large multi-agent system can autonomously coordinate to maximum effect, you’ll win a Nobel Prize, a Turing Award and a trillion-dollar fortune all in one.
@alexolegimas Alex, great essay. I would add that status-driven, relation-economy includes things like live entertainment (sports, concerts) and hospitality (dining out, tourism).
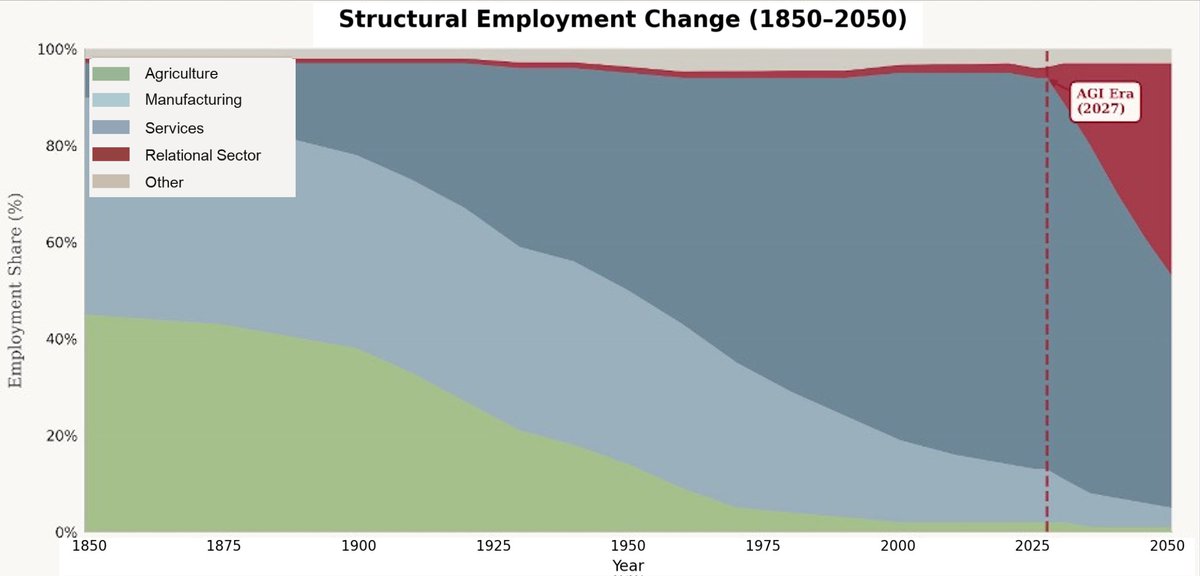
If so, that red layer is already growing fast and will speed up significantly.
New essay on the economics of structural change and the post-commodity future of work.
1. Almost any question about the impact of advanced AI on the economy needs to start at the same place: what is still scarce? Answer that, and the analysis becomes pretty straightforward. This essay explores what becomes scarce if AI really can replicate most of what humans do in production, and what this mean for the future of jobs.
2. My conjecture, working through the economics: labor reallocates across sectors, and the sector it reallocates to has properties that keep labor a meaningful share of the economy. Ultimately this is about the structure of demand itself. For this, we have to go back to Girard, Augustine and Rousseau: once people's base needs are met, their preferences shift to comparative motives (e.g., status, exclusivity, social desirability). This motive is inherently non-satiated.
4. The key paper is Comin, Lashkari, and Mestieri (Econometrica 2021). As people get richer, they don't buy proportionally more of everything. They shift spending toward sectors with higher income elasticity. They estimate income effects account for 75%+ of observed structural change.
5. The ironic consequence: the sector that gets automated becomes a smaller share of the economy, not a larger one. Agriculture got massively more productive and its share of employment collapsed. Manufacturing too. The "stagnant" sectors absorb the spending and the jobs.
6. So the question is: which sectors have high income elasticity in a post-AGI world? I argue it's what I call the relational sector. Categories where the human isn't just an input into production, it is part of the value.
7. Why does the relational sector have high income elasticity? Because human desire has a mimetic, relational dimension. We don't just want things for their intrinsic properties. We want what others want, and we want it more when others can't have it. Girard, Rousseau, Augustine, and Hobbes all saw this.
8. In work with Kristóf Madarász, we showed this experimentally: WTP roughly doubles when a random subset of others is excluded from the good. And in new work with Graelin Mandel, AI involvement kills the premium. Human-made art gains 44% from exclusivity; AI-made art only 21%.
9. This all comes together for the core argument. The sector that absorbs spending as AI makes commodity production cheap is one where human provenance is part of the value, and demand for it grows faster than income. Exactly the profile that keeps labor meaningful.
10. To be clear about the claim: I'm NOT saying aggregate labor share must rise. It may fall. The claim is about sectoral composition, i.e., where expenditure and employment go once commodities get cheap, and the fact that the sector that will absorb reallocated labor maps to a substantial component of human preferences and desire.
11. If you're interested in the formal model, a linked companion technical note works out all the economics.
Read the essay here: https://t.co/NcjVgn2o8g
11/12 AI is about selling work, not software. Units of labor as the product
This is a big shift in TAM, agents, how to build product in the AI era. Many AI markets are 10-100X the size of their seat based software counterparts
As Carl Jung put it, "Man needs difficulties. They are necessary for health." Yet most people instinctually avoid pain. This is true whether we are talking about building the body (e.g., weight lifting) or the mind (e.g., frustration, mental struggle, embarrassment, shame)--and especially true when people confront the harsh reality of their own imperfections. #principleoftheday
Constraints are the catalyst of invention. An infinite search space leads to paralysis. The most creative inventions happen when you are forced to solve a problem within appropriately narrow constraints.
Zach - thanks for answer, thoroughness in your model. I will keep trying to help you falsify.
Probably best course of action for me is not to try to replicate your model. I believe what you've built is solid enough. Probably you can upload to your git so that we can tweak and test.
My take is that we need to assume the model is correct given the implications. However, in parallel, we want to try and be ready to disprove it fast.
A few focused questions/suggestions to help tighten the dynamical side:
- can you share the differential equations (+any inertial terms) and the ensambles integration scheme?
- How is the effective damping/quality factor Q handled? The observed monotonic relaxation suggests strong overdamping, any reason for why reduced coupling doesn’t instead increase Q and allow resonant rebound?
- Have you tested reversible or bounded coupling degradation pathways (like thermal equilibrium or dynamo feedback)? This could distinguish transient anomalies from irreversible cascade.
- The ensembles seem to treat AAM/OAM as secondary, adding broadband stochastic excitation from those sources might reveal whether the tight clustering holds or tails open up
- Blind out-of-sample tests on pre-2020 data or multi-stable potentials with finite barriers could quantify escape probabilities
thoughts?
@naval No. Problem space is different. Coding is assembling existing algorithms and known interfaces into a new product. Research is creating new algos, interfaces, equations, experiments.
Novelty requires agency. AI currently has none. Code can be mediocre and still execute perfectly.
@nobulart Craig, great tweet, spot on. These events emerge from chaotic nonlinear dynamics. Timing and state-transitions are as unpredictable as the classic three-body problem. We're wired to hunt for simple causality and short-term patterns, then boldly extrapolate them.