✈️Arrived in Rio🇧🇷 for #ICLR2026 this week!
Thrilled to present our work:
1. Visual Planning: Let's Think Only with Images
@ Oral Session 3D Vision language models II
Fri 24 Apr 10:30; Poster P4-3304
2. Multi-Agent Design
Sat 25 Apr 10:30, P4-4713
Looking forward to a chat!
🚨 Google just dropped the most advanced self-improving video AI ever built.
It’s called VISTA, and it literally rewrites its own prompts to make every new generation better than the last.
No retraining. No fine-tuning. Just pure test-time self-reflection.
Here’s how it works:
→ Turns your idea into a full scene-by-scene storyboard
→ Generates multiple video candidates
→ Runs a tournament to find the best one
→ Then critiques itself visually, audibly, contextually before trying again
Each loop = sharper visuals, tighter storytelling, more aligned motion.
The results? 60% win rate vs Veo 3 and 66.4% human preference.
This isn’t “text-to-video.”
This is video that learns from itself.
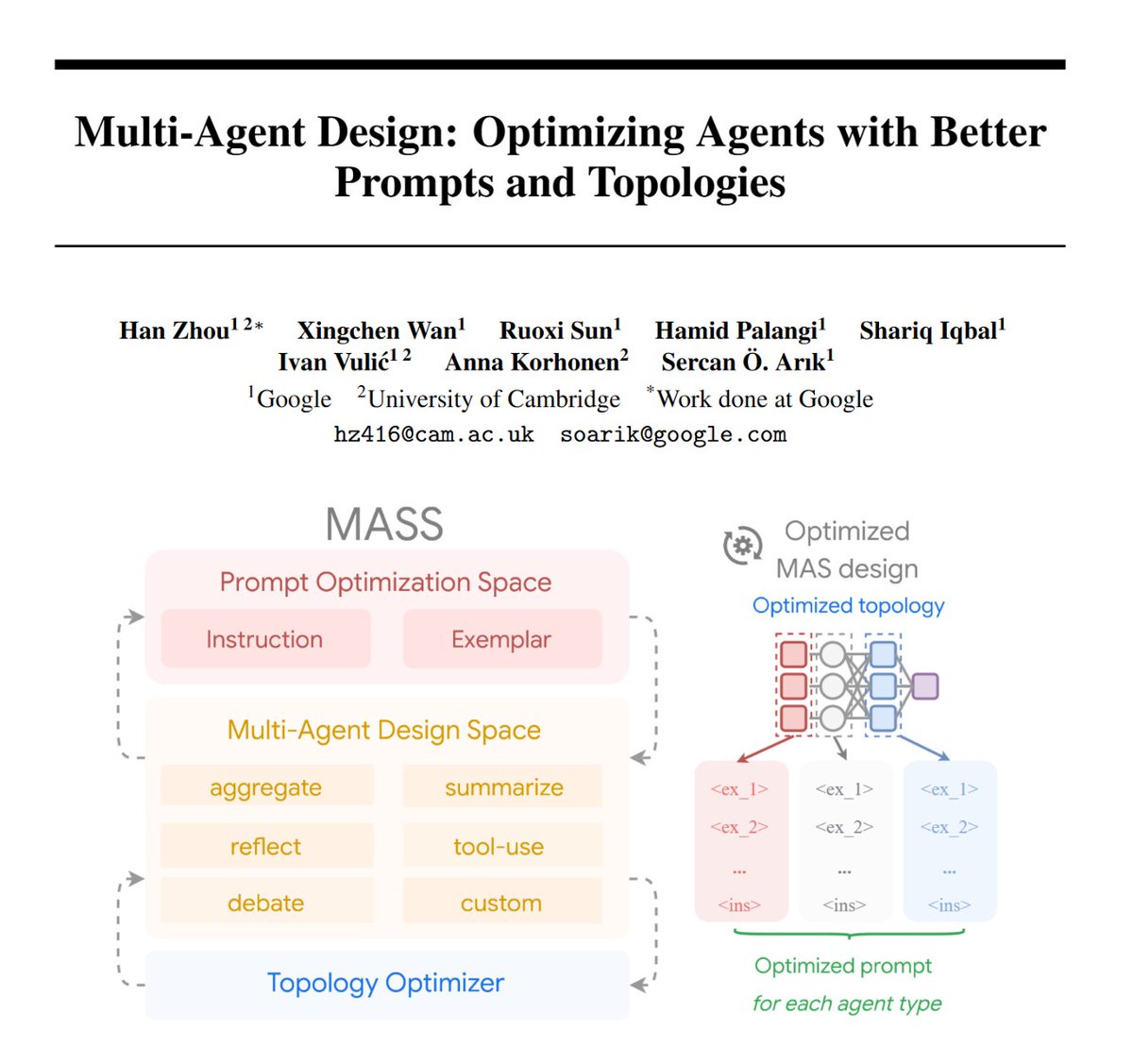
Automating Multi-Agent Design:
🧩Multi-agent systems aren’t just about throwing more LLM agents together.
🛠️They require mastering the subtle art of prompting and agent orchestration.
Introducing MASS🚀- Our new agent optimization framework for better prompts and topologies!
🚀Let’s Think Only with Images.
No language and No verbal thought.🤔
Let’s think through a sequence of images💭, like how humans picture steps in their minds🎨.
We propose Visual Planning, a novel reasoning paradigm that enables models to reason purely through images.
Astute RAG
Proposes a novel RAG approach to deal with the imperfect retrieval augmentation and knowledge conflicts of LLMs.
Astute RAG adaptively elicits essential information from LLMs' internal knowledge. Then it iteratively consolidates internal and external knowledge with source-awareness.
Astute RAG is designed to better combine internal and external information through an interactive consolidation mechanism (i.e., identifying consistent passages, detecting conflicting information in them, and filtering out irrelevant information). (Prompts for this step provided in the paper)
The explicit consolidation step addresses knowledge conflicts which is probably one of the most challenging parts of building reliable RAG systems. It really does help to know how to leverage the internal and external information of RAG systems.
Which output is better?
[A] or [B]? LLM🤖: B❌
[B] or [A]? LLM🤖: A✅
Thrilled to share our preprint in addressing preference biases in LLM judgments!🧑⚖️We introduce ZEPO, a 0-shot prompt optimizer that enhances your LLM evaluators via fairness⚖️
📰Paper: https://t.co/ZkMvJnFFMC
#ICLR2024 Proud that 🚀Batch Calibration🚀 is accepted at @iclr_conf!
🔥Batch Calibration addresses the prompt sensitivity of LLMs and enhances LLMs' robustness to ICL orders, prompt templates, and ✔️❌choice of verbalizers even in emojis👍👎
📙Paper: https://t.co/UIhPGLsuLX
Visit the #EMNLP2023 Google booth today at 3:30 PM to learn about Universal Self-Adaptive Prompting, an automatic method tailored for zero-shot learning (while compatible with few-shot) that uses a small amount of unlabelled data & an inference-only LLM.
@linylinx Why not apply with an endorsement from RAEng which gives you ILR in 3 years instead of 5? https://t.co/YIeA0FCr88 AI/ML research is listed under RAEng, and industrial researchers are permitted: https://t.co/o7ypoaVCSH
Introducing COSP and USP: they select good demos from unlabeled samples & LLMs’ self-generated outputs as in-context examples to achieve stronger zero-shot performance 💪
Paper: https://t.co/YwqZGpKuJh (COSP: ACL Findings) + https://t.co/wJ3Xuoxhns (USP: EMNLP)
Introducing a new approach for adaptive prompting of #LLMs that train with unlabeled samples + pseudo-demonstrations generated by the model itself to close the gap between few-shot and 0-shot performance on reasoning, NLU and language generation tasks. → https://t.co/ZtSEZOxNCc
🤔Curious about an efficient way to automatically find better prompts for your LLM? Thrilled to Introduce “ClaPS” which underscores the critical role of search space in prompt search accepted to #EMNLP Findings🎉.
📎Code: https://t.co/hW474orfRN
📷Paper: https://t.co/NshpmkRmwd
LLMs’ sensitivity to design decisions, such as template choice, can degrade performance & prevent their robust application. Introducing Batch Calibration, a simple method that mitigates this effect & improves on existing methods w/ negligible add’l cost → https://t.co/Y7VbhanA3w
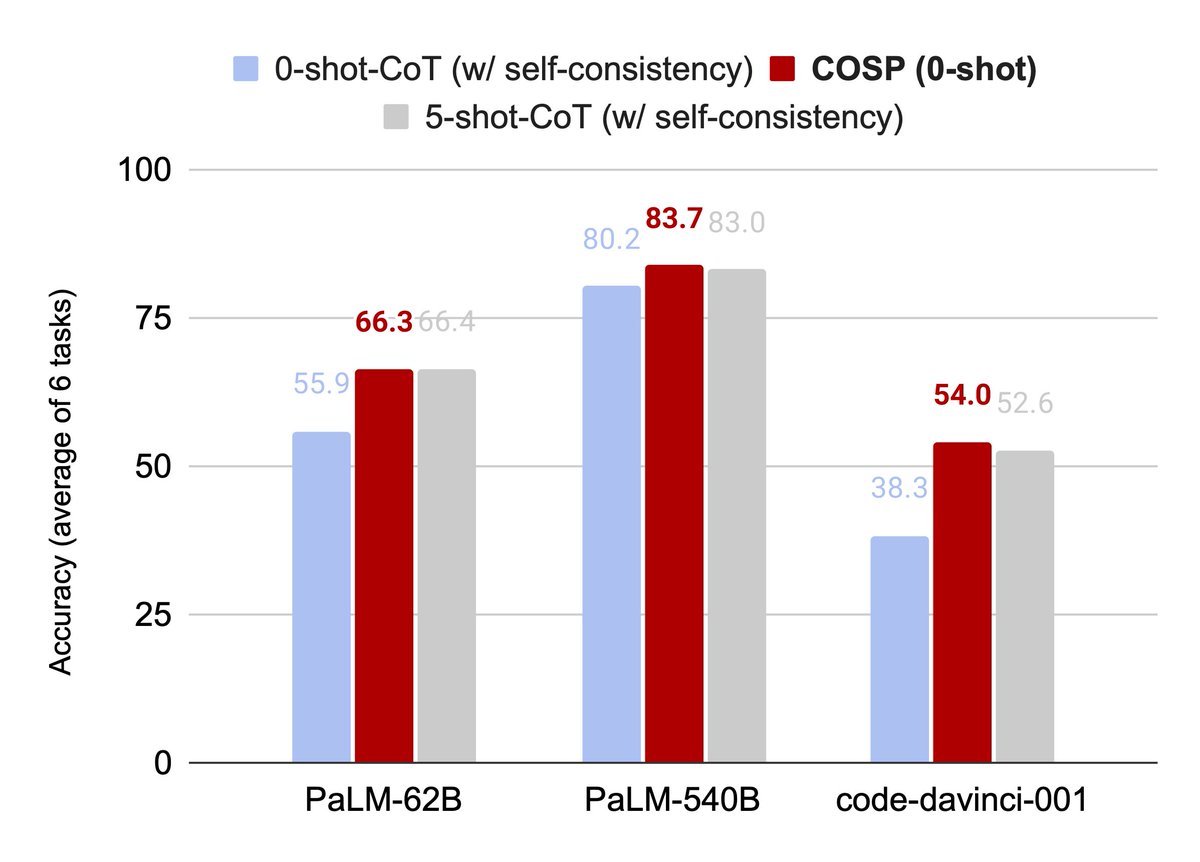
5/5 We evaluate COSP on three different LLMs in the zero-shot setting over 6 tasks to show vast improvement.
Paper: https://t.co/YwqZGpKuJh.
Many thanks to my fantastic coauthors: @ruoxi_cc, @sercanarik, @hanjundai and @tomaspfister.🤝
1/5 Wondering how to do better than “Let’s think step by step” in zero-shot? Enter COSP, a prompting technique that massively improves reasoning over 0-shot-CoT & matches few-shot in 3 LLMs – a work done during my internship at @Google & accepted to #ACL2023NLP Findings🤩
4/5 We thus use entropy (and a repetition penalty) to craft a scoring function. We run zero-shot-CoT, score the outputs and determine which outputs should serve as the LLM’s in-context demos – all done using unlabelled data & LLM’s outputs & no more laborious handcrafting 🎯

















![hanzhou032's tweet photo. Which output is better?
[A] or [B]? LLM🤖: B❌
[B] or [A]? LLM🤖: A✅
Thrilled to share our preprint in addressing preference biases in LLM judgments!🧑⚖️We introduce ZEPO, a 0-shot prompt optimizer that enhances your LLM evaluators via fairness⚖️
📰Paper: https://t.co/ZkMvJnFFMC https://t.co/qtz1ckZJSa](https://pbs.twimg.com/media/GQV8F61X0AAT_Xp.jpg)