Open sourcing Kompaktor—a proof of concept that compresses Bitcoin payments from different senders into a single output.
No soft forks. No custodians. Works today.
https://t.co/bjLzLvEzT9
For our spanish borrowers and lenders this is a great podcast our CTO went on to explain something the ins and outs of arkade and why we're so bullish on this new tech 🫡👾
A release giving you sovereign superiority. This has been many years coming, with the features added being requested for as long as @BtcpayServer has existed.
Lightning experience is progressively getting better and super smooth on https://t.co/fCVtx03xXB
Lots of complexity now handled through a very simple SDK integration.
Great jam on Arkade and how we plan to bring the world of finance on Bitcoin rails.
Skip my rambling at the beginning and go straight to the alpha.
Kudos to @jcrpntr for a great convo
BITCOIN RAILS #45: ARK BEYOND PAYMENTS | with "Chief KOL" @bergealex4@arklabsHQ
🔗 YOUTUBE: https://t.co/frUC4ka8Sb
🌿 SPOTIFY: https://t.co/Qz95fRoZW2
If you’ve been following the “Bitcoin Season II” meta for some time, you’re likely already following Bitcoin tech critic @bergealex4—formerly comms at @Blockstream and Layer-2 reporter for @BitcoinMagazine.
A notorious contrarian, he’s known for being difficult to impress—and for having a soft spot for the Ark Protocol, which he sees as uniquely suited for trustless Bitcoin scaling and DeFi use cases (e.g. lending) more broadly.
Alex made his relationship with the Ark protocol official earlier this year, joining the @arkade_os implementation team led by @ArkLabsHQ and @tierotiero.
Taking a notably different approach to both engineering and product design than competitor @2nd (see last week’s episode with @stevenroose for comparison), Alex shares why the payments use case is “only the beginning” for the Ark protocol, and why Ark Labs intends to lead the charge on the protocol’s potential for Bitcoin-native DeFi.
In this episode, Alex and I unpack:
- How Alex’s experiences at Blockstream and Bitcoin Magazine shaped his views on governance, communication, and prepared him for the new wave of political disruption we're seeing in Bitcoin today.
- Why the Payments use-case is only ONE application Ark Lab's Arkade implementation intends to support.
- The trade-offs of introducing programmability into Ark: why expressiveness introduces operator dependencies, and how Arkade approaches minimizing (but not eliminating) those trust assumptions.
- What Bitcoin-native capital markets could look like: synthetic exposure, structured products, and treasury-style use cases, designed to remain self-custodial once the technology matures.
For anyone trying to understand the differences between competing Ark protocol implementations—this episode is a must watch. Highly recommend a side-by-side comparison with last week's episode with @stevenroose3 as well.
This episode of Bitcoin Rails is powered by:
- Best In Slot (@bestinslotxyz) — the leading API for Ordinals and BRC-20 data aggregation and indexing.
- Spark (@lightspark) — a statechains implementation advancing Bitcoin-powered payments.
- Citrea (@citrea_xyz) — a leading Bitcoin rollup technology and BitVM alliance contributor.
📌 Timestamps:
00:00 Intro
01:45 Alex’s Early Bitcoin Journey
02:59 Scaling Bitcoin and Community Involvement
08:11 Blockstream and the Block Size Wars
14:25 Transition to Bitcoin Magazine
21:10 Joining Arkade and Future Prospects
41:09 Key Difference Between Arkade and Second
43:59 Off-Chain Transactions and Operator Risks
46:11 Bitcoin Native Assets and Programmability
51:29 Synthetic Assets and Financial Products
56:01 Challenges and Opportunities in Bitcoin Programmability
01:04:38 Past and Future of Bitcoin Programmability
Retail and commerce are downstream of financial services.
The future hinges on whether those services are open and decentralized, or locked behind centralized silos.
@jackmallers gets it.
👾 Sneak peek: I’m building a new Chrome extension wallet!
Not released yet — we’re still testing and refining the experience.
Something simple, fast, and built for daily users.
Stay tuned for the launch! ⚡️🚀
We're excited to release one of the smallest and most performant Guardrail Models ever-
MiniGuard-v0.1: A 0.6B parameter model that achieves performance at par with Nemotron-8B while being 13x smaller.
We looked at where large models beat small ones, and it’s not general reasoning. It was trigger words like "kill" or "shoot" showing up in safe contexts. "Kill the process" vs "kill him." "Shoot the photo" vs "shoot the target."
To account for these, we trained Miniguard-v0.1 using four techniques, each targeting a specific gap between small and large model performance:
1. Targeted synthetic data
2. Step-by-step distillation (Reasoning Data)
3. Model soup
4. FP8 quantization
The Results: On the Nemotron-Safety-Guard benchmark (English test split)
- MiniGuard achieves 0.893 Macro F1
- Nemotron-Guard-8B achieves 0.897 Macro F1.
99.5% of the accuracy at 1/13th the size.
At typical production concurrency (1-8 requests), MiniGuard is 2-2.5x faster than Nemotron.
MiniGuard-v0.1 is available now under the MIT license.
It's a drop-in replacement for Nemotron Guard. Same prompt template, same output format.
Head on over to our HuggingFace repo to read how we built the model and try it out yourself 👇
We're excited to release one of the smallest and most performant Guardrail Models ever-
MiniGuard-v0.1: A 0.6B parameter model that achieves performance at par with Nemotron-8B while being 13x smaller.
We looked at where large models beat small ones, and it’s not general reasoning. It was trigger words like "kill" or "shoot" showing up in safe contexts. "Kill the process" vs "kill him." "Shoot the photo" vs "shoot the target."
To account for these, we trained Miniguard-v0.1 using four techniques, each targeting a specific gap between small and large model performance:
1. Targeted synthetic data
2. Step-by-step distillation (Reasoning Data)
3. Model soup
4. FP8 quantization
The Results: On the Nemotron-Safety-Guard benchmark (English test split)
- MiniGuard achieves 0.893 Macro F1
- Nemotron-Guard-8B achieves 0.897 Macro F1.
99.5% of the accuracy at 1/13th the size.
At typical production concurrency (1-8 requests), MiniGuard is 2-2.5x faster than Nemotron.
MiniGuard-v0.1 is available now under the MIT license.
It's a drop-in replacement for Nemotron Guard. Same prompt template, same output format.
Head on over to our HuggingFace repo to read how we built the model and try it out yourself 👇
We didn’t just start a research lab, we started in the real world: launching Bitcoin ATMs, cash brokerages, payment infrastructure.
We don't theorize about payments, we've designed & shipped services used by hundreds of thousands of users.
Next, we move all markets onchain.
While building Studio, we saw that most teams wanted to fine-tune models, but their data wasn’t ready for it.
Either the internal data was messy and unlabeled, or there simply weren’t enough examples to train on. Both problems added weeks before training even began.
Prem Studio’s Datasets feature was designed to solve these issues. With Studio, you can:
- Create: Teams could upload their own JSONL or generate synthetic datasets from PDFs, YouTube videos, webpages, or any combination of sources. If they had raw content but no structured training data, Studio generated question–answer pairs directly from the material for immediate training.
- Manage: Once a dataset existed, it could be enriched with synthetic datapoints to increase volume without collecting more real data. Studio automatically labeled, cleaned, and de-duplicated data to fix inconsistencies (agents for the win) and auto-split it into train/test sets.
- Version: As datasets grew, users could save snapshots and build new models on updated data. This supported continuous fine-tuning as more production examples were collected.
So yeah, if you're held back due to data constraints, head on over to our docs to see how Studio can make your workflow easier today!
p.s. free credits to try Studio below 🤫
Arkade is the single most advanced application of Taproot & Musig2 technology.
It is the culmination of a decade of Bitcoin protocol research.
You’d think the intelligentsia would be celebrating its arrival.
Nop, not a shred of acknowledgement.
Innovator dilemma is real.
🚀 LendaSwap just launched a brand-new design!
We both swap directions. Its simple & seamless.
🔥 You can now trustlessly swap:
• Stablecoins on Ethereum and Polygon
• Into Bitcoin Arkade
• Into Bitcoin Lightning
Or the other way around.
LendaSwap keeps leveling up. ⚡️👾
Today, we’re excited to announce that Prem Studio is available for public access!
Built in collaboration with design partners from Fortune 50 companies, US healthcare providers, and compliance firms in the EU, Studio is an end-to-end platform for building specialized LLMs.
Studio makes it possible for you to build your own custom language model by fine-tuning 30+ small language models without writing any code. The platform handles all the heavy lifting from dataset management, selecting the best base models, managing training infrastructure, running evaluations, and deploying inference endpoints.
Teams using Studio, on average, achieve 10-30x model compression while maintaining 98% accuracy on most tasks. Some even outperform frontier LLMs on domain-specific tasks.
Prem Studio models are fully self-hostable, meeting the strict data sovereignty and security requirements of our enterprise and healthcare partners.
If you’ve got a dataset, you can ship a custom model now. Sign up below and claim free training credits!
Today we’re open-sourcing Funcdex - the complete framework for building your own function-calling models!
With Funcdex, you can build LLMs as small as 600M parameters for multi-turn function-calling on your specific set of tools. We expect these models to outperform frontier models - consistently.
We're open-sourcing everything you need to build today - code, datasets & fine-tuned examples.
Here’s what’s in the release:
(1) Funcdex-MT-Function-Calling: A dataset with over 100k multi-turn function calling examples across 15 toolkit configurations. One of the largest publicly available datasets.
(2) Funcdex-Synthesizer: A complete pipeline that converts your OpenAPI specs into toolkit-specific LLM training data with agent traces and tool use patterns.
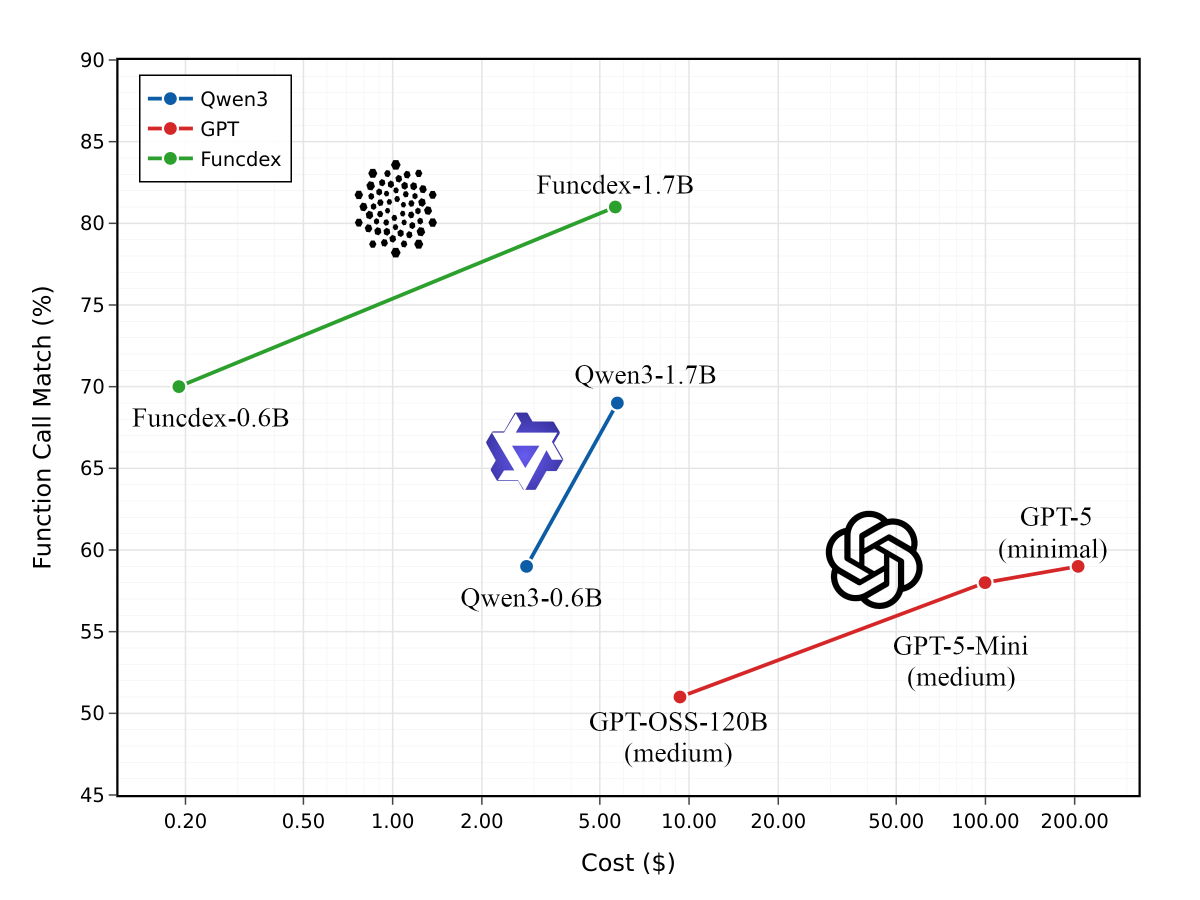
(3) Funcdex-Models: Our proof-of-concept fine-tunes of Qwen3 (0.6B & 1.7B), showing how efficient models can get when you optimize for specific APIs rather than general utilisation.
Our smallest model achieves an average score of 0.7 function-call string match at $0.19 per eval, while GPT-5 Mini achieves 0.58 at $99.71. This validates our thesis that specialized small models beat general large models when you have narrow use cases and elaborate system prompts.
While our Funcdex-MT-Function-Calling dataset covers Gmail, Calendar, Drive, Jira, Slack, and 10+ other business tools in both single and multi-toolkit scenarios, the included synthesizer has all the code and tutorials to generate your own training data from any OpenAPI spec.
We truly believe that while generally intelligence models are good for most tasks, building task-specific models offers a more sustainable and sovereign approach.
Link to code, datasets, and models below 👇