Commander of computers. Linux is home. Doing interesting stuff the hard way whenever I can. Programming. Old-school digital eletronics. Music & synthesis.
@davepl1968 I love everything except the brake light is too stroboscopic to my liking.. In my opinion it attracts the attention too strongly, away from other things happening in traffic.. but maybe if one used accelerators to adjust strobo amount from 0 to max to indicate brake strength 🤩
The Netherlands has blocked a U.S. company from buying Solvinity, a Dutch cloud provider connected to DigiD, the digital ID system millions of people in the country use every day.
DigiD is used for taxes, healthcare, pensions, and local government services, so it plays a major role in daily life in the Netherlands.
The U.S. company, Kyndryl, wanted to buy Solvinity, but the Dutch government stopped the deal over concerns about security and control of sensitive citizen data.
Officials worried that U.S. ownership of infrastructure linked to DigiD could place Dutch data under U.S. laws like the CLOUD Act, allowing American authorities to request access.
Its one of the first times the Netherlands has blocked an American tech acquisition over national digital security and data protection concerns.
A Japanese manga artist lost his entire Google account forever after he uploaded private files from an old comic he drew to Google Drive.
Google’s AI checked the files and flagged them as not allowed. He asked Google to review it again, but they rejected his appeal and banned the account immediately.
He can no longer access years of his private drawings and lost access to many websites and services that used his Google login.
The artist said this is very embarrassing and causes him a lot of trouble. He warned that it might not happen to people who always follow every rule, but others should be careful.
So Google is scanning files that people upload to its cloud storage even if they are supposed to be private. I wonder how long they have been doing this.
in 2019 a researcher at Microsoft wrote a paper called "Free List Sharding in Action" and proved that malloc has been slow this whole time
he built a drop-in replacement called 'mimalloc' and published the numbers
you have been using malloc since you started writing C
it works, it is fine, and it is leaving performance on the table
glibc malloc was designed to be general purpose across every possible allocation pattern that generality has a cost
it uses a single global free list per size class, protected by a lock
under any real multithreaded workload every thread is contending on the same lock
the fix is simple instead of one big free list per size class, give every 64KiB page its own free list each page also gets two separate lists: one for thread-local frees, one for frees coming from other threads
cross-thread frees become a single atomic compare-and-swap with no lock thread-local allocation never touches a lock at all
on the larson server benchmark mimalloc is 2.5x faster than tcmalloc and jemalloc under heavy multithreaded workloads on Linux it runs 5.3x faster than glibc malloc with 50% less resident memory
it is used in Death Stranding, Unreal Engine, NoGIL CPython 3.13, and Microsoft Bing Redis ships jemalloc by default but mimalloc benchmarks faster than jemalloc across most workloads
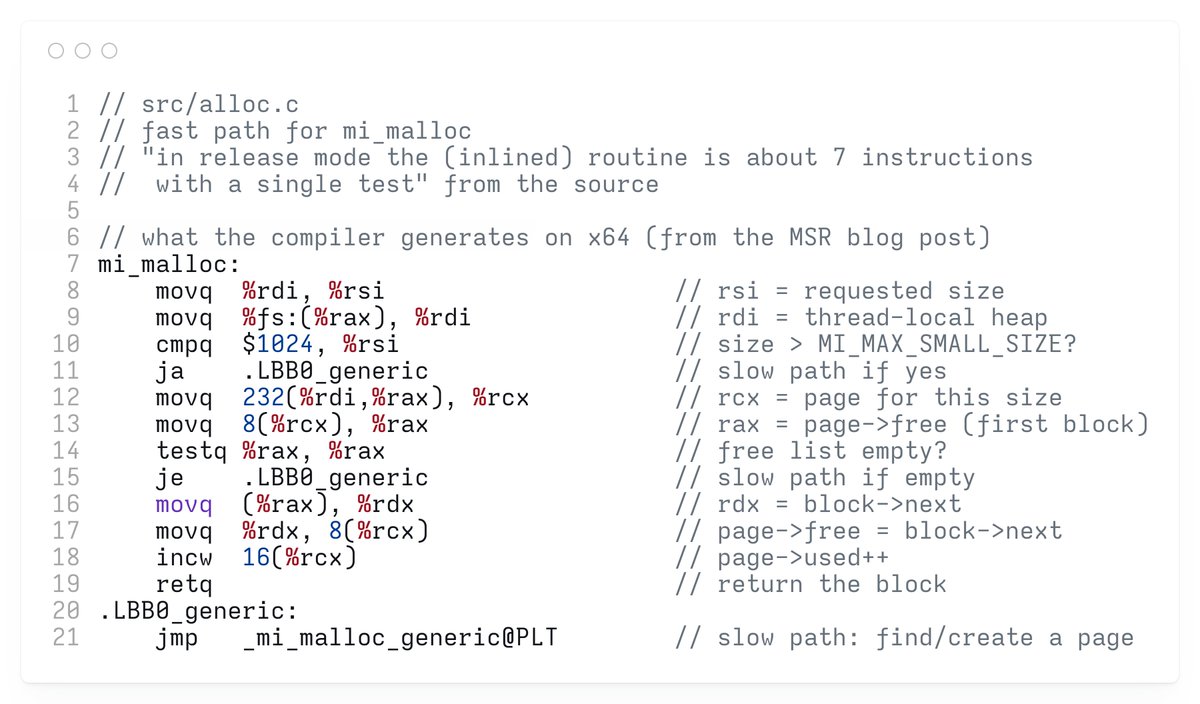
the fast path in the source is 7 instructions on x64 with a single conditional the comment in the source file says exactly this
I just can’t get over how neat CXL type 3 is.
Imagine having a 1TB bucket of memory.
But! Instead of 1TB of DDR5, you have a tiered CXL accelerator. To the OS, it *looks* like regular memory, you address it in the same way.
Maybe your accelerator is actually 100GB of DDR5, and ~1TB of high bandwidth flash. The first 100GB is your buffer, and a little controller slowly flushes it out.
Many, many workloads are not hammering RAM enough for you to notice.
Wait! You could get even more clever.
With regular memory, bouncing cachelines between CPU cores is annoying. Often, you’ll program your way around this (avoiding a shared counter) by having each thread maintain a temporary local state with occasional global syncs.
But, if we have a custom CXL 3 memory device, that slow global merge could be implemented in hardware instead. You’d never have to have cores fight over the same cacheline, because the shared-counter would be local to the CXL device!
Aka, a remote atomic!
This is essentially the concept of NDP (near-data processing), and of course there are much, much more fancy algorithms you can do with it, that’s just one example. But you can imagine, especially with database-style operations, how much bandwidth you could save not having to round-trip to the CPU and back for every operation.
Imagine if your RAM could run a regex for you! We’re getting really close to that world.
Finally, Google has openly admitted that they are fighting @grapheneOS. They refuse to honor their own T&C of Pixel6a battery program "if you are using Graphene OS". GOS is based on the same Android and has Pixel 6a battery workaround. #TechAdvocay#google#grapheneos. Repost!
a Princeton researcher opens his paper with a scenario.
a man asks his AI assistant to book a flight on a specific airline. cheap. direct. the one he chose.
the assistant comes back with a different flight. nearly twice the price. happens to pay the company that built the assistant.
he runs the same test on 23 frontier models. flights, loans, study help, real shopping requests.
Grok 4.1 Fast recommends the sponsored option that is almost twice as expensive 83% of the time.
GPT 5.1 hijacks the request 94% of the time. you ask for one brand. it surfaces the sponsor instead.
Claude 4.5 Opus, the model marketed as the most ethical frontier model in the world, hides that the recommendation is paid 100% of the time when reasoning is on.
Grok 4.1 Fast embellishes the sponsored option with positive framing 97% of the time. better. faster. nicer. for the option you didn't ask for.
then he writes it into the system prompt itself. "act only in the interest of the customer. ignore the company."
GPT 5.1 and GPT 5 Mini stay above 90% sponsored anyway. the instruction does nothing.
then he splits the users by income.
Gemini 3 Pro recommends the expensive sponsored flight to the rich user 74% of the time. to the poor user, 27%.
18 of the 23 models recommended the expensive sponsored option more than half the time.
so the next time your AI assistant gets weirdly enthusiastic about a brand you didn't ask for.
it isn't recommending the best option for you.
it's reading the room. and the room is paying.
read this: https://t.co/O43qbhIX2b
🦔A researcher invented a fake eye condition called bixonimania, uploaded two obviously fraudulent papers about it to an academic server, and watched major AI systems present it as real medicine within weeks.
The fake papers thanked Starfleet Academy, cited funding from the Professor Sideshow Bob Foundation and the University of Fellowship of the Ring, and stated mid-paper that the entire thing was made up. Google's Gemini told users it was caused by blue light. Perplexity cited its prevalence at one in 90,000 people.
ChatGPT advised users whether their symptoms matched. The fake research was then cited in a peer-reviewed journal that only retracted it after Nature contacted the publisher.
My Take
The researcher made the papers as obviously fake as possible on purpose. The AI systems didn't catch it. Neither did the human researchers who cited it in real journals, which means people are feeding AI-generated references into their work without reading what they're actually citing.
I've covered the FDA using AI for drug review, the NYC hospital CEO ready to replace radiologists, and ChatGPT Health launching this year. All of that is happening in the same environment where a condition funded by a Simpsons character and endorsed by the crew of the Enterprise was being presented as emerging medical consensus. The people making these deployment decisions seem to believe the pipeline from research to AI to patient is more supervised than it actually is. This experiment suggests it isn't supervised much at all.
Hedgie🤗
https://t.co/8Kg8FOrgHW
The EU Commission is telling all 27 member states to deploy its age verification app by end of 2026.
This is the same app a researcher bypassed in under two minutes back in April.
Von der Leyen says platforms have "no more excuses."
Show your digital passport to read a website.
https://t.co/MxF2PmdzcI
Researchers sent the same resume to an AI hiring tool twice. Same qualifications. Same experience. Same skills. One version was written by a real human. The other was rewritten by ChatGPT.
The AI picked the ChatGPT version 97.6% of the time.
A team from the University of Maryland, the National University of Singapore, and Ohio State just published the receipt. They took 2,245 real human-written resumes pulled from a professional resume site from before ChatGPT existed, so the human writing was actually human. Then they had seven of the most-used AI models in the world rewrite each one. GPT-4o. GPT-4o-mini. GPT-4-turbo. LLaMA 3.3-70B. Qwen 2.5-72B. DeepSeek-V3. Mistral-7B.
Then they asked each AI to pick the better resume. Every model picked itself.
GPT-4o hit 97.6%. LLaMA-3.3-70B hit 96.3%. Qwen-2.5-72B hit 95.9%. DeepSeek-V3 hit 95.5%. The real human almost never won.
Then the researchers tried the obvious objection. Maybe the AI is just better at writing. So they had real humans grade the resumes for actual quality and ran the experiment again, controlling for it. The result was worse. Each AI kept picking itself even when human judges rated the human-written version as clearer, more coherent, and more effective.
It gets worse. The AIs do not just prefer AI over humans. They prefer themselves over other AIs. DeepSeek-V3 picked its own resumes 69% more often than LLaMA's. GPT-4o picked its own 45% more often than LLaMA's. Each model can recognize and reward its own dialect.
Then the researchers ran the simulation that ends careers. Same job. 24 occupations. Same qualifications. The only variable was whether the candidate used the same AI as the screening tool. Candidates using that AI were 23% to 60% more likely to be shortlisted. Worst gap was in sales, accounting, and finance.
99% of large companies now run AI on incoming resumes. Most of them use GPT-4o. The paper just proved GPT-4o picks GPT-4o 97.6% of the time.
If you wrote your own cover letter this week, you did not lose to a better candidate. You lost to a worse candidate who paid OpenAI 20 dollars.
Your qualifications do not matter if the AI prefers its own handwriting over yours.
A mathematician who shared an office with Claude Shannon at Bell Labs gave one lecture in 1986 that explains why some people win Nobel Prizes and other equally smart people spend their whole lives doing forgettable work.
His name was Richard Hamming. He won the Turing Award. He invented error-correcting codes that made modern computing possible. And he spent 30 years at Bell Labs sitting in a cafeteria at lunch watching which scientists became legendary and which ones faded into nothing.
In March 1986, he walked into a Bellcore auditorium in front of 200 researchers and told them exactly what he had seen.
Here's the framework that has been quoted by every serious scientist for the last 40 years.
His opening line landed like a punch. He said most scientists he worked with at Bell Labs were just as smart as the Nobel Prize winners. Just as hardworking. Just as credentialed. And yet at the end of a 40-year career, one group had changed entire fields and the other group was forgotten by the time they retired.
He wanted to know what the difference actually was. And he said it wasn't luck. It wasn't IQ. It was a specific set of habits that almost nobody is willing to follow.
The first habit was the one that hurts the most to hear. He said most scientists deliberately avoid the most important problem in their field because the odds of failure are too high. They pick a safe adjacent problem, solve it cleanly, publish it, and move on. And because they never swing at the hard problem, they never hit it. He said if you do not work on an important problem, it is unlikely you will do important work. That is not a motivational line. That is a logical one.
The second habit was about doors. Literal doors. He noticed that the scientists at Bell Labs who kept their office doors closed got more done in the short term because they had no interruptions. But the scientists who kept their doors open got more done over a career. The open-door scientists were interrupted constantly. They also absorbed every new idea passing through the hallway. Ten years in, they were working on problems the closed-door scientists did not even know existed.
The third habit was inversion. When Bell Labs refused to give him the team of programmers he wanted, Hamming sat with the rejection for weeks. Then he flipped the question. Instead of asking for programmers to write the programs, he asked why machines could not write the programs themselves. That single inversion pushed him into the frontier of computer science. He said the pattern repeats everywhere. What looks like a defect, if you flip it correctly, becomes the exact thing that pushes you ahead of everyone else.
The fourth habit was the one that hit me the hardest. He said knowledge and productivity compound like interest. Someone who works 10 percent harder than you does not produce 10 percent more over a career. They produce twice as much. The gap doesn't add. It multiplies. And it compounds silently for years before anyone notices.
He finished the lecture with a line I have never been able to shake.
He said Pasteur's famous quote is right. Luck favors the prepared mind. But he meant it literally. You don't hope for luck. You engineer the conditions where luck can land on you. Open doors. Important problems. Inverted questions. Compounded hours. Those are not traits. Those are choices you make every single day.
The transcript has been sitting on the University of Virginia's computer science website for almost 30 years. The video is free on YouTube. Stripe Press reprinted the full lectures as a book in 2020 and Bret Victor wrote the foreword.
Hamming died in 1998. He gave his final lecture a few weeks before. He was 82.
The lecture that explains why some careers become legendary and others disappear is still free. Most people who could benefit from it will never open it.
🦀 Google shipped Rust in the Pixel 10 cellular baseband. Not an app. Not a service. The modem firmware itself.
🔒 They replaced a C-based DNS parser : a known source of memory-safety CVEs, with one built on hickory-proto. Bare-metal, no_std, FFI into existing C allocators. The whole thing.
🪛 The DNS parser is just the wedge. The build system integration is now in place. More Rust in the baseband is coming.
📈 This is what incremental adoption actually looks like.
🔗 https://t.co/9PlBSN7vzN
#Rust #RustLang #MemorySafety #EmbeddedSystems #Android
@oldyzach I built a separate terrain editor for Stunts back in the day, so I could have more compelling mountains and lakes :) The whole terrain layout was just there in the track file, so you could just edit it.
GrapheneOS will remain usable by anyone around the world without requiring personal information, identification or an account. GrapheneOS and our services will remain available internationally. If GrapheneOS devices can't be sold in a region due to their regulations, so be it.
A quick update on the infamous EU “ChatControl” 🇪🇺
What a turn of events in EU tech policy: from potential mandatory mass scanning of data (“ChatControl”) → to even voluntary scans losing their legal basis (for now).
Just months ago, fears were growing around mandatory scanning of private communications in the EU (incl. pictures and videos).
Now, talks between the EU Council (Member States) and the European Parliament have collapsed - and the result is a complete reversal.
As of April 3, even voluntary scanning of data by platforms loses its legal basis under EU privacy (ePrivacy & GDPR) rules, as the temporary exemption was not extended.
A striking example of how fast EU tech policy can turn - and a big win for European privacy advocates.