A coffee lover, a biker, a jogger, a weekend wanderer, and a part-time statistician. これは公式に非公式なアカウントです。表現は選ぶよう努めていますが、良からぬ発言は怒らず晒さずご指摘ください…。また、フォローよりリスト、派です。
PyTorch Fundamentals: Your First Steps into Hands-on Deep Learning.
Github (900+ stars): https://t.co/pFon17yIOk
Introduction to PyTorch fundamentals, covering tensor initialization, operations, indexing, and reshaping.
study physics with math.
otherwise you’re just collecting metaphors.
• force → vectors, not vibes
• motion → calculus, not intuition
• energy → equations, not slogans
• fields → geometry, not magic
• waves → functions moving through space
physics tells you what reality does.
math tells you why it does it.
separate them and you get shallow understanding.
combine them and the world starts exposing its source code.
MIT's Books on AI & ML (FREE DOWNLOAD):
1. Foundations of Machine Learning
https://t.co/78p57EBbL8
2. Understanding Deep Learning
https://t.co/D2oyRrXqcE
3. Introduction to Machine Learning Systems
❯ Vol 1: https://t.co/IezLFJdhDV
❯ Vol 2: https://t.co/NYP3xAPZ6u
4. Algorithms for ML
https://t.co/lntuD4Q19H
5. Deep Learning
https://t.co/vCHVIZQYTI
6. Reinforcement Learning
https://t.co/JNWhFCuCkH
7. Distributional Reinforcement Learning
https://t.co/GXpkV4BDZi
8. Multi Agent Reinforcement Learning
https://t.co/T8zVmQVutO
9. Agents in the Long Game of AI
https://t.co/HeD3Nsm5zz
10. Fairness and Machine Learning
https://t.co/csAjhdf7Lb
11. Probabilistic Machine Learning
❯ Part 1 : https://t.co/5Leef9ypGj
❯ Part 2 : https://t.co/vRbF0rEIuh
"Mathematics of Neural Networks" is an excellent set of lecture notes for anyone who wants to study modern neural networks from a mathematical perspective.
It covers supervised learning, artificial neurons and activation functions (ReLU, sigmoid, tanh, swish, softmax), shallow and deep neural networks, stochastic gradient descent, weight initialization, vanishing and exploding gradients, convolutional neural networks, automatic differentiation, backpropagation, adaptive optimization algorithms (Adagrad, RMSProp, Adam), and concludes with modern geometric concepts such as manifolds, Lie groups, equivariance, group convolutions, and rotation-translation equivariant CNNs.
I recommend keeping it in your bookmarks as a useful reference whenever you need to explore the mathematics behind neural networks.
https://t.co/78VDWxjDUa
Stop learning LLM internals from random one-off tutorials.
LLM Internals is a step-by-step GitHub learning repo for understanding how large language models work under the hood.
It helps you build a cleaner mental model by organizing blogs and videos from tokenization to attention math, Transformer components, training concepts, and inference optimization.
Key features:
• Fundamentals first – starts with LLMs, RAG, MCP, agents, fine-tuning, quantization, tokenization, and BPE
• Attention math – walks through Q/K/V, √dₖ scaling, causal masking, RoPE, and grouped-query attention
• Transformer components – covers the architecture, feed-forward networks, normalization, MoE, and LoRA
• Training concepts – includes backpropagation, cross-entropy loss, RLHF, and reasoning models
• Inference optimization – covers KV cache, paged attention, Flash Attention, speculative decoding, continuous batching, and prompt caching
It’s open-source (Apache License 2.0).
Link in the reply 👇
Updated 2204-page PDF Mathematics ebook:
"Algebra, Topology, Differential Calculus, and Optimization Theory For Computer Science and Machine Learning"
Find it here: https://t.co/HZc0LRoD7R
Learn NLP and language modeling with a structured Stanford course.
What you will learn:
- Work with sequence, text, and language-modeling problems
- Understand how models learn, optimize, and improve from data
- Build a clearer mental model of code Generation
- Build a practical understanding of this part of NLP and language modeling
Link is in the first comment 👇
♻️ Share this with your network if you found it useful or insightful.
Everyone is chasing self-improving models.
The bigger opportunity is self-improving products. Your users generate the best learning signal every single day.
I think that's where the real competitive advantage will come from.
Hey Data Scientists! You’re great data superheroes already. But go deeper with *top* Data Science books: https://t.co/gvorH6qvTT
PS. There’s this thing called PRIME DAY happening right now.
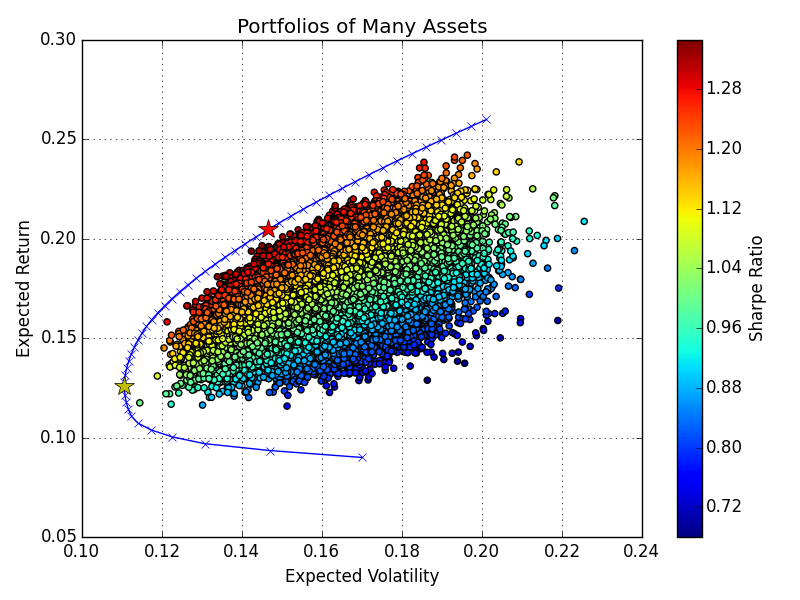
There's a curve in finance that most investors get wrong.
It's called the efficient frontier.
Markowitz defined it in 1952.
Most investors still don't understand what it means in practice.
Here's what they get wrong: