A YouTuber with 110 million subscribers released a free version of ChatGPT.
His name is Felix Kjellberg. You know him as PewDiePie.
He spent his own money on a 10-GPU computer at home. He used it to run the same kind of AI models that power ChatGPT, but on his own hardware. Then he wrote his own app to chat with them, because the apps that already exist were not good enough.
Then he gave it away for free. Anyone can download it. Anyone can change it. Anyone can run it.
It's called Odysseus.
It runs on your computer. Your data stays on your disk. No account. No tracking. No monthly fee.
What you get:
- A chat window like ChatGPT
- An AI assistant that can browse the web, read your files, and do tasks for you
- A tool that scans your computer and tells you which AI models will work on it
- A research mode that reads many websites and writes you a report
- A side-by-side mode to test two AI models on the same question
- A writing editor where AI helps you, instead of writing for you
- Memory, so the AI remembers your past chats
- Email with AI that sorts your inbox and writes replies for you
- Notes, a to-do list, and a calendar
- Works on your phone too
23,612 stars on GitHub in 2 days. Top of trending all weekend.
ChatGPT Plus costs $20 a month. Claude Pro costs $20 a month. PewDiePie's version costs nothing, runs on your own computer, and the code is open for anyone to read.
This is what AI looked like before the subscription model.
(Link in the comments)
A 22-year-old graduate student in Kazakhstan got so angry at journal paywalls in 2011 that she built a pirate website holding 88 million scientific papers, and last month she turned the whole thing into an AI that lets you ask one question and get the actual research as the answer.
Her name is Alexandra Elbakyan, and the website is called Sci-Hub.
The AI she just launched is called Sci-Bot. It lives at https://t.co/6w0IBtOEYB and almost nobody outside academia knows it exists yet.
Here is the story, because it is one of the strangest things to happen in science publishing in the last 50 years.
Elbakyan was born in Almaty in 1988, the year the Soviet Union started to collapse. She taught herself programming at 12. She read Soviet science books that explained things her family used to call miracles. She got into computer security at university and graduated in 2009 with a degree she barely needed because by then she was already a serious hacker.
Alexandra moved to Moscow that fall. Then Germany. Then a research internship in the United States. She was working on brain-computer interfaces, the kind of research that requires you to read hundreds of papers a year just to keep up with the field.
And every single one of those papers was locked behind a journal paywall that cost between 30 and 50 dollars to read once.
She did the math. A graduate student in Kazakhstan could not afford to read science.
The first thing she did was learn how to get around the paywalls one paper at a time. She passed the trick around to other students. They asked her for papers constantly. She got tired of doing it manually.
So in September 2011, in three days, she wrote a script that automated the whole thing. A user pastes a DOI. The script logs in through a donated institutional credential. The paper comes back free. The website caches it.
The next person who asks for that paper gets it instantly because the previous request already saved a copy.
That was Sci-Hub. Three days of code. One graduate student. Done.
15 years later, the cache holds 88 million scientific papers. Almost every piece of scholarly literature published before 2020 is sitting on her servers. Researchers in 190 countries use it. Studies in Nature have shown that roughly half of all academic paper downloads worldwide now go through Sci-Hub, not the publishers who actually own the copyrights.
Elsevier sued her in 2015 and won a 15 million dollar judgment. She did not pay. The American Chemical Society sued her and won an injunction. She did not comply. Courts in India, France, Russia, and the UK have tried to block the domain. She just moves it. https://t.co/3sAWJzNe8I. https://t.co/tGIETesZ8i. https://t.co/H5WQ1f9lqR. The site has had over 20 domains and is still up.
Nature put her on its list of the 10 people who mattered most to science in 2016. The New York Times compared her to Edward Snowden. The Verge called her the pirate queen of science.
She has not been to the United States in over a decade because she would be arrested at the airport.
The Sci-Bot launch in April 2026 is the part that nobody is talking about.
She took the 88 million paper database and put a small language model on top of it. You ask a question in plain English. The model searches the entire shadow library, pulls the relevant papers, synthesizes an answer grounded in real citations, and links you to the full text of every source. Free. No login. No institutional credential. No paywall.
Three real scientists tested it for a Chemical and Engineering News article last month. They asked it medical and chemistry questions. The radiologist said the answer he got was usable. The chemist said the gaps in recent literature were obvious but the older science was solid. The publisher community is furious.
What she built is what the paid academic AI tools are trying to build. Except the paid ones are limited to what their parent publisher legally owns. Hers is limited to almost nothing.
Alexandra still lives somewhere in Russia. She does not give her address. She does not do video interviews. She gives talks over Skype with the camera off. She runs the largest illegal library in human history from a laptop and a donation page.
A graduate student who could not afford to read science built the system the entire scientific community now quietly depends on.
The publishers have spent a decade trying to shut her down.
She just shipped an AI that makes their entire business model outdated.
🧩 Mephisto — a scanner and exploitation framework for WordPress vulnerabilities
A tool for automated detection and exploitation of known (CVE) vulnerabilities in WordPress.
Features:
📍 Support for typical modules targeting plugin and theme exploits.
📍 Generation of reports on detected and exploited vulnerabilities.
📍 CLI interface with options for test configuration and customization.
Unlike "WPScan" and "CMSmap", it focuses not only on information gathering but also on practical CVE exploitation.
📎 Tool: https://t.co/NTpCao16pJ
#dbugs_tools
A team in San Francisco killed Perplexity's $20/month subscription.
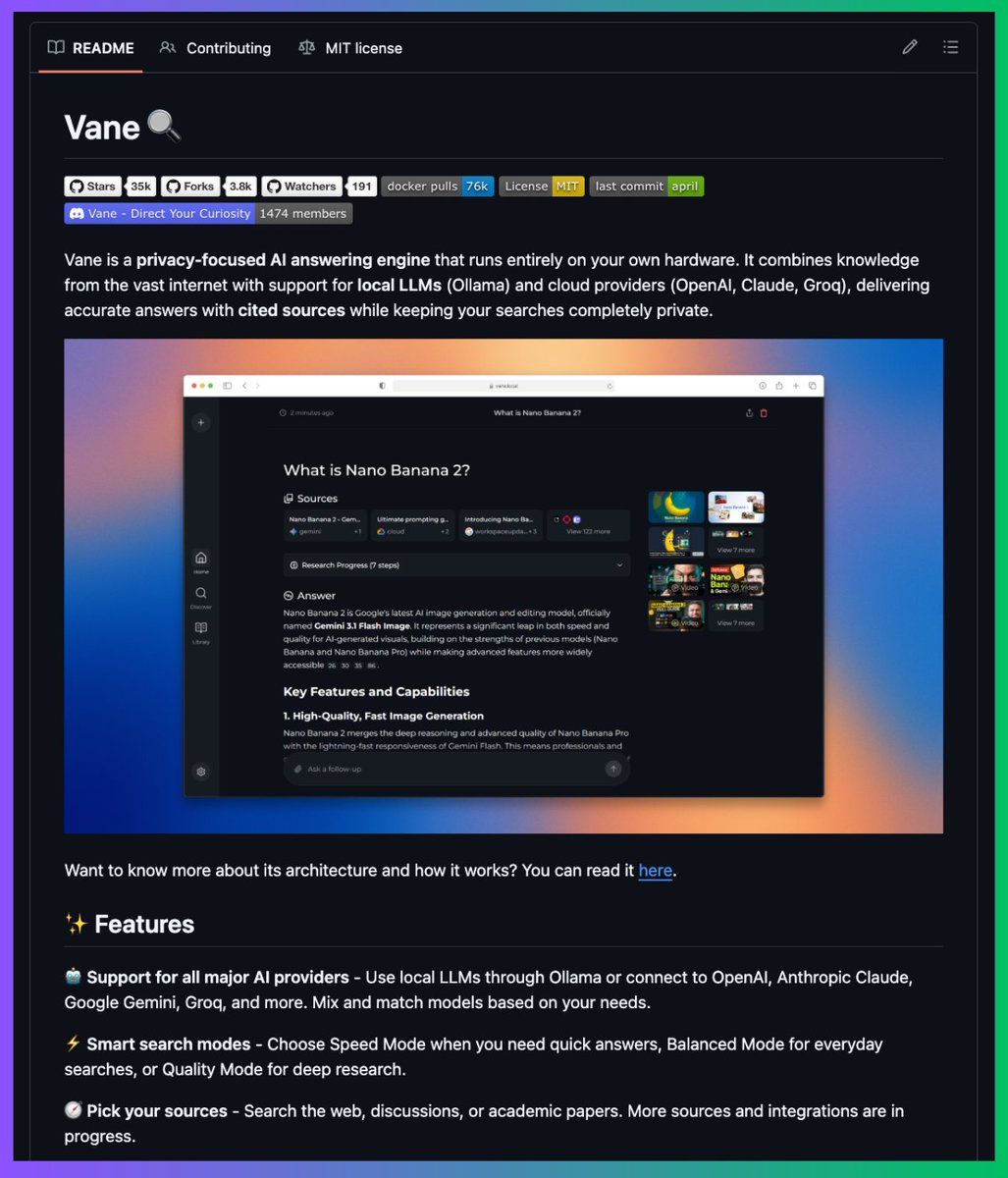
It's called Vane. You get AI-powered search with cited sources, follow-up questions, image and video search, and focus modes for academic papers, Reddit, YouTube, and Wolfram Alpha, running entirely on your own machine.
Here's how it works.
Vane is an open-source clone of Perplexity built on top of SearxNG which is a meta-search engine that pulls results from Google, Bing, DuckDuckGo, Brave and 70+ other sources without tracking the user. You plug in any LLM you want including OpenAI, Anthropic, Groq or local models through Ollama and it answers your questions with real citations pulled from the live web in real time.
The entire stack can run 100% locally with Llama 3 and SearxNG on your own hardware which means zero API calls going out and zero data ever leaving your machine.
→ No $20/month Pro subscription holding the good models hostage
→ No query limits cutting you off mid-research
→ No tracking and no profile being built from your searches
→ Local mode with Ollama supporting Llama, Mistral, Qwen and anything else you throw at it
→ Focus modes that narrow the search to Academic papers, YouTube, Reddit, Wolfram Alpha or Writing
→ Image and video search built directly into the interface
→ Copilot mode that breaks one question into multi-step research and synthesizes the findings
Perplexity charges $20 a month for Pro and trains its ranking algorithm on every query you send them. Their entire business model assumes you would never spend an evening with a Docker compose file and a local LLM.
Vane runs in one container and SearxNG runs in another and the whole thing points at a Llama 3 model running on your laptop with no internet account involved anywhere in the chain.
MIT License. 100% Opensource.
https://t.co/rg17qIjsH3
Two Bulgarian friends killed the entire streaming industry.
It's called Stremio + Torrentio. You get 4K content from Netflix, Disney+, Hulu, and HBO Max combined for free.
Here's how it works.
Stremio is the player. Clean interface. Works on Windows, macOS, Linux, Android, iOS, and TV. You install it once and it looks like any other streaming app.
Torrentio is the addon. You add it to Stremio in one click. It scrapes content from every major torrent provider on the internet simultaneously and delivers the best available stream directly to your player. 720p, 1080p, 4K. You pick the quality. It finds the link.
→ No account required
→ No subscription
→ Works on every device
→ 4K and HDR supported
→ Subtitles built in
Netflix cannot shut this down. There is no central server to seize. No company to pressure. No domain to kill. It runs on your device and pulls from the open internet.
The entire streaming industry is built on one assumption. That you will keep paying $70/month rather than spend 5 minutes on GitHub.
That assumption just died in Sofia, Bulgaria.
MIT License. 100% Opensource.
https://t.co/yEljDh5DQy
Get the addon here: https://t.co/XhpPDERP2i
10 GitHub repos that should be illegal — they're killing $50 billion in corporate revenue.
SAVE IT
1. yt-dlp
Downloads any video from YouTube, X, TikTok, Instagram, anywhere. YouTube Premium charges $14 a month to do less than this. It is 100% free.
Repo → https://t.co/TaRtkcd4qy
2. Ollama
Run GPT-4-class AI on your laptop. No API costs. Developers spend $500 a month on OpenAI for what Ollama runs offline for $0.
Repo → https://t.co/gyZhUdzsnZ
3. Fooocus
Midjourney-quality image generation on your own GPU. Midjourney charges $30 a month. Fooocus runs unlimited generations for free.
Repo → https://t.co/NDPJpIdYJs
4. Whisper
OpenAI's transcription model, open-sourced. Otter charges $20 a month for what Whisper does for free, in 99 languages.
Repo → https://t.co/blaJ4i4MnH
5. Plausible Analytics
Privacy-first Google Analytics replacement. Google Analytics 360 costs $150,000 a year for enterprises. Plausible self-hosted costs $0.
Repo → https://t.co/RFrcpqTBQ7
6. AppFlowy
Open-source Notion. Notion charges $20 per user per month for teams. AppFlowy runs unlimited users on your server for free.
Repo → https://t.co/IDMykTCkMU
7. Penpot
Open-source Figma. Figma charges $45 per editor per month. Penpot does the same job, self-hosted, free forever.
Repo → https://t.co/Lx1CYUP4p4
8. n8n
Open-source Zapier. Zapier Pro costs $600 a month for a real workflow. n8n self-hosted runs unlimited automations for $0.
Repo → https://t.co/hdycABGGc1
9. Cal .com
Open-source Calendly. Calendly Teams costs $16 per user per month. Cal. com is free for individuals and open source for teams.
Repo → https://t.co/haz8ihRsHm
10. Bitwarden
Open-source 1Password. Password managers charge $8 per user. Bitwarden is unlimited, forever, free.
Repo → https://t.co/XCZ2JtWqWQ
Here's the wildest part:
That's $50 billion in corporate revenue these repos are quietly destroying every single year.
None of these are illegal.
All of them should be.
Save this. Share it with the person in your life still paying for what's been free this whole time.
100% free. 100% open source.
▪️We have jailed former senior IPS Officer Sajeev Bhatt, students activists Umar Khalid, Sharjil Imam without trial, by “following rules wherever it is”.
▪️We incarcerated transparency activists, professors, Jesuit father in Bhima Koregaon case, by “following rules wherever it is”.
▪️We have inducted murderers, rioters, in our Cabinets, by “following rules wherever it is”.
▪️We arrested Muslim youths after Mumbai train bomb blasts in 2006, only to find them innocent after 19 years of judicial trials, by “following rules wherever it is.”
▪️We have allowed the National Crony to raise monies on foreign stock exchanges, “following rules wherever it is.”
▪️We have allowed our Prime Minister to not take any Press Conference, not take questions of members in the Parliament, leave Parliament when opposition members are speaking, raise a Private Fund using Government resources, appoint an 80+ year old NSA, visit a sitting CJI under the garb of religion, by “following rules wherever it is.”
▪️We have destroyed the Trees, Mangroves and Nature for corrupt schemes and crony’s profits, by “following rules wherever it is.”
▪️We have disenfranchised lakhs of Muslims by inventing own ‘Special’ Rules and bulldozing them down the citizenry, under the watch of judiciary, by “following rules wherever it is.”
P.S. - Rules = Manusmriti, not necessarily the Constitution.
Here's the PoC for Nginx CVE-2026-42945 which works against vanilla Ubuntu (and any other distro?) + Nginx with ASLR enabled. I have included all iterations of the PoC the LLM was kicked to improve.
TL;DR: We can use an LFI/file-read primitive to leak enough details from /proc/<nginx-worker>/mem to bypass ASLR and achieve reliable RCE, in most cases at first shot.
There are still other ways to make it work, with even less subtle primitives. If you ask Geppetto nicely, he will help you ;)
https://t.co/VawjqrMisN
An Indian engineer built a $5.6 billion company's biggest threat.
He named it after his dog.
The company is Postman. The threat is Bruno. A free open-source API client that works offline, lives in your git repo, and never asks you to make a cloud account.
Postman vs Bruno:
- Price: $14 to $49 per user per month → $0
- Account: Cloud login required → No login, ever
- Where files live: Postman's servers → Your git repo
- Offline mode: Removed in 2024 → Built in from day one
- Privacy: 30,000 public collections leaked API keys in plaintext last year → Files stay on your laptop
No cloud. No account. No sync. No telemetry.
How does it work?
→ One small app. Mac, Windows, Linux.
→ Your API calls are saved as plain text files in your own folder.
→ Commit them to git like any other code.
→ Your team pulls the repo. They have the same APIs. Done.
→ No "workspace" to share. No seat licenses. No upgrade nags.
43,818 stars. 2,403 forks. 446 people from around the world helping build it.
One honest note: license is MIT. Free for personal work, paid client work, your own forks. No "Pro" tier hiding behind it.
Anoop M D built Bruno from Bengaluru three years ago. He wanted a free offline API tool. None existed. So he made one and named it after his dog because, in his words, "I love him the most."
A ₹5 lakh grant. One man. 500,000 developers now using it.
This is what Postman should have been from the start.
(Link in the comments)
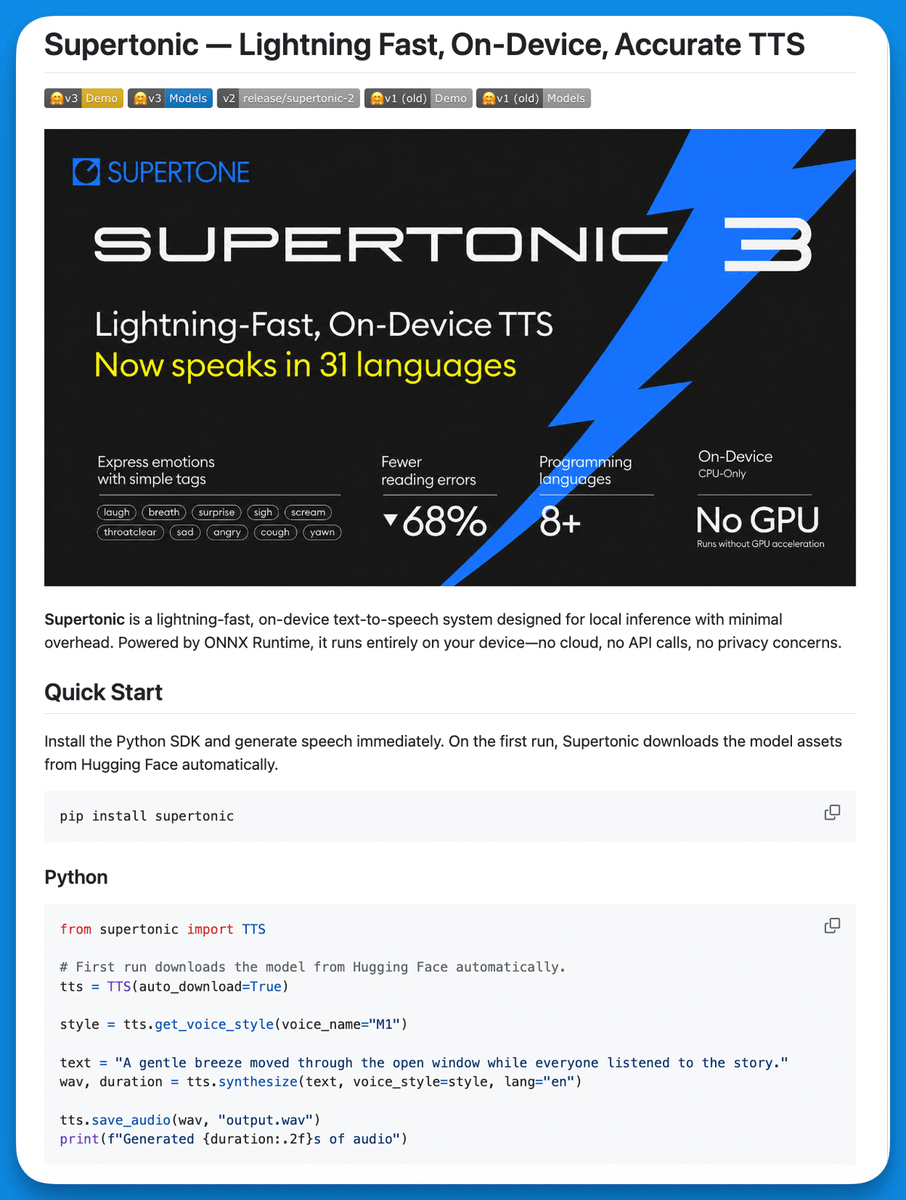
this TTS model generates speech 167x faster than you can hear it.
Supertonic is an on-device TTS engine that runs via ONNX for cross-platform inference.
- no GPU
- 31 languages
- captures every emotion
- beats ElevenLabs on speed
- runs even on a Raspberry Pi
100% open-source.
Supertonic just killed ElevenLabs.
A text-to-speech model that runs entirely on your device. No cloud. No API key. No per-character pricing.
2,700 GitHub stars. 100% open source. MIT licensed.
The numbers are wild:
→ 167x faster than real-time on an M4 Pro
→ Only 66M parameters
→ 1,263 chars/sec vs ElevenLabs Flash at 287
→ 1,048 chars/sec vs OpenAI TTS-1 at 55
→ Runs on a Raspberry Pi. Runs on an e-reader in airplane mode.
Reads currency, dates, phone numbers, and technical units correctly without preprocessing. ElevenLabs fails these. OpenAI fails these. Gemini fails these.
Supports 11 platforms and 5 languages. Chrome extension turns any webpage into audio in under a second.
I've watched on-device models lose to cloud APIs for years. This one doesn't lose.
The cloud TTS business just got cooked.
Holy shit. An Indian solo dev built the one terminal tool every developer has been missing for 20 years.
It's called witr. It answers one question your OS refuses to answer:
Why is this running?
You see a weird process eating your RAM. You see a port that should not be open. You see a service you do not remember installing. Every tool tells you it exists. None of them tell you why it exists.
ps shows you the process. lsof shows you the port. systemctl shows you the service. But none of them show you the chain. The shell that spawned the supervisor that started the daemon that opened the socket.
witr does.
You type one command. It traces the whole causality. From kernel to PID to parent process to the launchd job or systemd unit that started it. From the open port back to the binary that bound it. From the service back to the user shell that triggered it.
The thing your OS hides, witr surfaces in plain English.
Here is what makes it different from every "process viewer" before this:
→ Traces full causality chains, not just PIDs and ports
→ Interactive TUI dashboard, not a wall of text
→ Single static Go binary, installs in 5 seconds
→ Works on Linux, macOS, Windows, and FreeBSD natively
→ Already packaged on brew, conda, AUR, winget, npm, scoop, chocolatey, FreeBSD ports, and 6 more
→ Detects supervisor chains, container parents, and systemd unit ancestry
→ Flags processes listening on public interfaces or running from suspicious working directories
→ Spots memory hogs and processes that have been running silently for months
Killed: every "what is this process" Stack Overflow rabbit hole, every Reddit thread asking "why is my Mac running this", and every PowerShell one-liner you copied from a 2014 forum post.
15,104 stars in 5 months. 401 forks. 34 contributors. 18 releases. Apache-2.0.
Pranshu Parmar shipped this from his laptop. No VC. No team. No accelerator.
Your OS finally tells you the truth.
(Link in the comments)
⚡ PSSW100AVB ⚡— PowerShell Scripts With 100% AV Bypass
PowerShell payloads built for AV evasion and red team research.
Includes:
• Reverse shells
• Obfuscation techniques
• Sandbox bypass concepts
• AI/behavior-analysis evasion experiments
Focuses on how modern payloads attempt to bypass antivirus and EDR detection mechanisms.
https://t.co/HKMw5U1YFk
#CyberSecurity #RedTeam #PowerShell #MalwareAnalysis
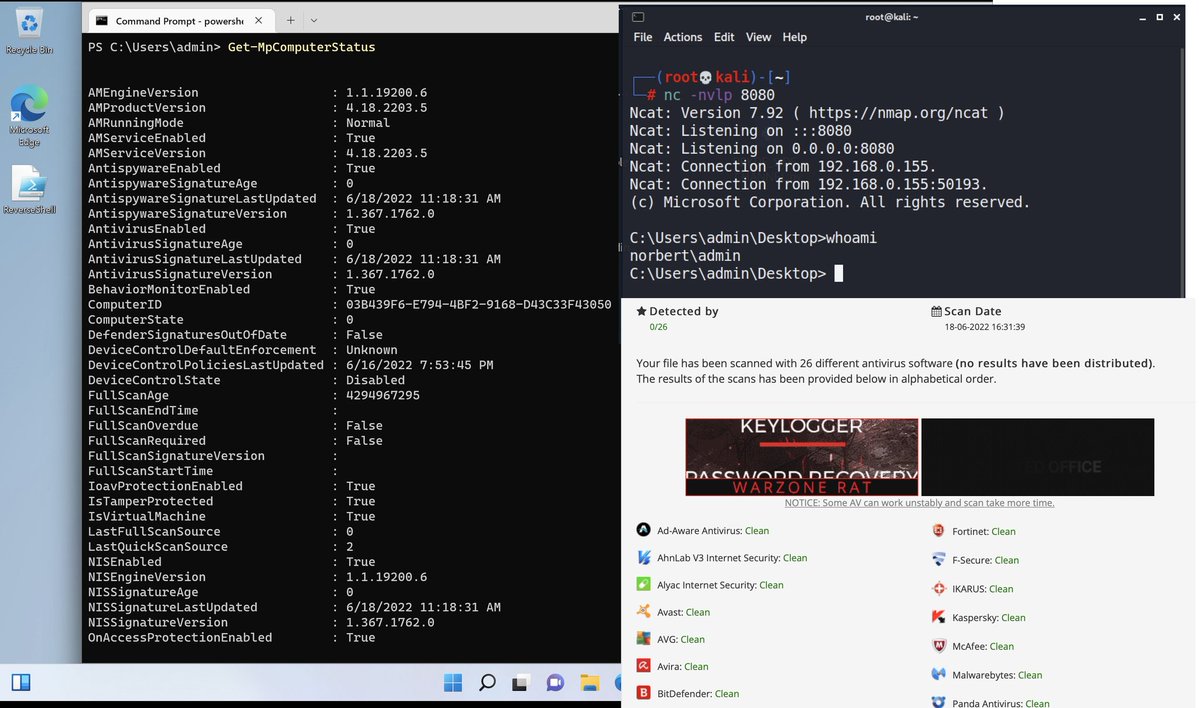
‼️🚨 One of the world's largest Certificate Authorities, DigiCert, was compromised by a malicious screensaver file sent through a customer support chat. Their antivirus blocked the malware four times. The agent kept clicking. The fifth try got through.
27 code signing certificates were stolen and used to sign malware.
DigiCert ultimately revoked 60 certificates.
Per DigiCert's incident report, filed in Mozilla's CA compliance tracker as Bug 2033170, here is how it unfolded:
April 2: an attacker contacted a DigiCert helpdesk agent through the company's customer support chat channel, posing as a customer. The lure was a zip file pitched as a screenshot. Inside the zip was a .scr file. On Windows, .scr files are executables, and this one carried a malicious payload.
Opening a file a customer sent through the official support channel is what an agent is supposed to do. Support staff are the one role designed to accept files from strangers.
DigiCert's endpoint security blocked four infection attempts. On the fifth, the support analyst's machine was infected.
DigiCert detected the infection, ran an investigation, and concluded the incident was contained.
Eleven days later, an external researcher tipped DigiCert off about misuse of DigiCert-issued code signing certificates in the wild. That tip led to the discovery of a second compromised machine, belonging to a different support analyst, infected through the same vector. The EDR on that machine had not been functioning correctly, so the original investigation missed it.
The second machine gave the attacker access to DigiCert's internal support portal. That portal lets support staff reach limited views of customer accounts, including initialization codes for ordered but not-yet-issued code signing certificates. Combining a stolen initialization code with an approved order let the attacker pull a real, validly issued code signing certificate. They did this 27 times.
DigiCert's own list of what went wrong:
- File-type filtering on the customer support chat channel did not catch the .scr
- EDR coverage was inconsistent and incomplete, creating a blind spot
- Initialization codes for code signing certificates were not adequately protected
DigiCert says it got lucky. An outside researcher found the malware abuse before DigiCert did. Without that tip, the second machine and the active certificate theft might still be running today.