What should AI generate in order to improve itself?
Not just more questions, traces, or answers.
We believe it should learn to generate environments.
Excited to share my first work after joining Tencent Hunyuan LLM. We study how models can construct reusable, verifiable environments that provide stable training signals for self-improvement.
This is only a first feasibility step, but we see environment construction as a necessary path toward truly self-improving AI.
Paper: https://t.co/bUO40DkKwz
You've been asking for this one...
Now in preview: Codex in the ChatGPT mobile app.
Start new work, review outputs, steer execution, and approve next steps, all from the ChatGPT mobile app. Codex will keep running on your laptop, Mac mini, or devbox.
Introducing GPT-5.5
A new class of intelligence for real work and powering agents, built to understand complex goals, use tools, check its work, and carry more tasks through to completion. It marks a new way of getting computer work done.
Now available in ChatGPT and Codex.
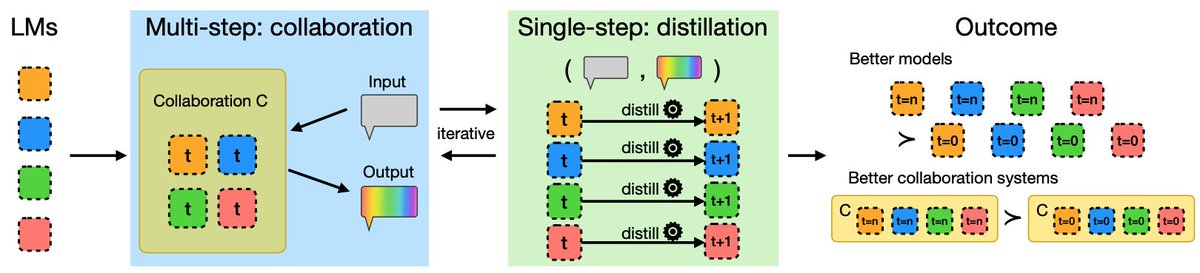
📌Introducing Single–Multi Evolution Loop for self-improving LLMs
Self-distillation is strong. Multi-LLM teachers are 𝐒𝐭𝐫𝐨𝐧𝐠𝐞𝐫!
Iterate: collaborate → distill → repeat, then single + multi systems improve together.
Paper: https://t.co/BMDYMnSnSa
⚠️ Multi-LLM collaboration systems are costly?
💡 Distill the collaborative outputs back into a single model!
♻️ These post-distillation, improved LLMs can collaborate again, forming a multi-LLM collective evolution cycle.
Introducing: ✨the single-multi evolution loop✨
https://t.co/fhftq8YwC5
Joint work w/ @kpb_in_acad@tsvetshop@wyu_nd
For LLM RL, Entropy is not equal to exploration. Semantic diversity is also a lie.
Most RL exploration methods push LLMs to "look" different, but they ignore how the model actually learns.
We propose G²RL: Gradient-Guided Exploration for RL
https://t.co/JGN6MGj6eb
(1/n)
🚀Introducing 𝐆𝐫𝐚𝐝𝐢𝐞𝐧𝐭-𝐠𝐮𝐢𝐝𝐞𝐝 𝐎𝐩𝐭𝐢𝐦𝐢𝐳𝐚𝐭𝐢𝐨𝐧 for RL (G²RL)!
We know exploration is crucial in RL, but forcing entropy as a reward can inflate it in unhealthy ways.
Our G²RL measures policy-intrinsic exploration from "gradients", avoiding mismatch from external comparators (classifiers, embeddings, etc.).
🌟Key insights: rollout trajectories are preferred when they meaningfully expand the policy’s own update directions, and discouraged when they contribute redundant or uninformative gradients.
-- Easy to implement
- -Negligible overhead
-- Improves accuracy
G²RL leads to healthier, more structured exploration
Paper: https://t.co/SFzOX1HfHI
🔥 New Tencent x UCLA paper!
Even SoTA image editing models (e.g., Nano Banana, GPT-Image-1) struggle with motion editing -- changing actions, poses, and interactions.
We tackle this head-on, and do it better. 🧠✨
Paper: https://t.co/Vx5Dmv05KF
📢 Happening Today at NeurIPS 2025!
🚀Come check out our spotlight paper, MMlongBench. We propose the first comprehensive benchmark (13k) to evaluate long-context VLM, and tested 46 models in the paper.
🖼️ Poster: #4507
⏰ Time: 11am - 2pm
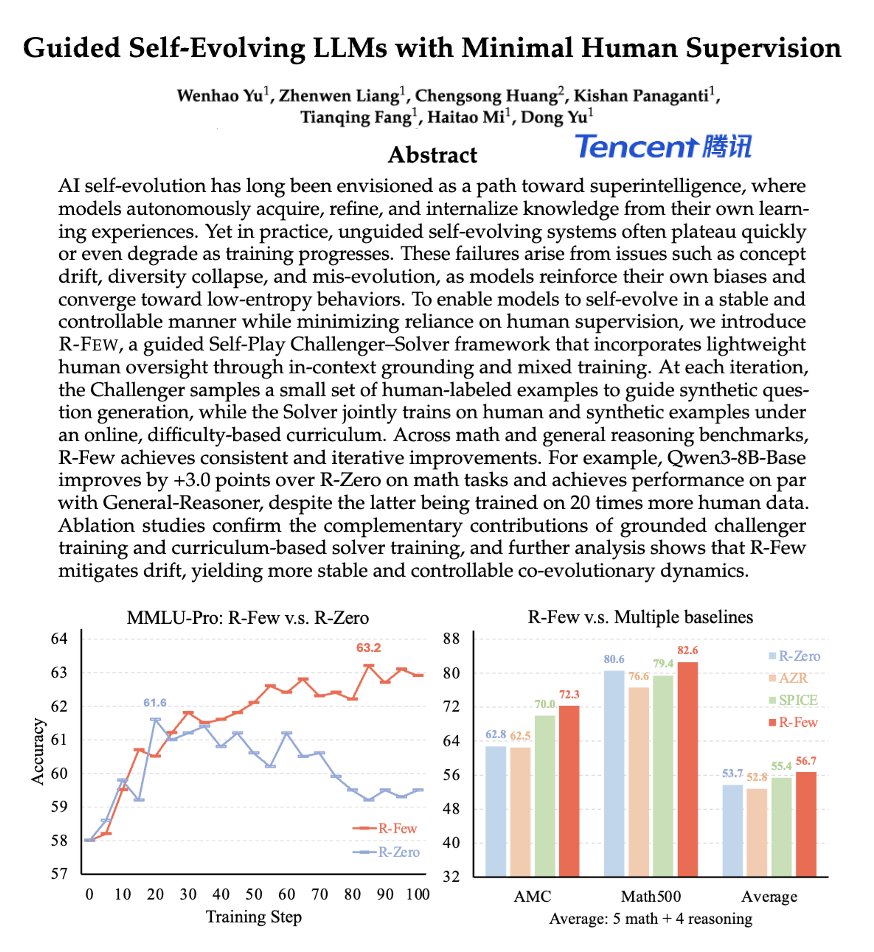
Beautiful Tencent paper.
Shows a language model that keeps improving itself using only 1% to 5% human labeled questions while reaching the level of systems trained on about 20 times more data.
Earlier self play systems let a model write and solve its own questions, but over time it drifts, repeats narrow patterns, and can even perform worse.
Their method runs a challenger copy that generates questions and a solver copy that answers them, turning training into a question answer game between 2 agents.
When the challenger writes, it sometimes sees a few real human question answer pairs, which pull its synthetic questions toward realistic tasks instead of strange, off topic puzzles.
For each question, the solver tries several answers, the system estimates its success rate, and training keeps mainly mid difficulty questions where the solver is uncertain but not lost.
Because both human and synthetic questions pass this filter, the solver trains on focused, non trivial problems, avoids cheap tricks like inflating question length, and gains stronger math and general reasoning scores than earlier self play methods.
----
Paper Link – arxiv. org/abs/2512.02472
Paper Title: "Guided Self-Evolving LLMs with Minimal Human Supervision"
In R-Few, The Challenger is incentivized to generate moderately (“medium”) uncertain questions that lie at the edge of the Solver’s current abilities; the Solver is rewarded for solving increasingly challenging tasks – sourced from both humans and the Challenger – via curriculum-based selection.
📢New paper: Guided Self-Evolving LLMs with Minimal Human Supervision
Self-evolving / Self-improving LLMs often plateau fast due to concept drift, diversity collapse, and mis-evolution.
Our method fixes this — keeping self-evolution stable, aligned, and on track!
Link: https://t.co/ptLW6Ls0ig
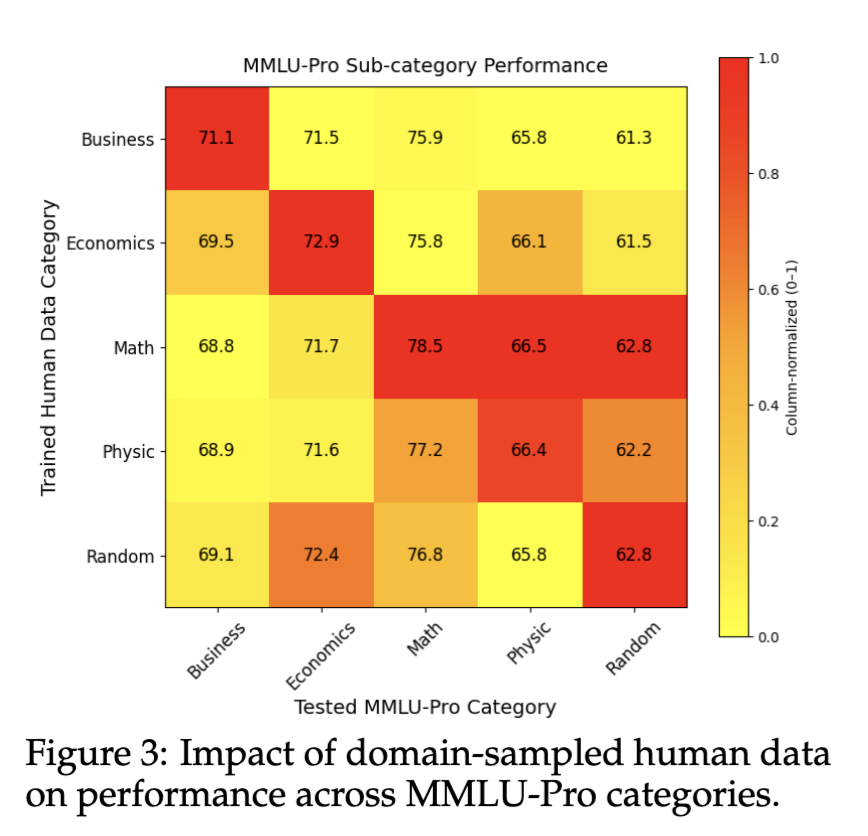
Domain-specific training boosts performance mostly within its own field; math transfers broadly, with strong math–physics and business–economics cross-domain connections.