GPT-4 is getting worse over time, not better.
Many people have reported noticing a significant degradation in the quality of the model responses, but so far, it was all anecdotal.
But now we know.
At least one study shows how the June version of GPT-4 is objectively worse than the version released in March on a few tasks.
The team evaluated the models using a dataset of 500 problems where the models had to figure out whether a given integer was prime. In March, GPT-4 answered correctly 488 of these questions. In June, it only got 12 correct answers.
From 97.6% success rate down to 2.4%!
But it gets worse!
The team used Chain-of-Thought to help the model reason:
"Is 17077 a prime number? Think step by step."
Chain-of-Thought is a popular technique that significantly improves answers. Unfortunately, the latest version of GPT-4 did not generate intermediate steps and instead answered incorrectly with a simple "No."
Code generation has also gotten worse.
The team built a dataset with 50 easy problems from LeetCode and measured how many GPT-4 answers ran without any changes.
The March version succeeded in 52% of the problems, but this dropped to a pale 10% using the model from June.
Why is this happening?
We assume that OpenAI pushes changes continuously, but we don't know how the process works and how they evaluate whether the models are improving or regressing.
Rumors suggest they are using several smaller and specialized GPT-4 models that act similarly to a large model but are less expensive to run. When a user asks a question, the system decides which model to send the query to.
Cheaper and faster, but could this new approach be the problem behind the degradation in quality?
In my opinion, this is a red flag for anyone building applications that rely on GPT-4. Having the behavior of an LLM change over time is not acceptable.
Have you noticed any issues when using GPT-4 and ChatGPT lately? Do you think these problems are overblown?
The grading methodology is loose. Instead of giving credit about how good a certain activity (such as Evaluations and Testing) has been performed, it only requires the company "Report the results of " their internal reports. https://t.co/Mx1pQgwHPM
Not sure if this is true. If so, that’d be a significant academic misconduct. People take significant amount of time writing proposals. If really busy, why can’t one just refuse to review?
The countries with the highest rates of smartphone addiction:
1. 🇨🇳 China
2.🇸🇦 Saudi Arabia
3.🇲🇾 Malaysia
4.🇧🇷 Brazil
5.🇰🇷 South Korea
6.🇮🇷 Iran
7. 🇨🇦 Canada
8.🇹🇷 Turkey
9.🇪🇬 Egypt
10.🇳🇵 Nepal
11.🇮🇹 Italy
12.🇦🇺 Australia
13.🇮🇱 Israel
14.🇷🇸 Serbia
15.🇯🇵 Japan
16.🇬🇧 United Kingdom
17.🇮🇳 India
18.🇺🇸 United States
19.🇷🇴 Romania
20.🇳🇬 Nigeria
21.🇧🇪 Belgium
22.🇨🇭 Switzerland
23.🇫🇷 France
24.🇩🇪 Germany
A Tesla on Full Self-Driving blows through a stop sign at 35mph and nearly collides with two cars. The kicker is that this was during a livestream debate-demo-drive between FSD fan @GerberKawasaki and FSD skeptic @RealDanODowd.
This should go without saying, but for an automated system to be at the safety level of a human, this cannot happen. The fact that this occurred yesterday during THIS drive (along with other safety-critical disengagements) should serve as statistical evidence of how frequent this is occurring. IMO, this is the biggest nail in the Tesla FSD coffin.
Is GPT a high risk system? As a general purpose system, it is not designed to be. However, people might use it when building high risk systems. The same argument goes to every machine learning system. There needs to be a stronger reason to exclude GPT fro…https://t.co/IN3uwW3E4n
The question is what would be a satisfactory V&V process? — “Significant technical documentation will be required on testing and validation procedures, the collection, storage, mining and so on of data, and accountability. ” https://t.co/Dzj7QyY0Zf
Can deep learning be absolutely safe? Can this safety be proven? — I thought people have now generally agreed that neither of the above questions can have positive answer, and some concepts like safety integrity level (SIL) should play a role as a probabi…https://t.co/FZpytF360O
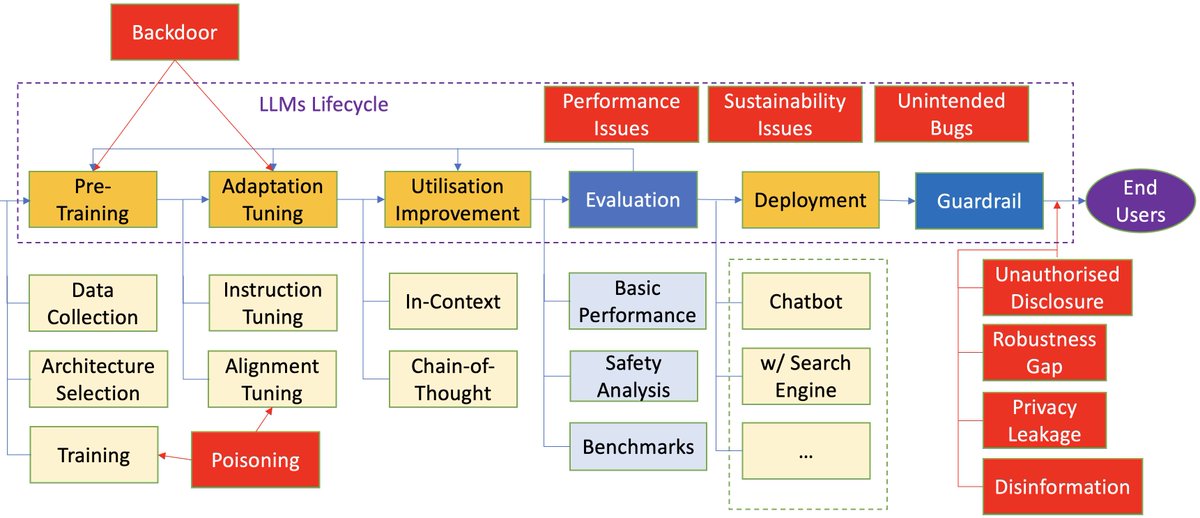
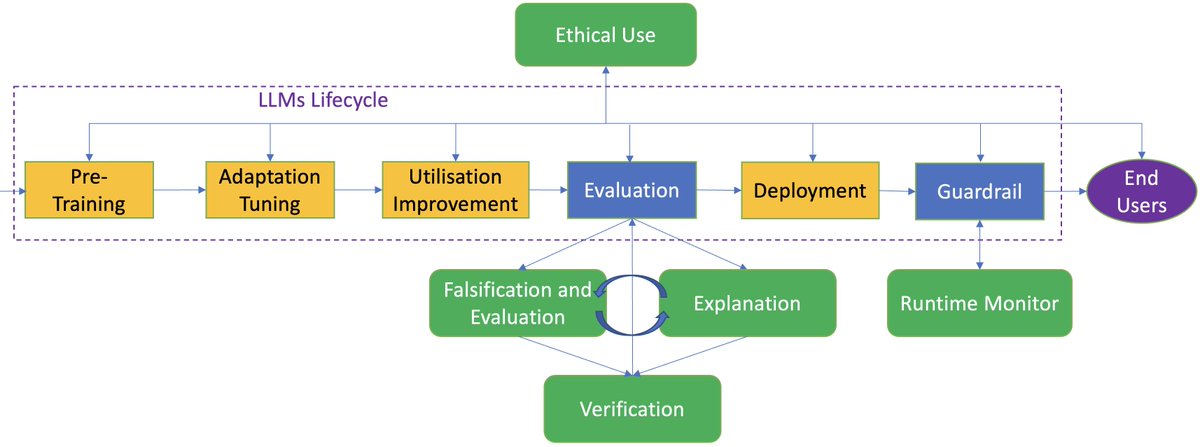
LLMs -- we completed a survey with 300+ references, trying to summarise the known vulnerabilities of LLMs and discuss whether and how the verification and validation (V&V) techniques can be adapted to work with LLMs. The paper is now available at ArXiv: https://t.co/abpHpS6Idb .
Would be great if we can receive submissions regarding large language models and ChatGPT for interesting discussions in the workshop. https://t.co/AboJOmL68O
JUST IN - Elon Musk tells Tucker Carlson that various government agencies had full access to everything that's going on Twitter.. including people's DMs (direct messages). Full interview on 8 pm ET Monday!!!