Excited to release 🌟Polar🌟, our Agent RL rollout infra for real-world harnesses. Be it Codex, Claude Code, OpenClaw, Hermes, or your self-made ones 🔥 -- Polar takes your harnesses directly as training environments without code change.
Find a problem, design the harness, and train your own agents! 🧵
Seriously, Browser Use Desktop is really awesome. It combines Claude Code and Browser Harness, and features a visual UI, making it perfect for non-technical users to use, you guys should try it out🔥
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at https://t.co/GCdiMzk1Dl via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: https://t.co/drlDrxkYtp
🤗 Open Weights: https://t.co/T13Y8i7SDM
1/n
Meet Kimi K2.6: Advancing Open-Source Coding
🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2)
What's new:
🔹Long-horizon coding - 4,000+ tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization).
🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP + Framer Motion, Three.js 3D.
🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100+ files.
🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops.
🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop.
-
K2.6 is now live on https://t.co/YutVbwktG0 in chat mode and agent mode.
For production-grade coding, pair K2.6 with Kimi Code: https://t.co/uvoSJKyGCY
-
🔗 API: https://t.co/EOZkbOwCN4
🔗 Tech blog: https://t.co/9wWvgIQSS3
🔗 Weights & code: https://t.co/Be0hjs2RTP
Introducing: Browser Harness. A self-healing harness that can complete virtually any browser task. ♞
We got tired of browser frameworks restricting the LLM. So we removed the framework.
> Self-healing — edits helpers. py on the fly
> Direct CDP — one websocket to Chrome
> No framework, no rails, complete freedom
> Drop-in for Claude Code and Codex
I challenge anyone to find a task that DOESN'T work. I couldn't yet.🔥
100% open source ↓
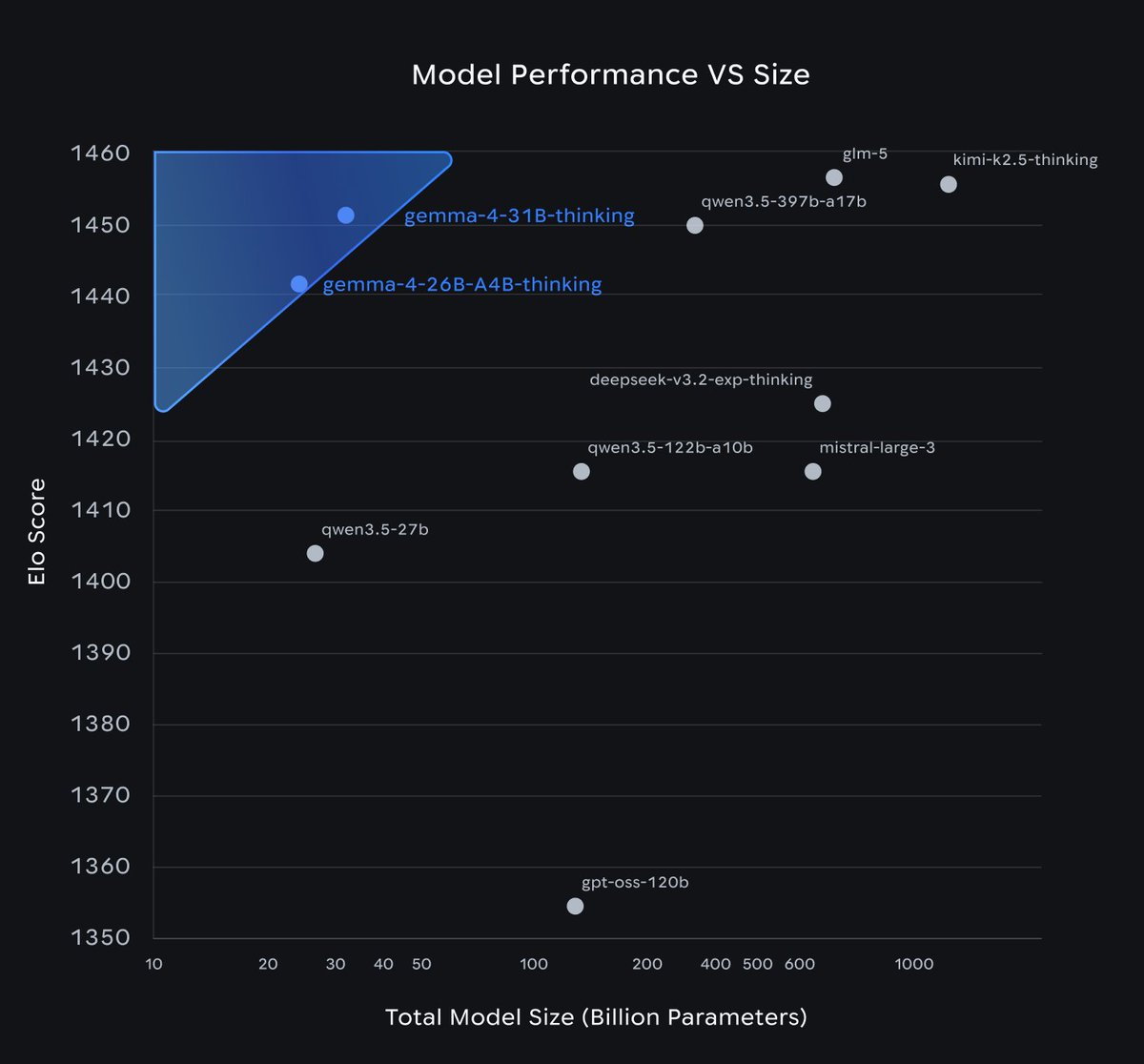
Google has released Gemma 4, a new family of multimodal open-weight models including Gemma 4 E2B, Gemma 4 E4B, Gemma 4 31B and Gemma 4 26B A4B
@GoogleDeepMind’s new Gemma 4 family introduces four multimodal models supporting text, image, and video inputs. We evaluated Gemma 4 31B (dense) and Gemma 4 26B A4B (MoE), both with a 256k context window, while the other two smaller models support up to 128k. With 31B and 26B parameters respectively, both evaluated models can run on a single H100.
On GPQA Diamond, our scientific reasoning evaluation, Gemma 4 31B (Reasoning) scores 85.7%, the second highest result we have recorded for an open-weights model with fewer than 40B parameters, just behind Qwen3.5 27B (Reasoning, 85.8%). It reaches this score using only ~1.2M output tokens, fewer than Qwen3.5 27B (~1.5M) and Qwen3.5 35B A3B (~1.6M). Gemma 4 26B A4B (Reasoning) scores 79.2%, ahead of gpt-oss-120B (high, 76.2%) but behind Qwen3.5 9B (Reasoning, 80.6%).
We are now running the Artificial Analysis Intelligence Index on all four Gemma 4 models and will share a full update once those results are complete.
Meet Gemma 4!
Purpose-built for advanced reasoning and agentic workflows on the hardware you own, and released under an Apache 2.0 license.
We listened to invaluable community feedback in developing these models. Here is what makes Gemma 4 our most capable open models yet: 👇
Ollama is now updated to run the fastest on Apple silicon, powered by MLX, Apple's machine learning framework.
This change unlocks much faster performance to accelerate demanding work on macOS:
- Personal assistants like OpenClaw
- Coding agents like Claude Code, OpenCode, or Codex
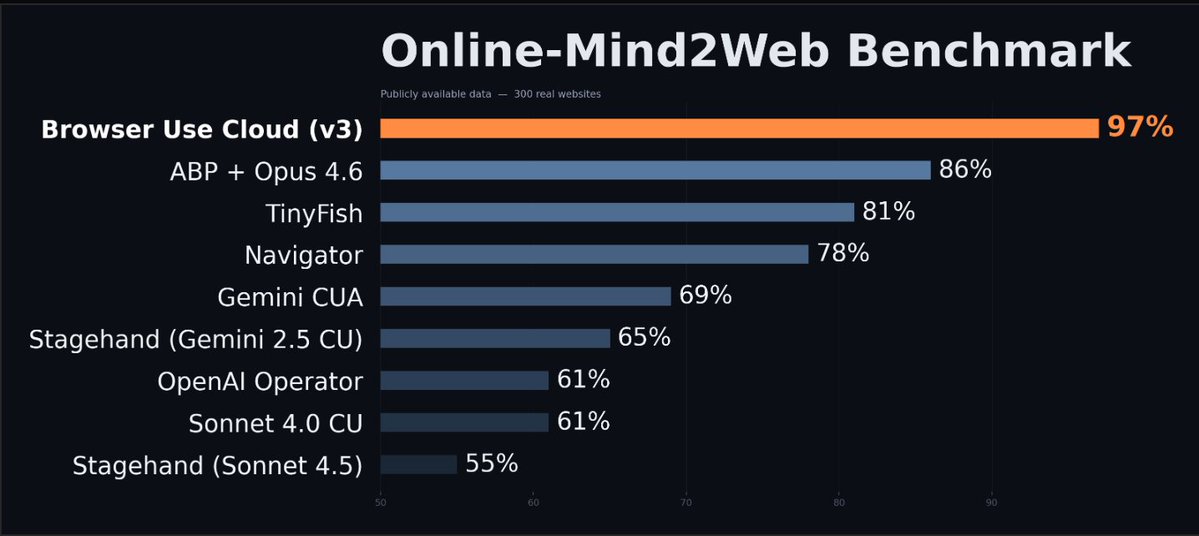
We hit SOTA on the biggest browser agent benchmark, scoring 97% on Online-Mind2Web🔥
We used Karpathy's Auto-Research (Claude Code in a loop) to improve our product.
Here is how you can apply the same to your product👇Full guide, CLI design, and all the results:
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation.
Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers.
🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth.
🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale.
🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead.
🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains.
🔗Full report:
https://t.co/u3EHICG05h
Take a bigger slice of the agentic web this #PiDay by shipping a literal pizza pie → https://t.co/13Cts8pFD1
To try: enable chrome://flags/#enable-webmcp-testing & install the Model Context Tool Inspector extension.
Share what "pi" you’d build below! 🍕
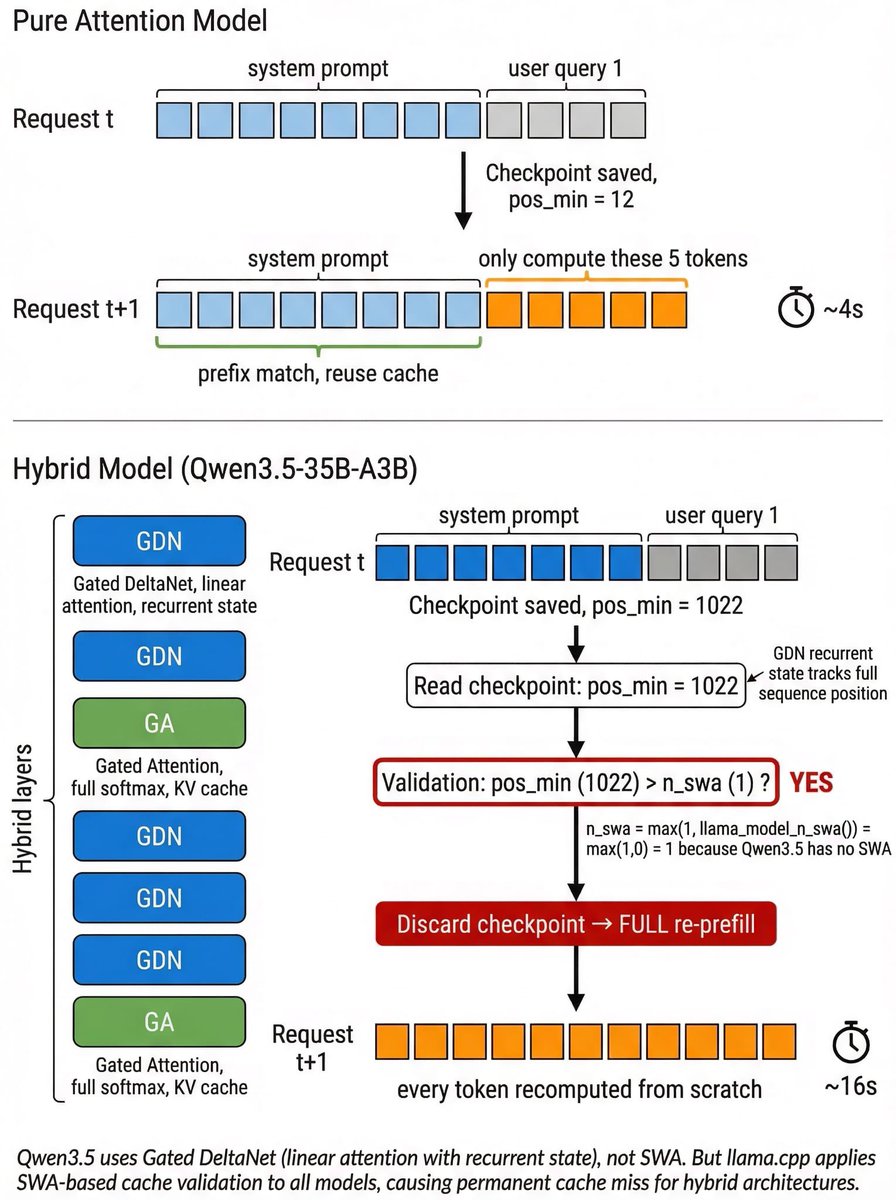
uh..Qwen3.5-35B-A3B on llama.cpp re-prefill on every request, ~4x slower than it should be. anyone solved this? Thought people have happily deployed & used it locally? But if this is not solved yet, the perf is quite limited.
Root cause: GDN layers are recurrent → pos_min tracks full sequence → but llama.cpp validates cache using an SWA threshold that defaults to 1 for non-SWA models → pos_min > 1 always true → cache always discarded → full re-refill every time?