New article: a visual tour of recent LLM architecture advances, from Gemma 4 to DeepSeek V4.
I focus on long-context efficiency tweaks like KV sharing, per-layer embeddings, layer-wise attention budgets, compressed attention, and mHC.
Link: https://t.co/KO81y3kTH7
We broke ground today on @ASU Health's new HQ in Phoenix. Not just a building but a declaration that health care can be delivered differently. Proud to be at the edge of the future. #SunDevilDocs https://t.co/8NApcCZaax
Medicine 3.0 is predictive, preventive, and engineered for scale.
I spoke with @WJCTNews about how @ASU’s John Shufeldt School of Medicine & Medical Engineering is reimagining physician training for the AI era and beyond.
🎙️ https://t.co/EeJjxz3WKp
#SunDevilDocs
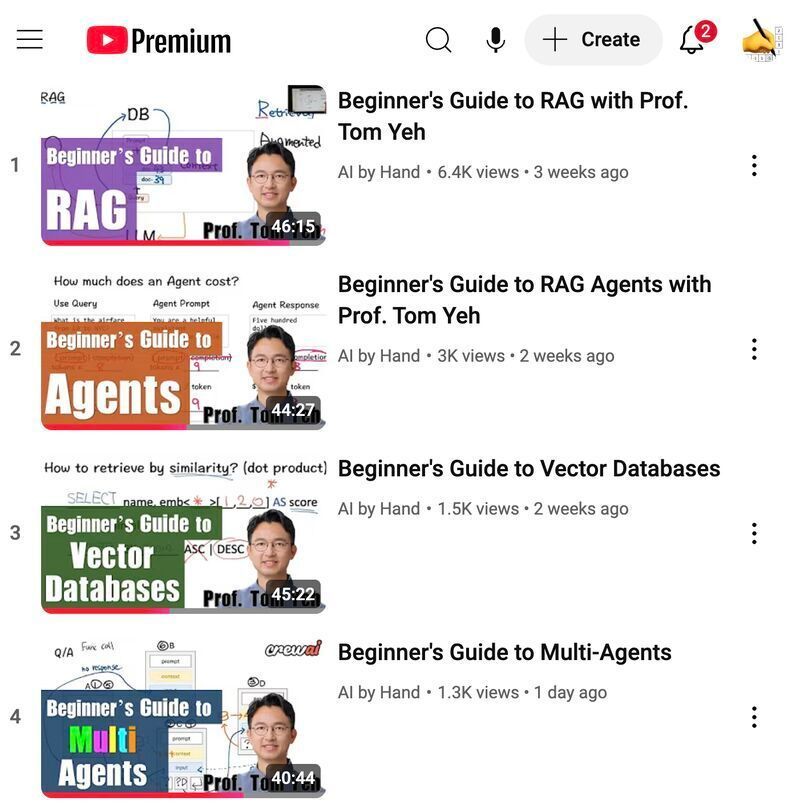
Here's my beginner's lecture series for RAG, Vector Database, Agent, and Multi-Agents: Download slides: 👇
* RAG: https://t.co/O3OvTXVWUI
* Agents: https://t.co/BeJedAKwC9
* Vector Database: https://t.co/UZw5Lieszp
* Multi-Agents: https://t.co/iEMJKeMYAE
---
100% original, made by hand ✍️
Join 56K+ readers of my newsletter: https://t.co/fFt8roc8D9
> I don’t understand why people are still paying in dollars to learn LLMs.
> these 9 lectures from Stanford are a pure goldmine for anyone wanting to understand LLMs in depth.
Honored to be interviewed by @reporterestes on @arizonapbs about new developments at the @ASU John Shufeldt School of Medicine and Medical Engineering. Stream it here: https://t.co/Bu6Ero7EYE
#SunDevilDocs
bro created an entire 16-hour free youtube playlist on how to build a DeepSeek model from scratch. it goes over the papers, explains the theory, and implements the code.
Syllabus:
→ attention mechanism fully explained
→ multi-head latent attention
→ grouped query attention
→ everything about positional encodings
→ mixture of experts (MoE)
just start today with a laptop and motivation.
playlist: https://t.co/AmVYJIUpaK
Ten years (!) after submitting the grant, NextBrain is published in @Nature . NextBrain is a brain atlas built from 3D histology that enables segmentation of 3D brain scans (MRI, Hip-CT, even photos!) into hundreds of regions.
Article, data, code, videos, & more in this 🧵 (1/3)
Stanford just published a huge 470-page study 📕
"The Principles of Diffusion Models"
Explains how diffusion models turn noise into data and ties their main ideas together.
It starts from a forward process that adds noise over time, then learns the exact reverse.
The reverse uses a time dependent velocity field that tells how to move a sample at each step.
Sampling becomes solving a time based equation that carries noise to data along a trajectory.
There are 3 views of this idea, variational, score-based, and flow-based, and they describe the same thing.
There are also 4 training targets, noise, clean data, score, and velocity, and these are equivalent.
Shows how guidance can steer outputs using a prompt or label without extra classifiers.
Reviews fast solvers that cut steps while keeping quality stable.
Explains distillation methods that shrink many sampling steps into a few by mimicking a teacher model.
Introduces flow map models that learn direct jumps between times for fast generation from scratch.
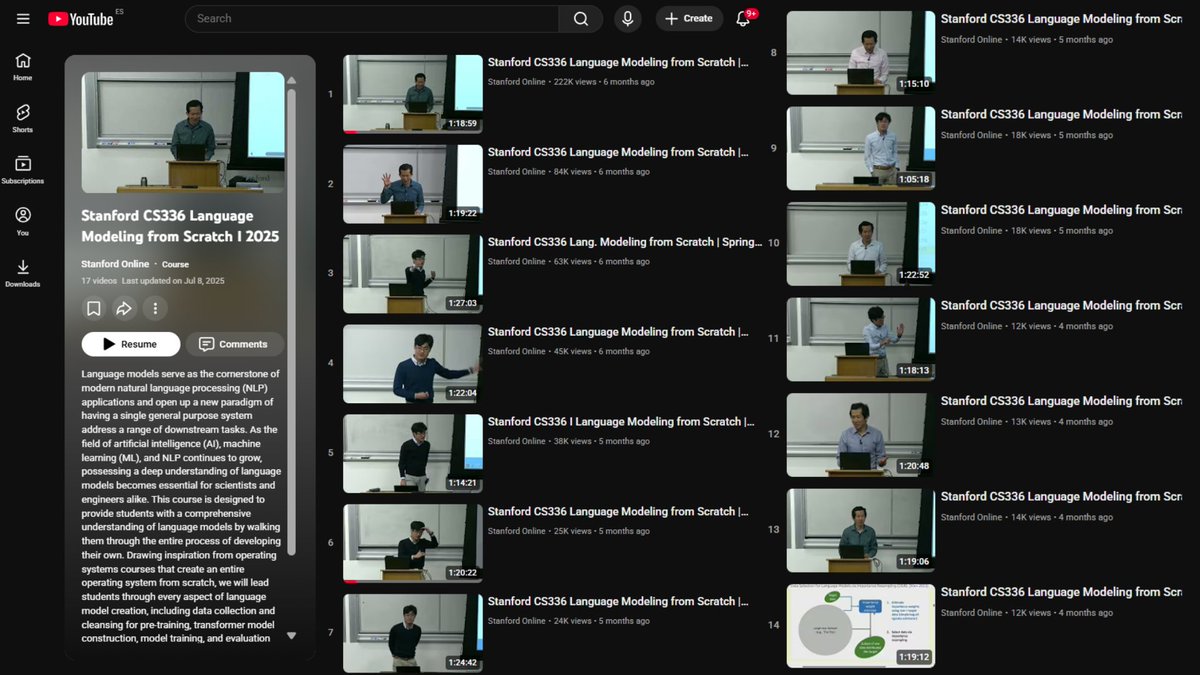
Stanford just did something wild. They put their entire graduate-level AI course on YouTube. No paywall, no signup. It’s the exact curriculum Stanford charges $7,570 for ❱❱❱❱ watch free now
🚨Big news: Stanford quietly dropped a $5000 AI course on YouTube - completely FREE. Most people still don’t know this.
It’s the full Stanford CS336: Language Modeling from Scratch (Spring 2025) the same course graduate students pay thousands for.
What you actually get:
- 17 full lectures (~22 hours of content)
- Covers everything from tokenization, GPU kernels, distributed training, Mixture of Experts (MoE), scaling laws, inference optimization, data engineering, alignment (SFT, RLHF, DPO), all the way to evaluation
- The same material taught at Stanford for $5000... now $0
- You save ~$294 per lecture if you put a dollar value on it
In under 3 weeks (1 lecture/day) you can cover the entire curriculum
This isn’t prompt-hacking fluff... it’s real systems engineering, showing you how to build LLMs from scratch
Where to start:
Search “Stanford CS336 Language Modeling from Scratch (2025)” on YouTube (Stanford Online channel).
Follow, Like, and Repost 🙏
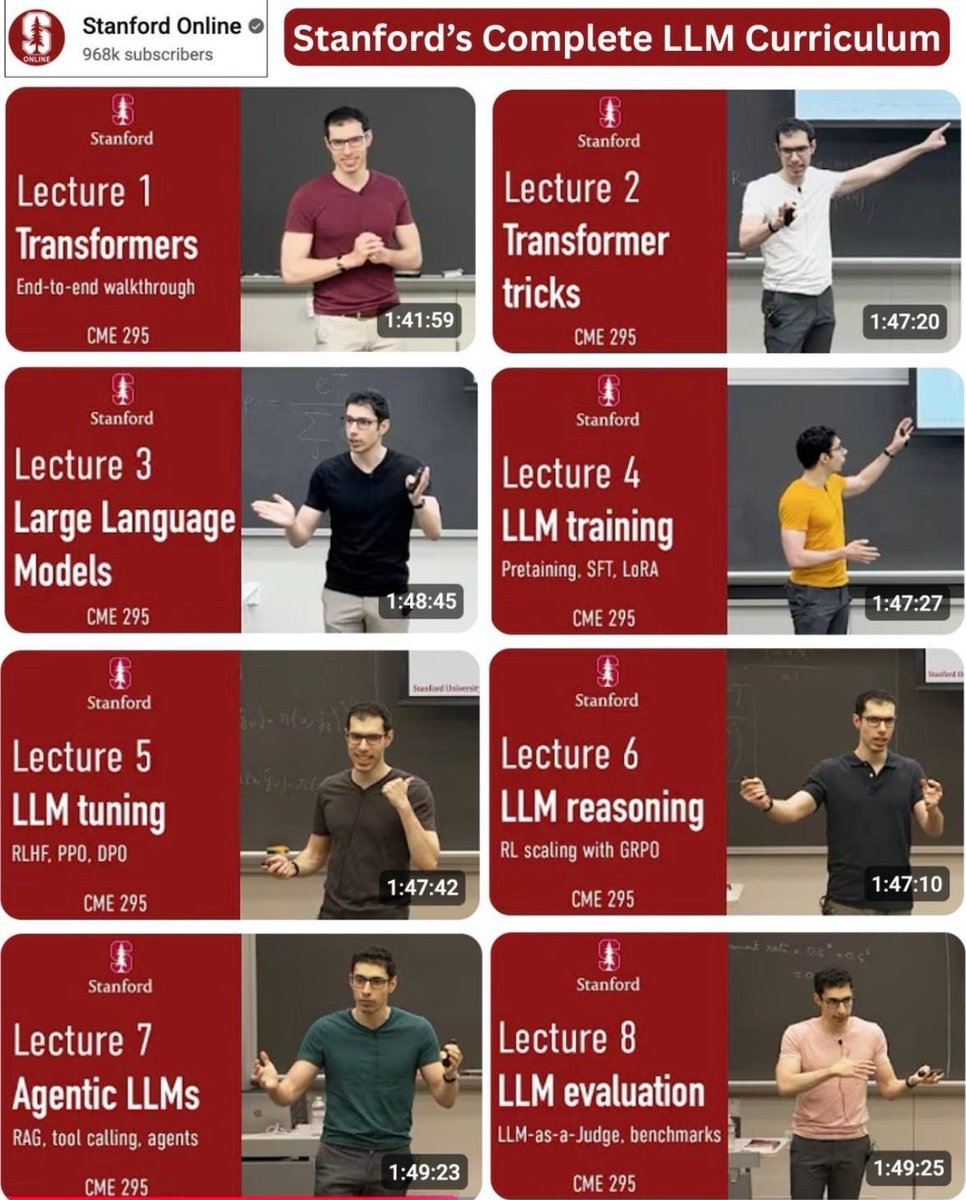
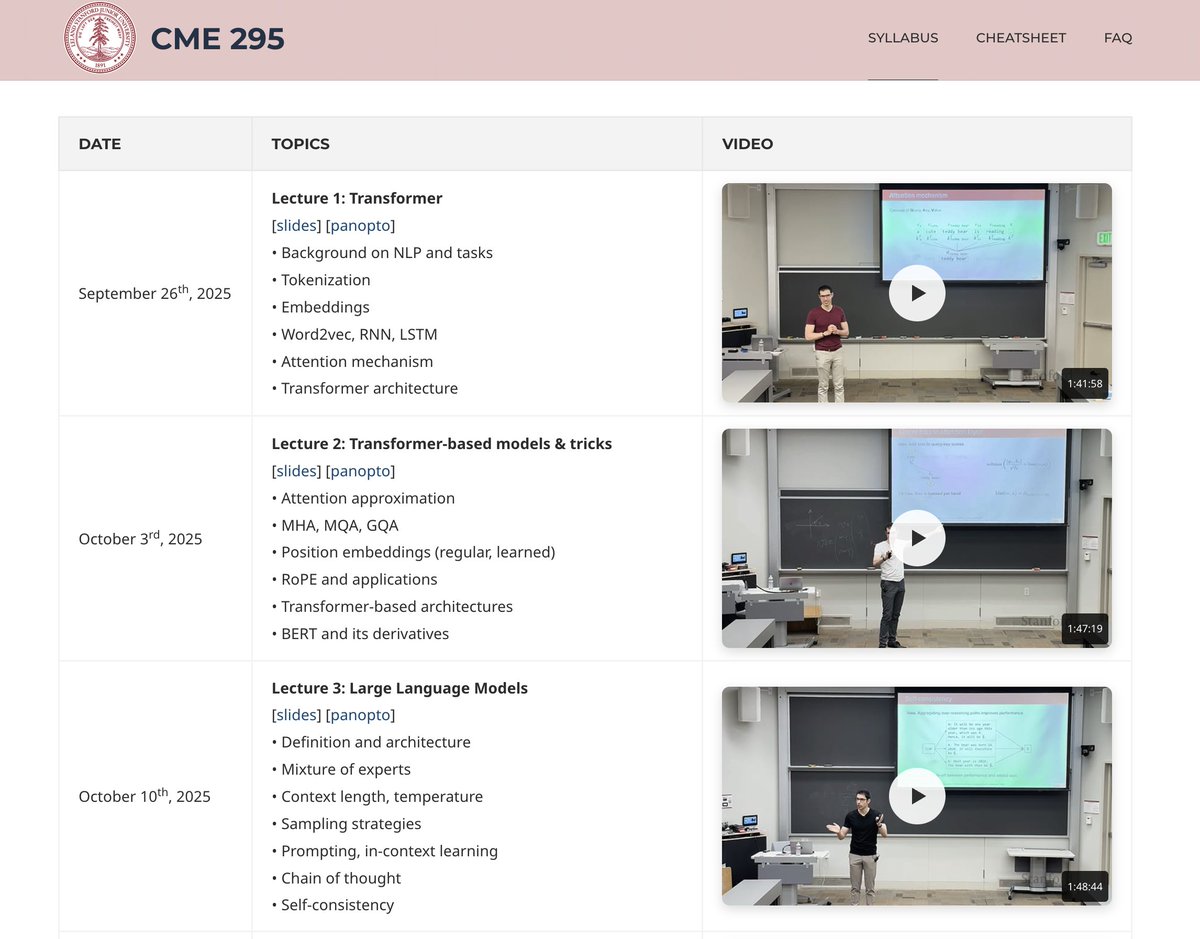
🎓Stanford CME295 Transformers & LLMs
Nice to see the new release of this new course on Transformers and LLMs.
Great way to catch up on the world of LLMs and AI Agents.
Includes topics like the basics of attention, mixture-of-experts, to agents.
Excited to see more on evals.
First lessons available now.
https://t.co/lpD2idL5co
A senior Google engineer just dropped a 424-page doc called Agentic Design Patterns.
Every chapter is code-backed and covers the frontier of AI systems:
→ Prompt chaining, routing, memory
→ MCP & multi-agent coordination
→ Guardrails, reasoning, planning
This isn’t a blog post. It’s a curriculum. And it’s free.
🚀 Biomni v0.0.7 is live!
New features:
📜 PDF export for agent chats
🦠 SOTA cell type transfer algorithms
🔬LazySlide pathology support
🔍Claude web search
🌟Bioimaging pipeline tools
🧬Gene conversion & ESM embeddings
🪴Glycoengineering capabilities
Plus improved commercial licensing & data handling!
👉 Try it here: https://t.co/hmKzup0QAa
🏆📚This 200-Page LLM Paper Is a 𝗚𝗼𝗹𝗱𝗺𝗶𝗻𝗲 — and it’ll save you months
𝗣𝗿𝗼𝗺𝗽𝘁𝗶𝗻𝗴, 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴, 𝗮𝗹𝗶𝗴𝗻𝗺𝗲𝗻𝘁 — finally crystal clear.
If you don’t have time to read all 200+ pages, here are the most valuable 𝘁𝗮𝗸𝗲𝗮𝘄𝗮𝘆𝘀 ↓
》 𝗣𝗿𝗲-𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴:
How AI Gets Smart Before It Gets Useful Before an LLM can generate anything meaningful, it must pre-train—absorbing patterns from vast datasets. This paper breaks it down:
✸ Unsupervised, Supervised, and Self-Supervised Pre-training – Why AI learns better with less human labeling.
✸ Encoder vs. Decoder vs. Encoder-Decoder Models – The three fundamental architectures and when to use them.
✸ BERT & Transformers – How they rewrote the rules of AI understanding.
》 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝘃𝗲 𝗠𝗼𝗱𝗲𝗹𝘀:
Where AI Stops Memorizing and Starts Creating
Pre-training gives LLMs knowledge. Generative models give them a voice.
✸ Decoder-Only Transformers (GPT-style models) – The backbone of AI creativity.
✸ Training & Fine-tuning LLMs – How models evolve from generalists to specialists.
✸ Alignment & Safety – Why raw AI outputs need guardrails (and how RLHF fixes it).
》𝗣𝗿𝗼𝗺𝗽𝘁 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴:
The Skill That Separates AI Users From AI Builders
If you’re not prompting correctly, you’re missing out on 90% of an LLM’s potential. This paper covers:
✸ In-Context Learning – Teaching AI on the fly without retraining.
✸ Chain of Thought & Self-Refinement – Making AI reason instead of regurgitate.
✸ RAG & Tool Use – Giving LLMs external memory for better accuracy.
》 𝗔𝗜 𝗔𝗹𝗶𝗴𝗻𝗺𝗲𝗻𝘁:
Teaching AI to Work for Humans (Not Against Them)
One of the biggest challenges in AI is getting it to follow human intent. The paper breaks down:
✸ Instruction Fine-Tuning – How models learn from curated data.
✸ Reinforcement Learning with Human Feedback (RLHF) – Why AI listens to your preferences.
✸ Inference-Time Alignment – Tweaking responses without retraining the whole model.
☆ Paper: https://t.co/ml3bgZrlvS
≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣
⫸ꆛ Want to build Real-World AI Agents?
Join My 𝗛𝗮𝗻𝗱𝘀-𝗼𝗻 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁 𝟱-𝗶𝗻-𝟭 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴!
➠ Build Agents for Healthcare, Finance, Smart Cities & More
➠ Master 5 Modules: 𝗠𝗖𝗣 · LangGraph · PydanticAI · CrewAI · Swarm
➠ Includes 9 Full Projects
👉 𝗘𝗻𝗿𝗼𝗹𝗹 𝗡𝗢𝗪 (𝟱𝟲% 𝗢𝗙𝗙):
https://t.co/5i2v1fIrhJ
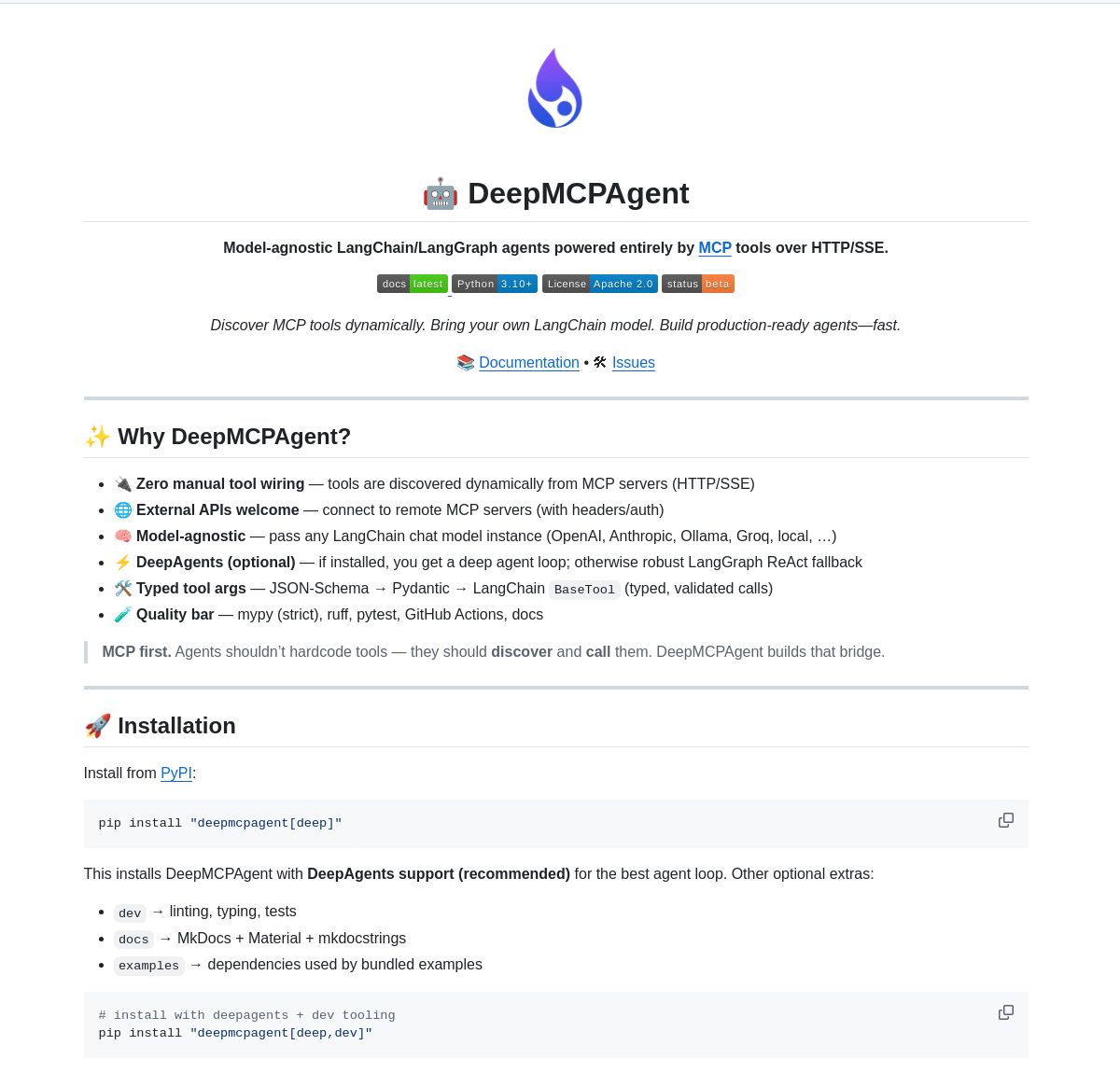
🤖🔌 DeepMCPAgent
A powerful tool for dynamic MCP tool discovery and agent development. Built with LangChain and LangGraph, it streamlines integration over HTTP/SSE while supporting major LLMs.
Check it out! 🚀
https://t.co/4CGOb04Ycu
Apple just released and open-sourced FastVLM!
FastVLM is a lightning-fast vision-language model that combines rapid image and text understanding with efficient on-device performance.
100% Open Source
a senior engineer at google just dropped a 400-page free book on docs for review: agentic design patterns.
the table of contents looks like everything you need to know about agents + code:
> advanced prompt techniques
> multi-agent patterns
> tool use and MCP
> you name it
He predicted:
• AI vision breakthrough (1989)
• Neural network comeback (2006)
• Self-supervised learning revolution (2016)
Now Yann LeCun's 5 new predictions just convinced Zuckerberg to redirect Meta's entire $20B AI budget.
Here's what you should know (& how to prepare):