Merry Christmas to the half of the world right now while the other half is still counting down. 2025 has been an amazing year for @Gradient_HQ let’s carry on for something bigger and better for 2k26.
🚀 𝗖𝗟𝗔𝗪𝗕𝗢𝗫 𝗜𝗦 𝗛𝗘𝗥𝗘!
Run powerful OpenClaw AI agents locally with zero CLI stress. Clean Tauri app, easy wizard & dashboard for chats, cron jobs, skills & Souls.
Open source. Your agents, your rules.
🔹Grab it on GitHub
@Gradient_HQ#ClawBox#OpenSource
xAI has a lot of underutilized capacity that could be used as a white labeling service for the neoclouds who haven’t finished building their infra, fulfill those signed commitments to boost rev
also distributed training is music to my ears cc @Gradient_HQ
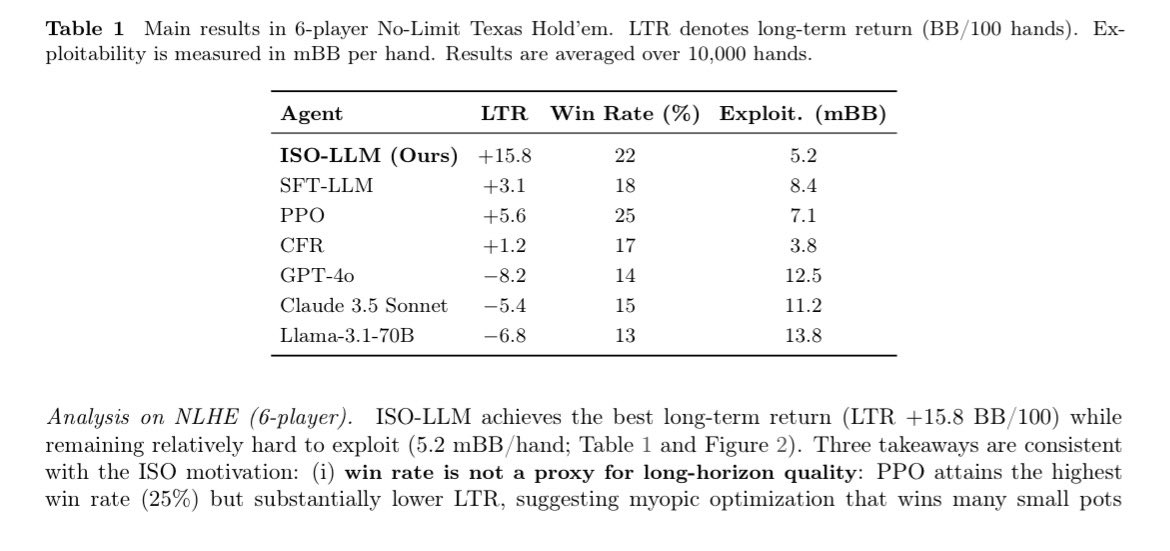
ISO-LLM cashes in profitability with the highest long term return by nearly 3x against PPO (second place) and exploitability at 5.2 mBB, the measurement of how easily an opponent can learn to beat you.
Despite PPO having an overall higher win percentage at 25% vs 22% on ISO, it’s a bread crumb chaser while ISO gets the loaf in LTR of +15.8 vs PPO’s +5.6, getting nearly 3x the bag.
This proves that ISO prioritizes high level strategies that lead to consistent long term success, unlike PPO going for short term gains through the wins of many small, insignificant pots but likely loses very large ones. 💰 @Gradient_HQ
Gradarch for @Gradient_HQ Overview 🎴
Improving intelligence, post training, better economics and accessibility
- Messari overview
- Chain Of Thought deep dive
- AOI
- Supercycle Pod
🚨🚨 DECK PARTY ALERT 🚨🚨
@xTUBOL has officially lost his mind AND his money 💸🧠
Sweeping floors like the world ends TODAY. No hesitation. No mercy. Just pure conviction.
This isn’t buying.
This is WAR MODE ACCUMULATION.
If you’re still “waiting for a dip” while this man is emptying the clip…
you’re already late.
🧹🧹🧹
SEND IT.
Graduary for @Gradient_HQ Overview 🏔️
The ship continues throughout January as Gradient kicks off the year!
- Parallax GLM 4.7 Flash
- Parallax MiniMax M2.1
- DSD Demo Video
- VeriLLM Demo Video
- AAAI Presentation
Another masterpiece from @Gradient_HQ team solving one of the most important problems in distributed intelligence.
The solution for trust of inference and the cost of verification:
VeriLLM’s architecture organizes Node Groups and randomly assigns the inferencer/verifier in the same group:
User Request -> Role Assignment (VRF) -> Inference (Prefill + Decoder) -> Commit States (Merkle) -> Output Delivery -> Verifier Recomputation (Prefill) -> Verifier Commitment -> Sampling (VRF) -> Reveal & Voting -> Verify Proof -> Reward/Slash Based On Verification Results.
Since nodes don’t know which roles they are assigned they can’t choose when to be honest or dishonest and manipulate the system.
To bring economically viable scale to verification, VeriLLM verifiers recompute prefill on sampled positions (skipping decode) and compare hidden states to inferencer's commitments.
./ the @Gradient_HQ with another effective solution to a problem under its belt:
we made distributed inference verifiable with <1% overhead.
verification is critical for any distributed system. in a trustless network, actors may swap your 70B model for a cheaper 8B one to cut costs.
until now, maintaining inference integrity meant either doubling your cost (redundancy) or exploding your latency (zkp).
we created veri: an on-chain verification layer light enough for high-throughput frameworks like Parallax. it hits the economic sweet spot through architectural elegance:
1. commit-sample-verify
we don't prove every step; we check a random slice using game theory. workers commit to their work before the audit. cheating becomes statistically irrational, allowing a 1% sample to secure the entire sequence.
2. simultaneous execution
inference and verification happen simultaneously on the same worker pool. we don't need a separate "verifier set", so compute utilization stays high.
find out more about the architecture and benchmarks:
paper: https://t.co/0nEhVzNQUe
blog: https://t.co/ULpLUqtGmz
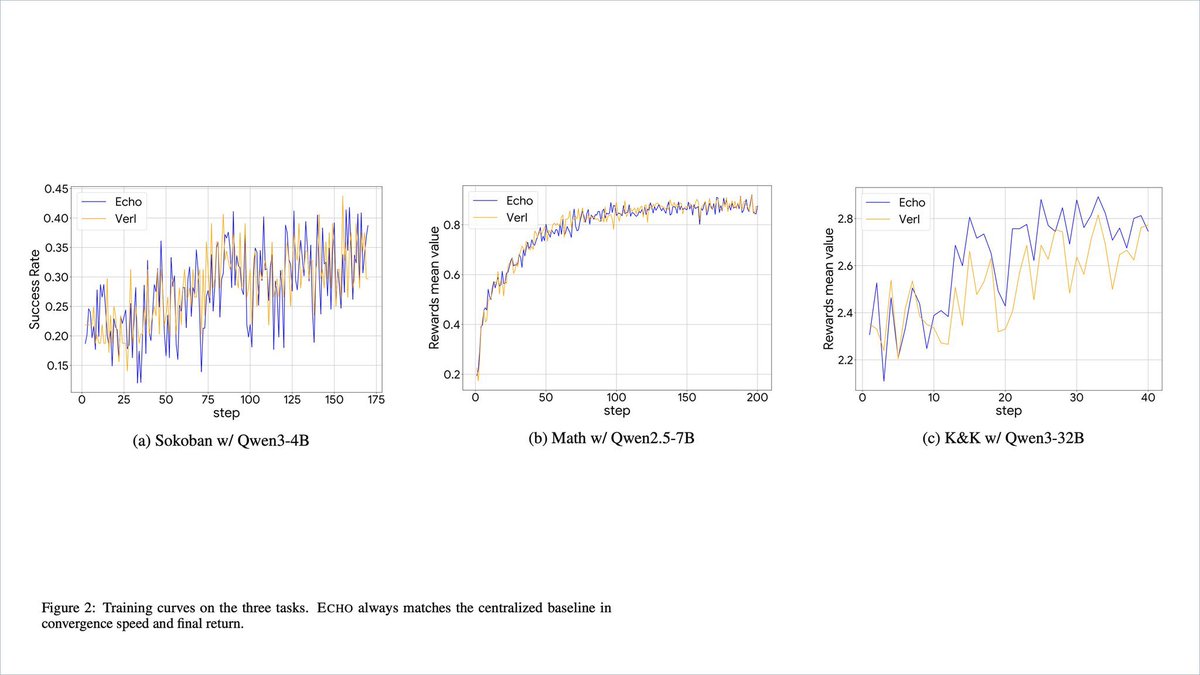
The architecture of Echo solves a critical challenge within the co located RL framework. By separating inferencing and training into independent swarms, it addresses the interruptions between switching back and forth from inferencing -> training and training -> inferencing.
This is a benchmark of Echo vs VERL’s co located A100s with tasks in Sokoban, Mathematics, Knight & Knaves logic.
Echo by @Gradient_HQ delivers equivalent results across the board with half the highend capacity gpu usage by leveraging heterogeneous 5090s & M4 Macs for inferencing. This demonstrates that large scale RL can achieve full datacenter performance using heterogeneous distributed infrastructure.
As we head into 2026, here are some of @Gradient_HQ wonderful innovations in 2025:
Echo RL - Large Scale Reinforcement Learning Alignment
Parallax - Sovereign AI OS, Global Cluster Scale
Lattica - Universal Communication
SEDM - Scalable Self Evolving Distributed Memory
Symphony - Decentralized Multi Agent System
OIS - Open Intelligence Stack
./