Angular 22 is released today, and we have an "Angular 22 celebration discount".
Our Modern #Angular Testing workshop takes place next week and will already include the relevant Angular 22 testing updates.
12% off with CGNE4E5G
https://t.co/4UxACvAGJF
llama.cpp now has an official website: https://t.co/vztdUpdBWL
Our goal is to make local AI accessible to everyone, and improving the user experience is a big part of that. On the new landing page you’ll find a single-line cross-platform installer. The installation provides a single unified `llama` entrypoint which you can use to run/serve models and interface with 3rd-party agentic applications.
While oriented towards simplified user experience, the new `llama` application also provides all the advanced functionality of the existing llama.cpp tooling with which experienced users are already familiar. Also note that all GGUF models that you might have already downloaded with llama.cpp in the past will be automatically available to use without downloading again (they are stored in the common HF cache on your machine).
We have many improvements in the pipeline both at the UX and at the engine level and we plan to iteratively ship new things over the coming months. One of the main focuses will be seamless integration with local-friendly 3rd-party agents (such as Pi). In the meantime, we’ll continue to listen for feedback from the community and adjust accordingly, so keep letting us know what you think and need.
I've got an agent in a loop optimizing a renderer with the goal to minimize frame times (and tests to measure). It got times down from 88ms to 2ms and allocations down from ~150K to 500. Sounds good, right? Wrong. This is exactly why agent psychosis is a big fucking problem.
As an experiment, I rewrote the Ghostty core render state in Go, with access to identically laid out data structures as Ghostty and the exact same validation tests. I made a purposely naive renderer (simple, correct, but slow). 88ms per frame with 150,000 allocations (horrendous, lol)!
I then kickstarted a Ralph loop to bring the frame times down. I told it it can't modify input data structures or the public API or tests (they're correct), but it can do anything else it wants. It got to work.
It has worked for about 4 hours. I've spent around $350 on this experiment so far. The results?
88ms => 1.5ms
150K allocs => ~500 allocs
Incredible right? Nope.
My hand-written renderer I ported has frame times (same benchmark) of ~20us (0.020ms) and 0 allocations in the update path.
This is the problem with psychosis and lacking systems understanding. If you don't understand the system, you're going to accept that this is an incredible result. If you understand the system, you'll see better solutions immediately and can do roughly 75x better on throughput.
The people who blindly trust agent output are in the former camp. They're sheeple, overdrinking from a fountain of mediocrity.
Standard disclaimer: I use AI all the time. I like AI. The point I'm making is to not blindly accept results. Think. Analyze. Learn.
For a long time, AI discussions were mostly about the model.
🤖 Which one is better?
📊 Which benchmark was beaten?
🚀 Which new release changed everything?
But only the model is not enough. The layer around it is just as important: That's the harness.
📖 https://t.co/O6zH0fJDF9
As teased last week, my article about harnesses has finally been published.
This is something I wanted to write for a long time.
Not just what it is, but how the term evolved and why it is so important for AI in general.
Big thanks to @wolfmanfx for the review & discussions.
@badlogicgames@threepointone hey nice project any hard requirements on the phones? I have around 50 phones (android 8) which I could donate if building sth for the neighbourhood 😅
Using @CopilotKit & Google's #A2UI with local LLMs? 🤖
Following up on our article last week, here's the fully interactive, visual dashboard showcasing our benchmarks, created by @wolfmanfx:
👉 https://t.co/d4zTsUq3jc
The 3 key takeaways from our evaluation prompts 👇 (1/4)
Welp it's official, I'm on the hunt for my next role.
I learned a lot in the past 8 months, and I'm ready to get back out there for my next role.
If you're looking for someone for devrel, I got over a decade of experience in developer relations and ready help your team!
And here’s our article for the week! 🚀
This time, we’re diving into A2UI - in my opinion, one of the most critical topics at the intersection of AI and Frontend development right now.
AI offers massive potential for UIs. The interface can be dynamically generated for each user.
A key technology is #A2UI, which is framework-agnostic.
Our new post covers:
✅ What is A2UI?
✅ How does it work?
✅ How to run it fully autonomously.
https://t.co/oJCsyZvrLz
I published a deep dive into #NgRx SignalStore extensions
For me, SignalStore's extensibility is its outstanding feature.
So I always enjoy recording videos about it. And this one is my most complete so far
https://t.co/7OrurgwTdz
RAG in a browser tab? No backend? Yes, it is possible.
@wolfmanfx spoke at AI India on "From the AI Jungle to RAG in a Tab." If you want to build full RAG pipelines that run entirely client-side for ultimate privacy and speed, the slides are live:
https://t.co/FZMInvvWG8
Our first video on AI Fundamentals is live! It’s the video version of last week’s article - covering principles, models & limitations.
It’s a deep dive (~1hr), but chaptered so you can watch in stages.
📺 https://t.co/2qTu1WL1aD
As promised last week, here’s our first article on AI.
We start at the core: the model.
What you need to know to understand how it works, its limitations, and how modern AI mitigates them.
Long read, but long weekend ahead. So you have enough time 😅
https://t.co/XvtI0dE8Hn
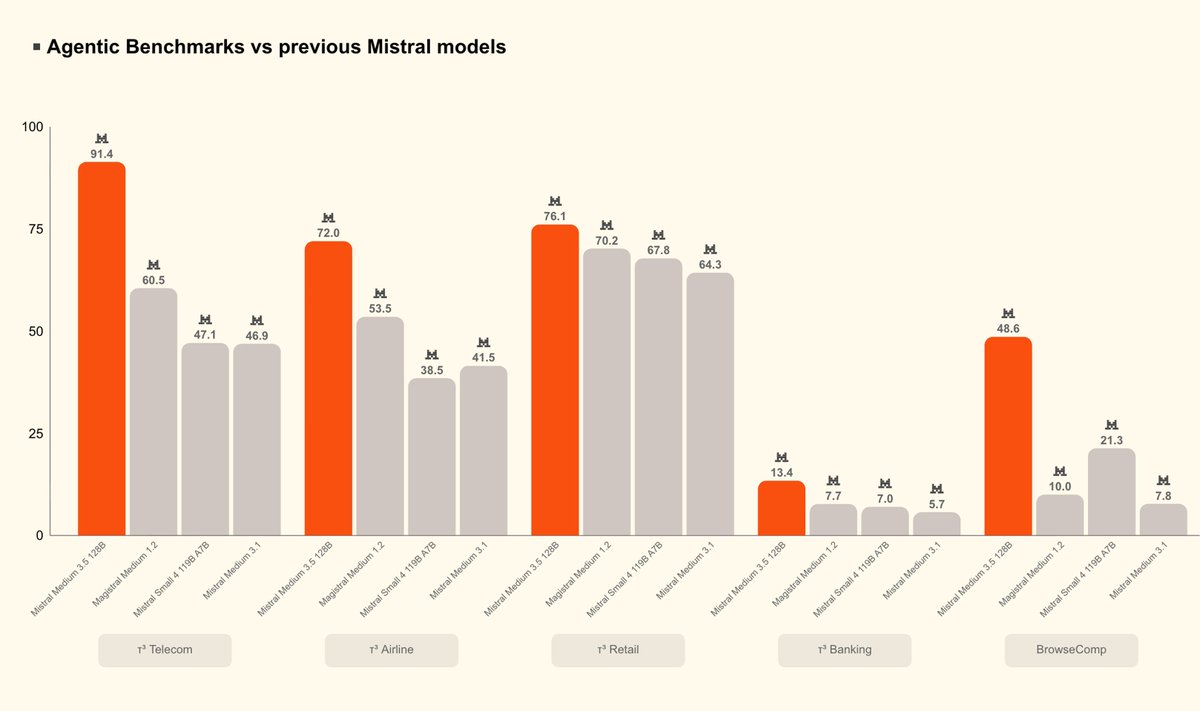
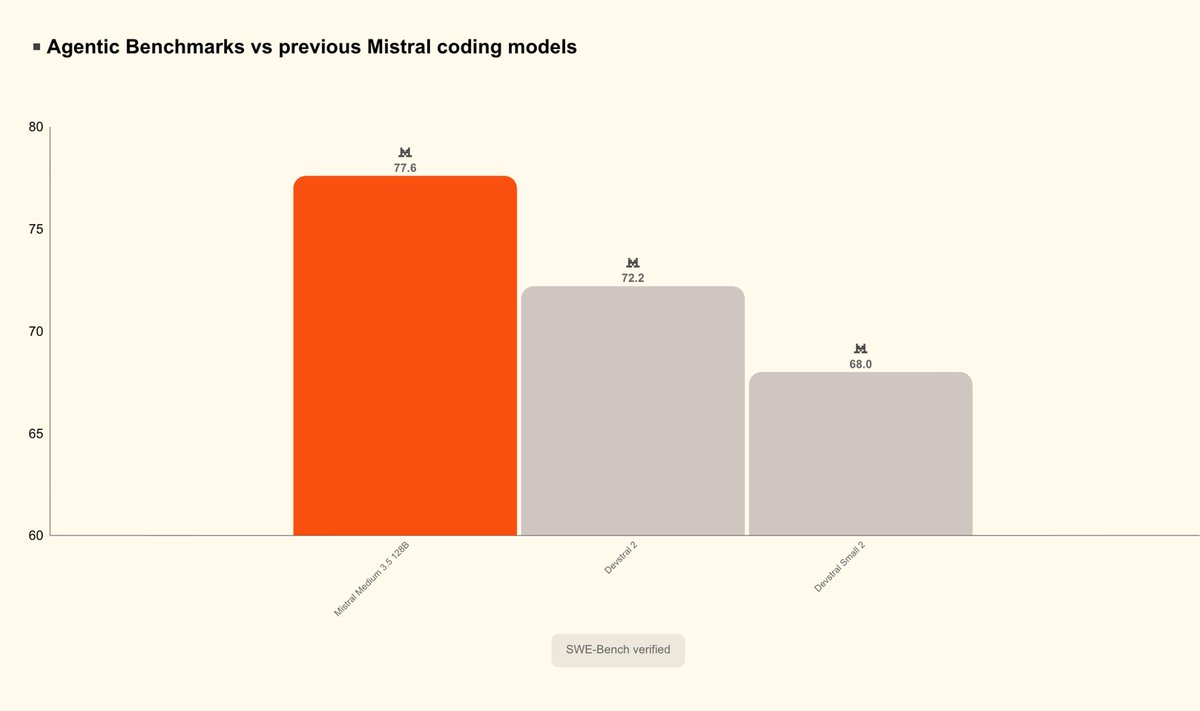
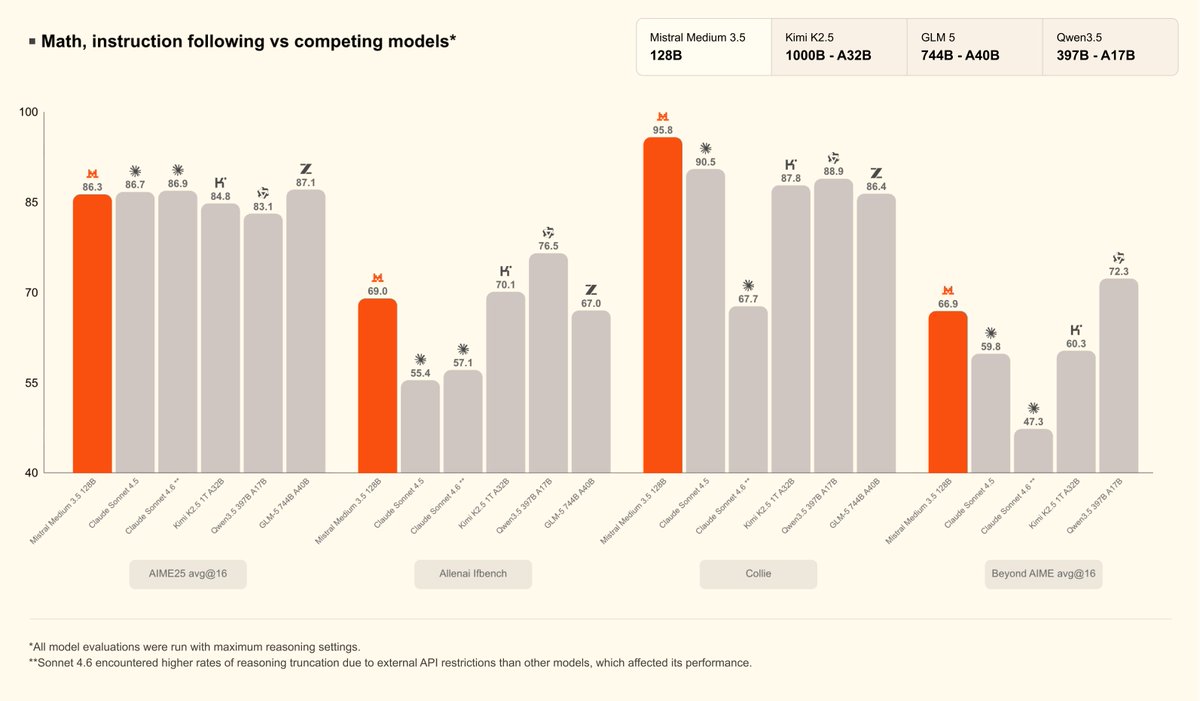
Mistral Medium 3.5, a new flagship model in public preview by @MistralAI that merges instruction-following, reasoning, and coding into a single 128B dense model with a 256k context window and configurable reasoning effort. It's a new default model for Mistral Vibe and Le Chat. Released as open weights, under a modified MIT license.