For full technical details + compliance Datasheet see our preprint @ https://t.co/rLPIMCNhqW
As for German-specific models trained on this data... stay tuned 👀
We just released "German Commons", the largest openly-licensed German text dataset for LLM training: 154B tokens with clear usage rights for research and commercial use. https://t.co/FWmDdd4p2j
Come join us at the poster session at ICTIR 2025 to discuss:
- Axioms for Retrieval-Augmented Generation https://t.co/eDmCHt07fc
- Learning Effective Representations for Retrieval Using Self-Distillation with Adaptive Relevance Margins https://t.co/8gt8EAUpBQ
Honored to win the ICTIR Best Paper Honorable Mention Award for "Axioms for Retrieval-Augmented Generation"!
Our new axioms are integrated with ir_axioms: https://t.co/T6i9S324Fh
Nice to see axiomatic IR gaining momentum.
Happy to share that our paper "The Viability of Crowdsourcing for RAG Evaluation" received the Best Paper Honourable Mention at #SIGIR2025! Very grateful to the community for recognizing our work on improving RAG evaluation.
📄 https://t.co/kG75fYl17H
Do not forget to participate in the #TREC2025 Tip-of-the-Tongue (ToT) Track :)
The corpus and baselines (with run files) are now available and easily accessible via the ir_datasets API and the HuggingFace Datasets API.
More details are available at: https://t.co/VKM5P4ELcT
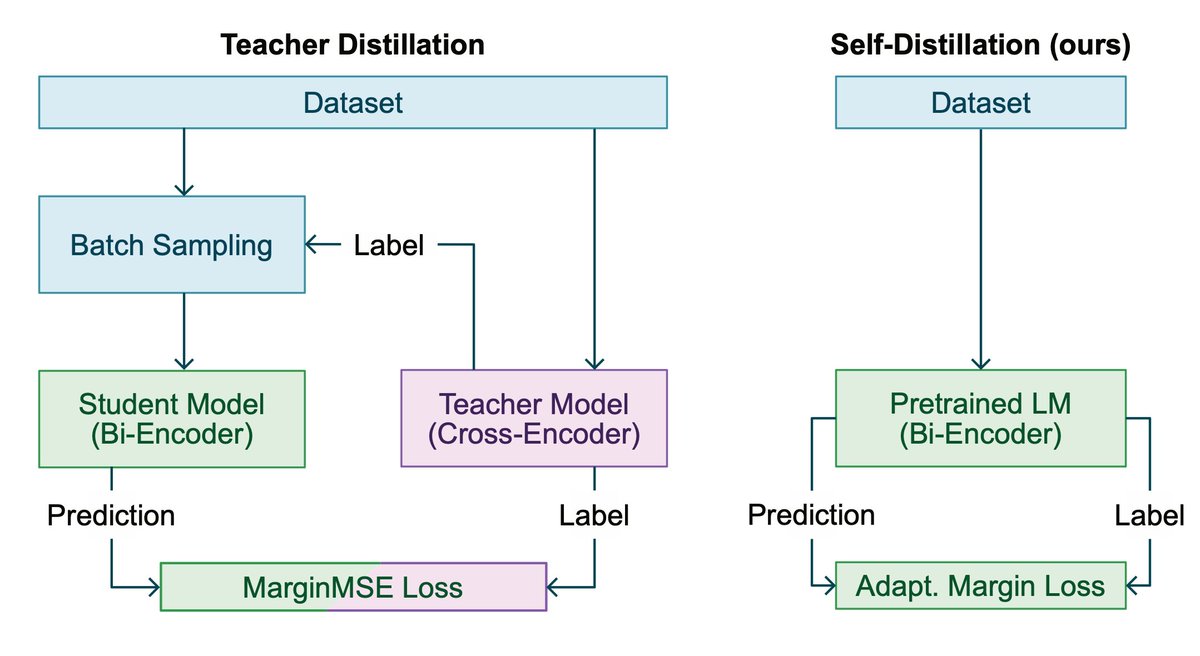
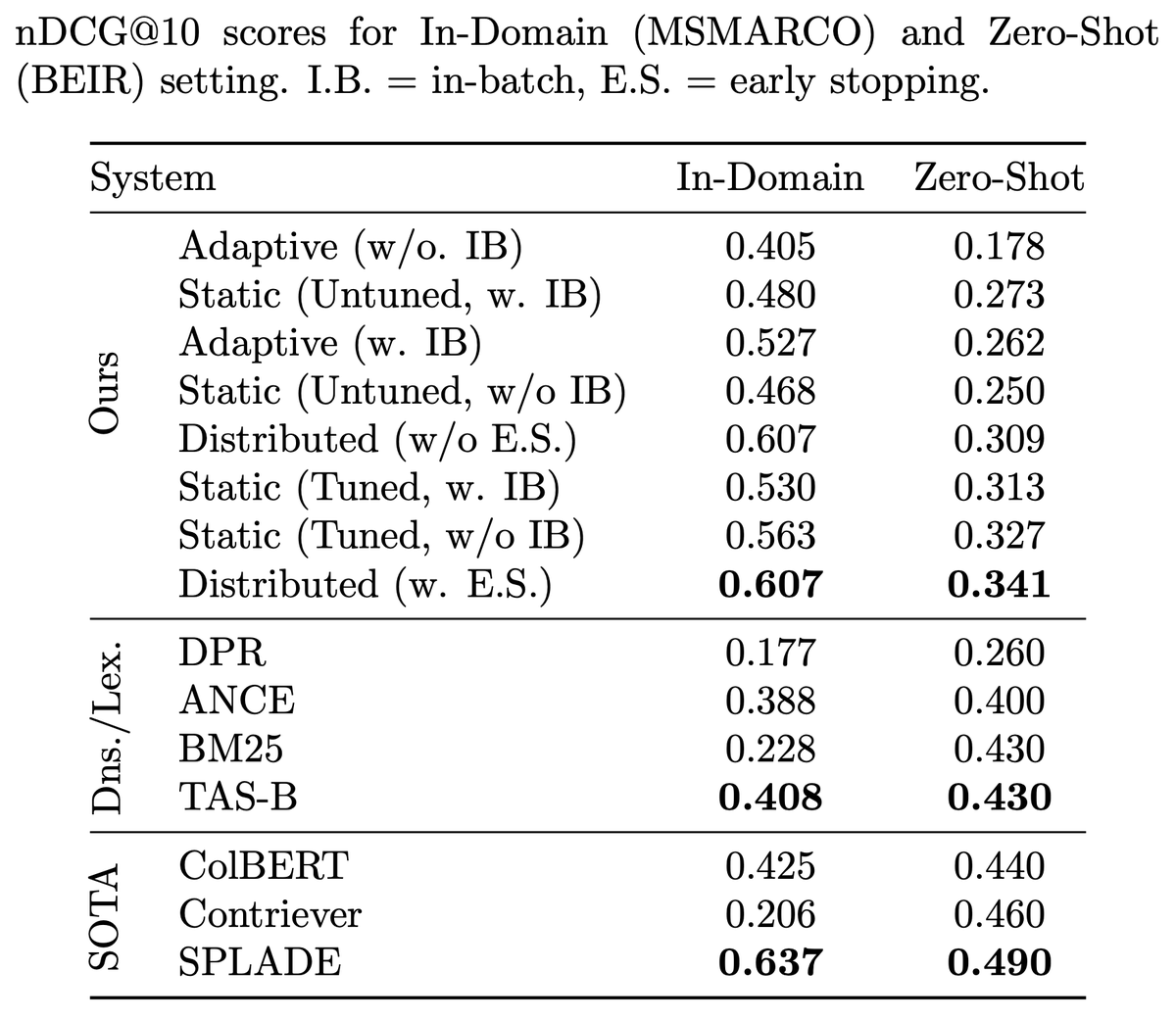
Our paper on self-distillation for training bi-encoders got accepted at #ICTIR2025! By exploiting pretrained encoder capabilities, our approach eliminates expensive teacher models and batch sampling while maintaining the same effectiveness.
Results on BEIR demonstrate that our method matches teacher distillation effectiveness, while using only 13.5% of the data and achieving 3-15x training speedup. This makes effective bi-encoder training more accessible, especially for low-resource settings.