1/14 Go's new map implementation in 1.24 is powered by Swiss Tables, a cutting-edge hash table design that significantly boosts performance. Let's break down why this matters and how @CockroachDB's implementation played a key role. 🧐🚀
Just learned OCSP is getting phased out by #letsencrypt later this year. As a certificate nerd, I feel like this is another small but meaningful shift in handling certificate validation. Short-lived certificates are the way to go!
https://t.co/iikD5i782e
Hey Folks, join us for our first public community meeting for https://t.co/DjvZMrwcB3 on Wednesday Feb. 5th at 9am PT (https://t.co/gMESTFvbgn). You can find the join details and agent for the meeting here https://t.co/aXpXn7a9uN. Feel free to add topics.
#rust#hyperlight
To understand the self, it's necessary to deconstruct our experience of subjective identity, and our experience of what it means for an object to be identical with itself. Identity is a representation, not a reality. Some represented objects have identity, others not.
Unpopular opinion: Your container images are bad because Dockerfiles is a no man's land.
- Application developers lack the motivation & relevant skills to write optimal Dockerfiles.
- DevOps engineers lack in-depth knowledge of the application stack and up-to-date build best practices.
But both camps can be easily understood! That's a lot of cross-functional knowledge to keep in one's head, especially for a secondary-importance activity such as building good container images.
That's why Kyle and I decided to team up and try to move the needle. If your team is having a hard time building container images, reach out, and we'll provide an expert Dockerfile review.
Free of charge while the program is in the pilot phase 🙌
Apply at https://t.co/AvfGeaGuuP
How to learn Docker? My answer is - by doing! 💪
You can't cheat your way into a new language, a technology, or a tool. Learning always requires putting in some effort, and for CLI tools like Docker, building muscle memory is a must.
Go practice https://t.co/DPZlSQPttR
What started out a couple years ago as about ~10 IRL friends led to a community of 4,700 active beta testers. I just turned off beta invites in the Ghostty discord. The beta period is officially over; they provided invaluable feedback and contributions ❤️ Getting close now.
Over the past 8 days, I received over 100 PRs on the languages repo with additions and improvements.
- A bunch of languages were added
- Some implementations got tweaks to modify performance
- The run script now uses hyperfine for timing
Thanks to all the contributors.
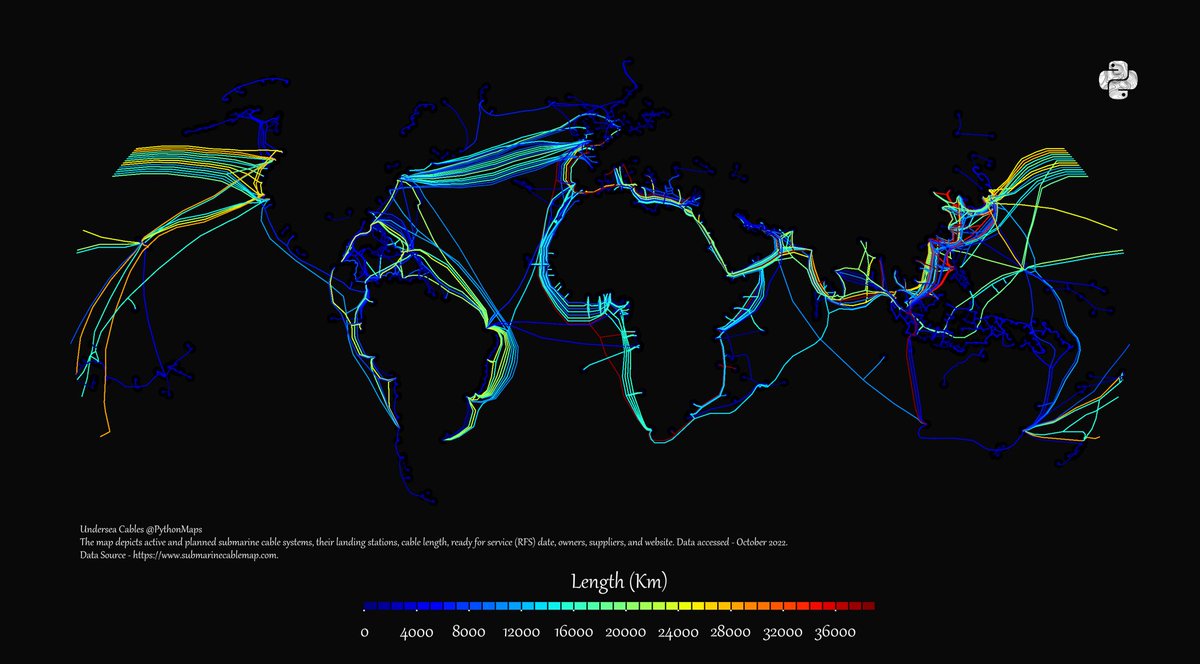
Most people don't realize that "the internet" at its core is a bunch of cables laid under the sea and across the world that transport data as light.
There are 500-600 nondescript buildings which are airports for light (IXPs) and 13 DNS root servers that are air traffic control.
I'm doing something new (for me) with Ghostty: the issue tracker is only for actionable tasks. Features in the issue tracker are accepted and well-scoped. Bugs are reproducible. PRs must have an associated issue (no drive-by PRs). The issue tracker is not used for discussion.
The one main benefit of this is maintainers and contributors can open up the issues tab and dive into anything. Every single issue is ready to be worked on. People who open a PR referencing an issue can have very high confidence their PR will be accepted.
In past OSS projects I've either started or been part of, the issue tracker has become a mess of Q&A, stale bug reports, and enhancement discussion. Drive-by PRs put burden on maintainers because they may implement an interesting feature but an undesirable way and saying no feels bad.
I also really hate issue bots. "Issue stale type /go-fuck-yourself to keep it open" is a system I've hated from both sides as a user and maintainer. (Bots that simply do categorization are good bots) The pattern I'm doing with Ghostty means issues in the issue tracker are never stale.
This time, all discussion is encouraged to use GH discussions. Once a bug is reproducible or a feature is designed in a way I approve of, it is converted to an issue. Some discussion happens in Discord/IRC too but I encourage it to eventually move to GH so it can be indexed by search engines.
We've been doing this for only about a month now and only within the context of a small (~2000 people) private beta, but so far I've thoroughly enjoyed the change in project management from it.
Did you know that a random SSD read is multiple orders of magnitude slower than a random memory read?
I made a little visual that really drives the point home.
This is why memory buffers and caches are so important, especially for I/O heavy workloads like databases.