We needed a storage layer that can scale to a huge number of volumes (think millions) for our Postgres platform.
Most of the existing storage systems are optimized for a few volumes with really high performance. But we needed the opposite: a very large number of mostly idle volumes.
So we wrote our own.
It’s called Xatastor and it enables Postgres-per-tenant use cases, “ephemeral” dbs for agents, free tiers, etc. Supports copy-on-write snapshots, clones, and thin provisioning.
It’s based on ZFS and NVMe-oF as key technologies. Link with all the details in the first reply.
Once the new store had a real retention window, we deleted the vendor client, the routing, the override header, the flag, the config.
Full write-up: https://t.co/jZnrmAGqbz
We rebuilt the metrics view for every Postgres branch on @xata. Out of a central observability vendor, into a per-cell @VictoriaMetrics stack.
Six weeks of work, no user-visible downtime in the console. Here's what we learned. 🧵
Best part of the cutover: both backends in code, behind a flag, with a header to flip backends per request. Same chart on both, side by side, for a week.
That's how we caught a double-count where pod aggregates were summing with the per-container series.
We open-sourced a Next.js + Postgres starter with 6 Claude Code skills.
Each skill wraps the Xata CLI for one workflow: branch, migrate, complete, rollback, clone-with-anonymization, setup.
Tutorial: https://t.co/bXG8F2osKp
@monicasarbu and the Xata team are at AWS Summit Hamburg today, in the AWS Startup Zone, Hall 4.
If you're thinking about Postgres for agent scale, come find us.
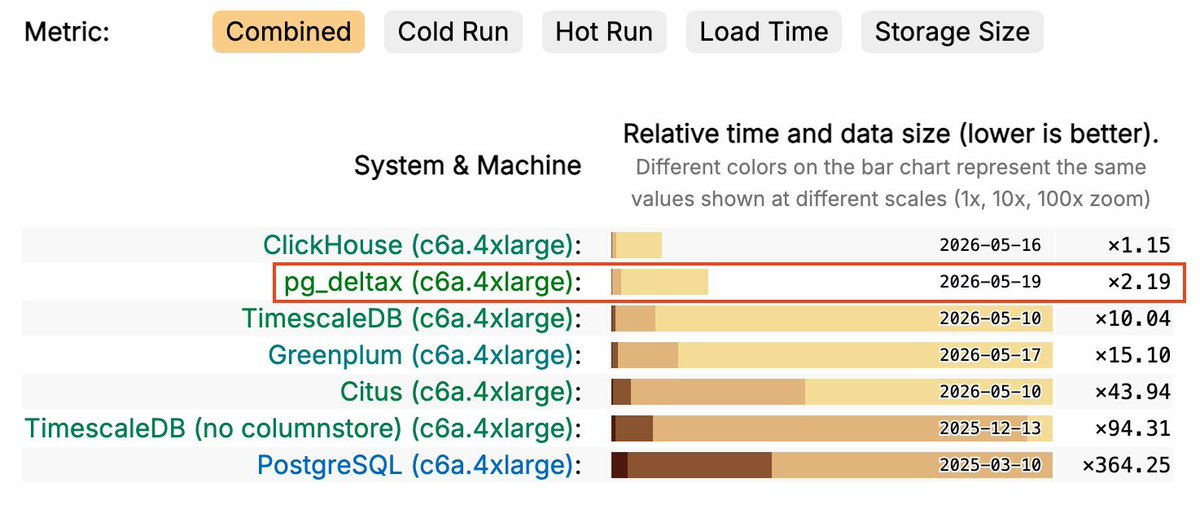
DeltaX is a Postgres extension that adds columnar storage and time-series compression.
Data lives in regular Postgres tables. pg_dump, replication, and crash recovery all keep working without change.
Under the hood:
→ Type-specific codecs (Gorilla XOR, delta-of-delta, dictionary, block-LZ4)
→ Vectorized Rust execution, bypasses per-row ExecQual
→ Segment pruning with bloom filters → Parallel aggregation
→ Shared-memory blob cache
Status is alpha, PostgreSQL 17 and 18.
Star the project: https://t.co/usGwI4XjLY
There’s something I’ve been feverishly working on, and I just turned the repo public:
pg_deltax (δx) - Fast time-series extension for PostgreSQL. Basically an Apache-licensed Timescale alternative.
GitHub link in the thread.
The decode-time table filter is a community contribution from @blakewatters
add_tables and filter_tables go straight through to wal2json. Thanks Blake.
Release: https://t.co/8kxoOVma0O
pgstream v1.0.2 is out.
Post-snapshot catch-up no longer stalls on bulk INSERT or DELETE tables (Postgres sink coalesces flushes now).
You can also filter tables at decode time inside the source Postgres via wal2json.
Plus Go 1.26.3 security fixes; v0.9.12 backports that one too.
Every Xata Postgres branch now ships with a managed PgBouncer endpoint, included.
A Postgres connection costs about 5MB of backend memory.
Fine when traffic comes from a handful of app servers. Breaks when traffic comes from serverless functions, edge workers, or AI agents that open a connection per request.
Postgres wants fewer, long-lived connections. Modern apps produce many short-lived ones.
A pooler reconciles that.
We chose to ship one PgBouncer pod per branch, on the same node as the database, in the same memory budget.
Pool size auto-tunes to 0.9 of max_connections and re-tunes when the instance changes.
If you connect directly to Postgres, append -pooler to your branch ID:
> postgresql[:]//user:pass@branch-id-pooler[.]us-east-1[.]xata[.]sh:5432/postgres
One-line change in your connection string.
Branching gives you cheap copies of Postgres. Pooling gives those copies somewhere to take traffic. We needed both.
https://t.co/4XvMpERSQS
We needed a storage layer that can scale to a huge number of volumes (think millions) for our Postgres platform.
Most of the existing storage systems are optimized for a few volumes with really high performance. But we needed the opposite: a very large number of mostly idle volumes.
So we wrote our own.
It’s called Xatastor and it enables Postgres-per-tenant use cases, “ephemeral” dbs for agents, free tiers, etc. Supports copy-on-write snapshots, clones, and thin provisioning.
It’s based on ZFS and NVMe-oF as key technologies. Link with all the details in the first reply.
We’re seeing this firsthand with AI platforms we partner with:
👉 every agent needs its own isolated Postgres DB
👉 at scale, that’s millions of databases
👉 many on free tiers → cost matters a lot
That combination breaks traditional storage.
Most systems are built for a few always-on volumes.
Agents need the opposite: millions of mostly idle ones.
So we built Xatastor.
It enables Postgres-per-tenant use cases, ephemeral DBs for agents, free tiers, and supports copy-on-write snapshots, clones, and thin provisioning.
AI codes. Humans engineer.
AI is already good at boilerplate, search, command line, simple fixes with feedback loops. Outsource it.
Engineers still own decisions, distillation, organizational context, code review, and breaking out of incorrect assumptions.