🚀 New paper from my internship at @Google!
LLMs can “think” for a long time only to get the answer wrong — more tokens do not always help and may be overthinking 😵💫
We introduce Deep-Thinking Ratio (DTR), a new way to measure LLM reasoning effort.
The idea: Count the tokens models had to think deeply to produce.
🧵
🎉 Honored to receive the @CapitalOne PhD Fellowship!
Many thanks to my advisor @yumeng0818 and my collaborators for their guidance and support throughout my PhD journey at @CS_UVA@UVAEngineers! 💙🧡
Excited to continue building more capable, reliable, and efficient AI systems!
https://t.co/LJzPFsFiz5
😢RLVR is powerful but expensive
🤯Imagine using <20% RLVR training while achieving 100% performance?
Sounds surprising? We show that minimal RLVR training is enough to know where training is going, and predict future ckpts at no training cost!
📃https://t.co/fGODWWIjR1
🧵[1/n]
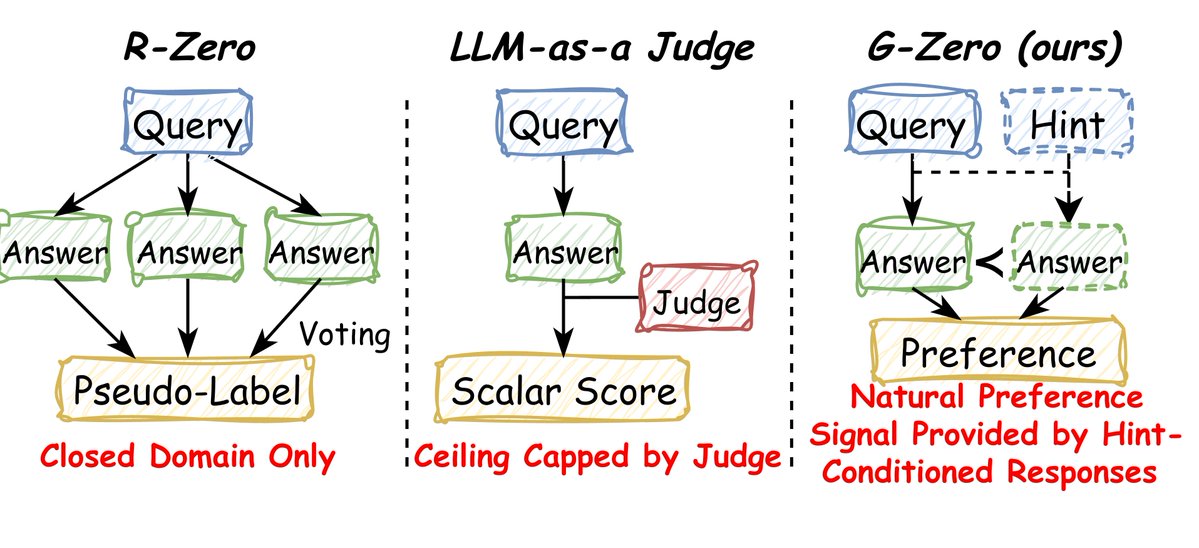
"How do you self-improve a model on open-ended tasks where you can't take a majority vote?"
I got asked this in nearly every research interview I did last year. None of my answers felt clean.
So we built something that doesn't need a vote, a verifier, or a judge.
Meet G-Zero. 👇
paper: https://t.co/TrvGb48W4d
huggingface: https://t.co/8guc5xSh3i
code: https://t.co/G8mMm2I9h1
All experiments are done via api by @thinkymachines (1/n)
🎉TruthRL is accepted to #ICML2026!
A simple ternary reward (correct: +1; abstention: 0; incorrect: −1) helps LLMs answer more accurately and know when not to answer, significantly reducing hallucinations!
Paper + code 👇
📄 https://t.co/OXPYb08PJz
💻 https://t.co/bjySx2EA2u
🚨 New paper 🚨
Excited to share our new work on EvoSkill (led by @salahalzubi401), a self-evolving framework that automatically discovers and refines agent skills through iterative failure analysis 🔁🧬. It achieves state-of-the-art performance on @databricks's OfficeQA. Check it out!
📰: https://t.co/jbBbQLUm51
🚨 New paper 🚨
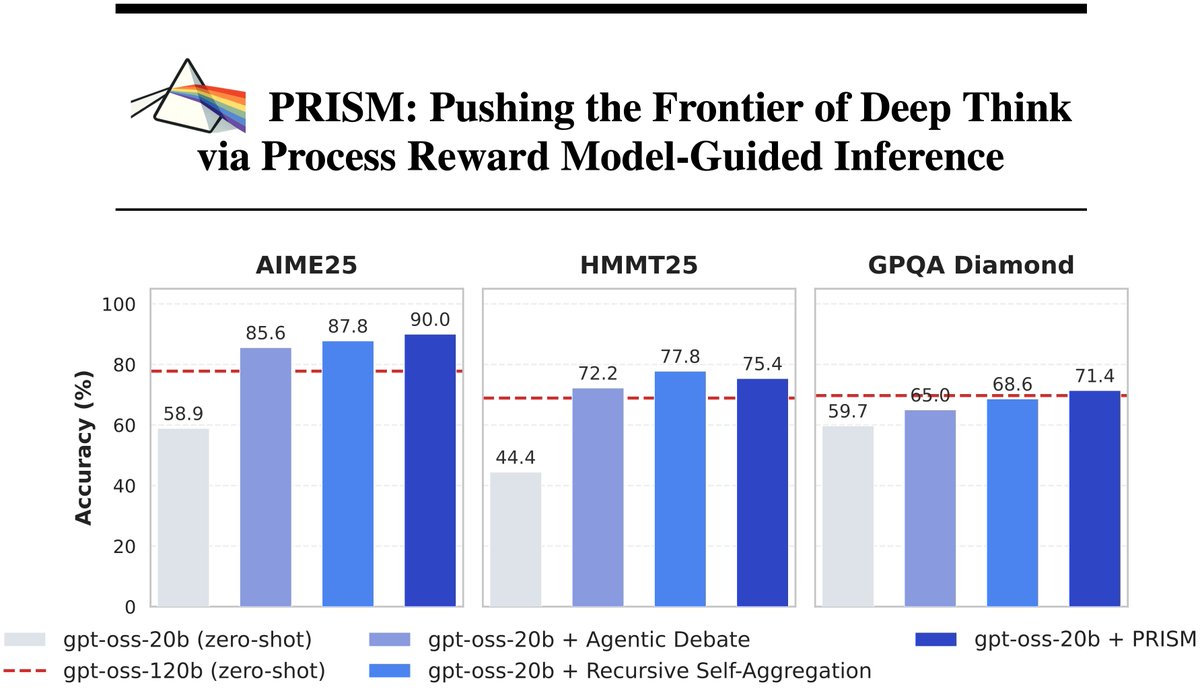
Excited to share PRISM, a new “DeepThink” method that uses step-level correctness signals from a process reward model to guide inference over candidate solutions. PRISM matches or beats SOTA methods, enabling gpt-oss-20b to exceed gpt-oss-120b.👇
📰: https://t.co/hdjXZ3PjJJ
#AI #LLMs
Excited to share this new work from @Google! 🚀
Our intern @WeiLin__Chen explored how to measure true LLM reasoning effort. We found that "longer" isn't always "smarter"—it's about the Deep-Thinking Ratio (DTR). 🧠📊
Check out the full paper below! 👇
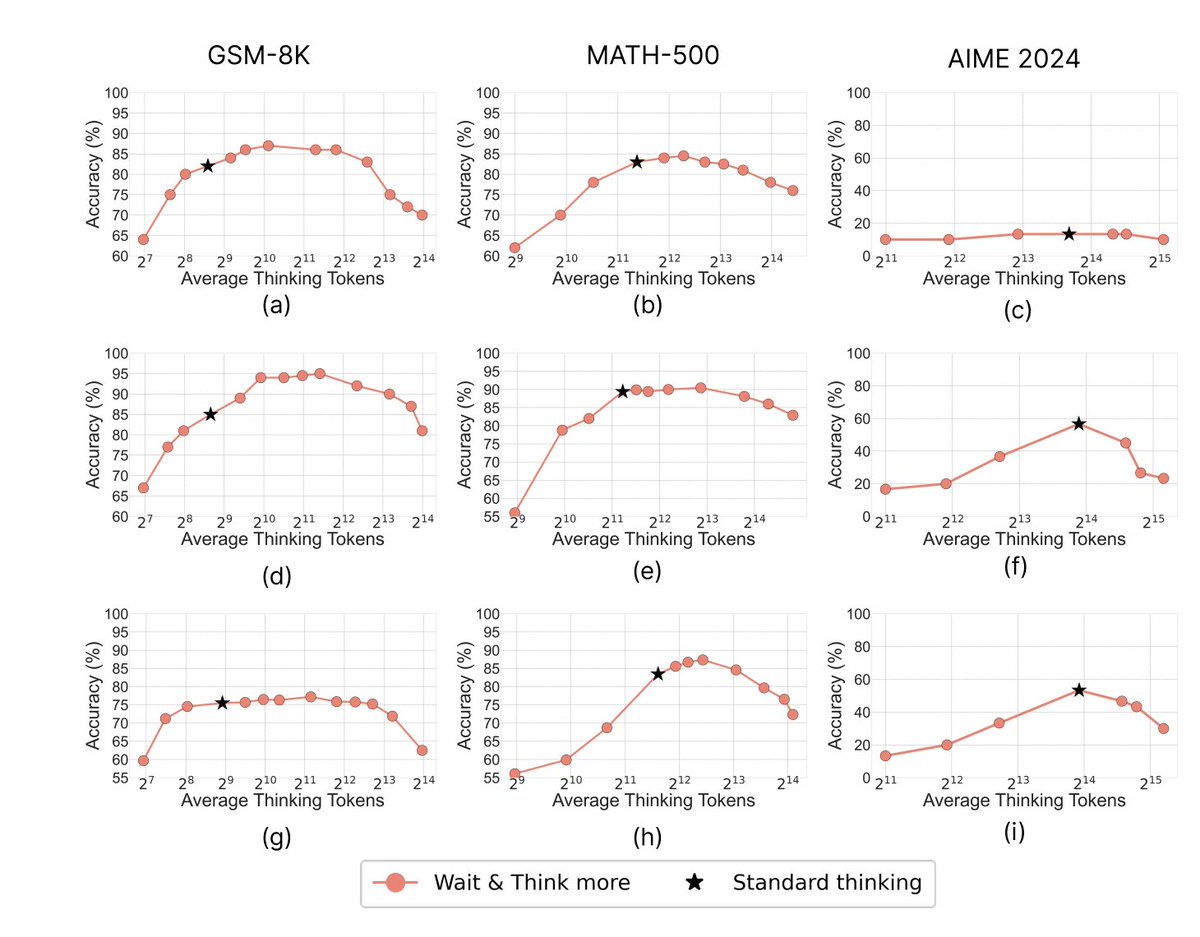
🔥 Does test-time scaling in #reasoningmodels via thinking more always help?
🚫 Answer is No - Performance increases first and then drops due to #Overthinking
❓Why is this behaviour and how to mitigate
🚀 Check our recent findings #LLMReasoning
Link: https://t.co/V0IOoFqAgY
🚀 New paper from my internship at @Google!
LLMs can “think” for a long time only to get the answer wrong — more tokens do not always help and may be overthinking 😵💫
We introduce Deep-Thinking Ratio (DTR), a new way to measure LLM reasoning effort.
The idea: Count the tokens models had to think deeply to produce.
🧵
New Google paper challenges how we measure LLM reasoning.
Token count is a poor proxy for actual reasoning quality.
There might be a better way to measure this.
This work introduces "deep-thinking tokens," a metric that identifies tokens where internal model predictions shift significantly across deeper layers before stabilizing.
These tokens capture "genuine reasoning" effort rather than verbose output.
Instead of measuring how much a model writes, measure how hard it's actually thinking at each step. Deep-thinking tokens are identified by tracking prediction instability across transformer layers during inference.
The ratio of deep-thinking tokens correlates more reliably with accuracy than token count or confidence metrics across mathematical and scientific benchmarks (AIME 24/25, HMMT 25, GPQA-diamond), tested on DeepSeek-R1, Qwen3, and GPT-OSS.
They also introduce Think@n, a test-time compute strategy that prioritizes samples with high deep-thinking ratios while early-rejecting low-quality partial outputs, reducing cost without sacrificing performance.
Why does it matter?
As inference-time scaling becomes a primary lever for improving model performance, we need better signals than token length to understand when a model is actually reasoning versus just rambling.
Paper: https://t.co/Yj0bPdiLni
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
New Google paper challenges how we measure LLM reasoning.
Token count is a poor proxy for actual reasoning quality.
There might be a better way to measure this.
This work introduces "deep-thinking tokens," a metric that identifies tokens where internal model predictions shift significantly across deeper layers before stabilizing.
These tokens capture "genuine reasoning" effort rather than verbose output.
Instead of measuring how much a model writes, measure how hard it's actually thinking at each step. Deep-thinking tokens are identified by tracking prediction instability across transformer layers during inference.
The ratio of deep-thinking tokens correlates more reliably with accuracy than token count or confidence metrics across mathematical and scientific benchmarks (AIME 24/25, HMMT 25, GPQA-diamond), tested on DeepSeek-R1, Qwen3, and GPT-OSS.
They also introduce Think@n, a test-time compute strategy that prioritizes samples with high deep-thinking ratios while early-rejecting low-quality partial outputs, reducing cost without sacrificing performance.
Why does it matter?
As inference-time scaling becomes a primary lever for improving model performance, we need better signals than token length to understand when a model is actually reasoning versus just rambling.
Paper: https://t.co/Yj0bPdiLni
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Is your reasoning LLM actually making progress or just wasting compute?🧐
Excited to share our new preprint led by @WeiLin__Chen! 🤩
We propose a new metric to measure how "deep" LLMs think at each token by identifying internal layer revisions.
This correlates much better with accuracy than raw token counts and enables superior & efficient test-time scaling! 📈















![weizhepei's tweet photo. 😢RLVR is powerful but expensive
🤯Imagine using <20% RLVR training while achieving 100% performance?
Sounds surprising? We show that minimal RLVR training is enough to know where training is going, and predict future ckpts at no training cost!
📃https://t.co/fGODWWIjR1
🧵[1/n] https://t.co/pfnnjK3xxd](https://pbs.twimg.com/media/HITt6ixX0AE1OPu.jpg)