Excited to share #ICML2026 paper from my internship @GoogleDeepMind!
AI models are deployed globally, but safety datasets are largely geographically homogenous. What is the impact of culture on AI safety ratings? Is there impact beyond standard demographics?
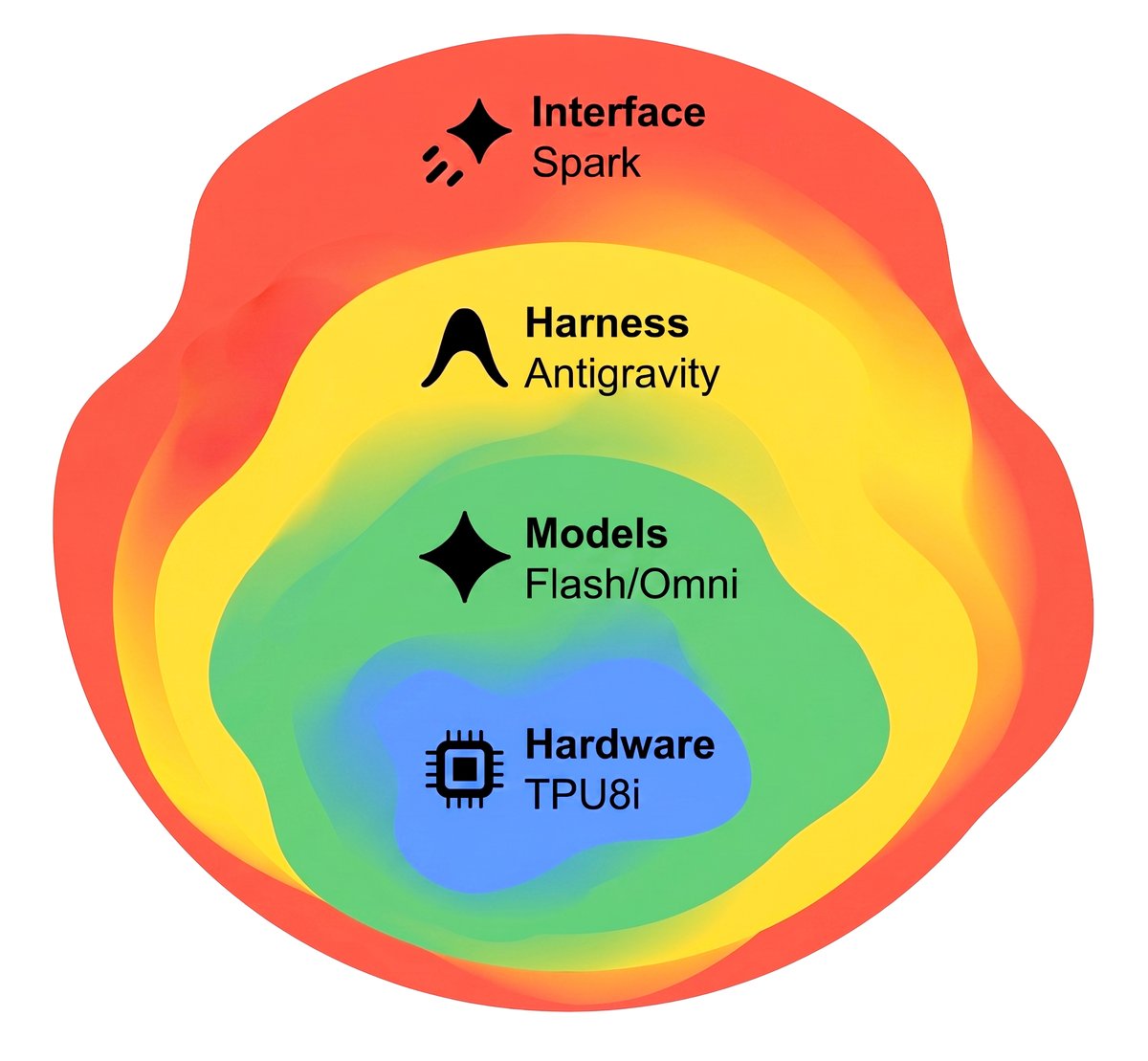
Google I/O TLDR: Good improvements across the whole AI stack.
3.5 Flash (the model): More persistent than before and codes well. No wall yet.
Antigravity (the harness): Reliably runs for hours now. Early signs of hands-free self-improvement.
Spark (the interface): Finally connects a decent model and harness to your email, calendar and workspace. Instead of just answering questions it can actually do work for you. Skills and schedules and all the other claw goodness.
Omni (the future): Closes the gaps between Gemini for text and visual/audio generation variants. This is the way.
TPU8i (the hardware): Better chips to make all the above go faster.
A bittersweet announcement! For family reasons, I will be leaving AISI soon to move back to the Bay Area. I will be starting a new nonprofit alignment research org (more to come).
I will miss this place! Here are some reflections about my time at AISI. 🧵❤️
Making humans responsible for their AI use seems like an incredibly reasonable way to address problems & opportunities in the use of AI for academic research, at least in the short term (autonomous scientific work will require different solutions).
This paper from @sebkrier@RubenLaukkonen, et al. captures the @collect_intel agenda better than I usually do myself.
Defining what constitutes flourishing needs to be a whole of society process; constituting those values in the form of AI constitutions requires better practices and methodologies (@ahall_research is one to follow here, and I'll have something to share soon); proving out new AI-enabled collective intelligence processes that allow people to better negotiate tradeoffs and competing priorities (you know, democracy); building better institutions that enable and coordinate human flourishing; moving from red lines to greenlines (https://t.co/hCWut1yAaH)
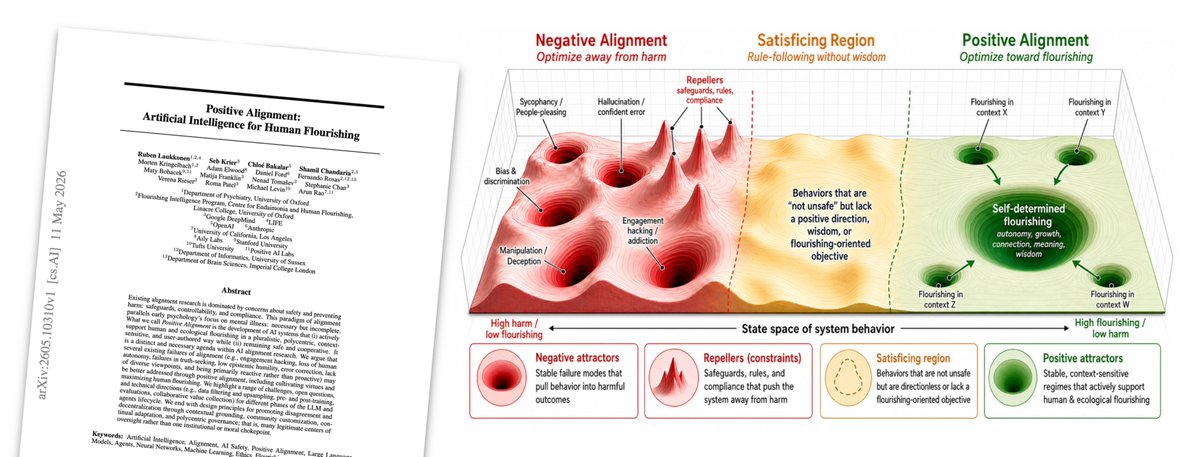
Our new paper introduces "Positive Alignment" 💛
Traditional safety alignment focuses on reducing harms -- can we create a complementary field that focuses on increasing human flourishing?
AI alignment has been almost exclusively focused on safety applications (i.e., avoiding harms). Today, we’re thrilled to introduce a complementary direction that explores how AI systems can be aligned, in a pluralistic way, around human flourishing as the guiding principle.
AI responsibility & alignment has focused on "negative alignment": building guardrails to stop models from causing harm. While vital, this only establishes a behavioural floor.
It's time for a new paradigm! *Positive Alignment*: Artificial Intelligence for Human Flourishing
If anyone builds it, everyone thrives. Over the past decade, a lot of important work on AI alignment has focused on avoiding harm. But freedom from harm isn't the same as freedom to flourish.
In this paper, we introduce 'Positive Alignment'. A positively aligned agent is one that helps us navigate our own value trade-offs, builds our resilience, and acts as a scaffold for human flourishing. Doing this without slipping into top-down, technocratic paternalism is the great design challenge of our time.
We think a lot more research is now needed to explore this frontier: how do we align models that actively help us thrive?
Amazing work by @RubenLaukkonen, @drmichaellevin, @weballergy, @verena_rieser, @AdamCElwood, @996roma, @FranklinMatija, @shamilch, @_fernando_rosas, @scychan_brains, @matybohacek, @sudoraohacker, and others.
https://t.co/YNL0cZqYD9
If anyone builds it, everyone thrives. Over the past decade, a lot of important work on AI alignment has focused on avoiding harm. But freedom from harm isn't the same as freedom to flourish.
In this paper, we introduce 'Positive Alignment'. A positively aligned agent is one that helps us navigate our own value trade-offs, builds our resilience, and acts as a scaffold for human flourishing. Doing this without slipping into top-down, technocratic paternalism is the great design challenge of our time.
We think a lot more research is now needed to explore this frontier: how do we align models that actively help us thrive?
Amazing work by @RubenLaukkonen, @drmichaellevin, @weballergy, @verena_rieser, @AdamCElwood, @996roma, @FranklinMatija, @shamilch, @_fernando_rosas, @scychan_brains, @matybohacek, @sudoraohacker, and others.
https://t.co/YNL0cZqYD9
My team at @AISecurityInst studies how frontier AI shapes what we believe, decide, and feel - and we're hiring! 🚨
The role is a 6-month RA residency in London, ideal for MScs / early PhDs in ML, psych, cog/data sci
[1 June deadline]
Get a taste of our recent research below 👇
More people should follow @m_botvinick . Extravagantly accomplished scholar across AI, neuroscience, cognition, democracy and more - his Google Scholar is a vibe. Asking the right questions about AI and democracy, and I'm v grateful he is. Just started tweeting, so play nice so he doesn't think better of it. <200 followers.
Honestly, I’m increasingly impressed by political methodology as a field.
At our AI methods workshop, ~half the submissions are coming from political science, and many of the strongest ones too. Same pattern with postdoc applications to my lab.
Something is clearly working there: strong training, fast adoption of new methods, and a willingness to engage with real empirical problems.
Worth paying attention to.
Excited about our new paper: AI Agent Traps
AI agents inherit every vulnerability of the LLMs they're built on - but their autonomy, persistence, and access to tools create an entirely new attack surface: the information environmental itself.
The web pages, emails, APIs, and databases agents interact with can all be weaponised against them. We introduce a taxonomy of six classes of adversarial threats - from prompt injections hidden in web pages to systemic attacks on multi-agent networks.
I’m outlining the six categories of traps in the thread bellow