AI companies in the 2020s is what Dell and Intel was to the boomers back in the 90s
Dell did so well back in the day 2,700 employees became millionaires and nicknamed “Dellionaires”
AI is a appreciative asset, open source leading the way
CPU semis on a real run.
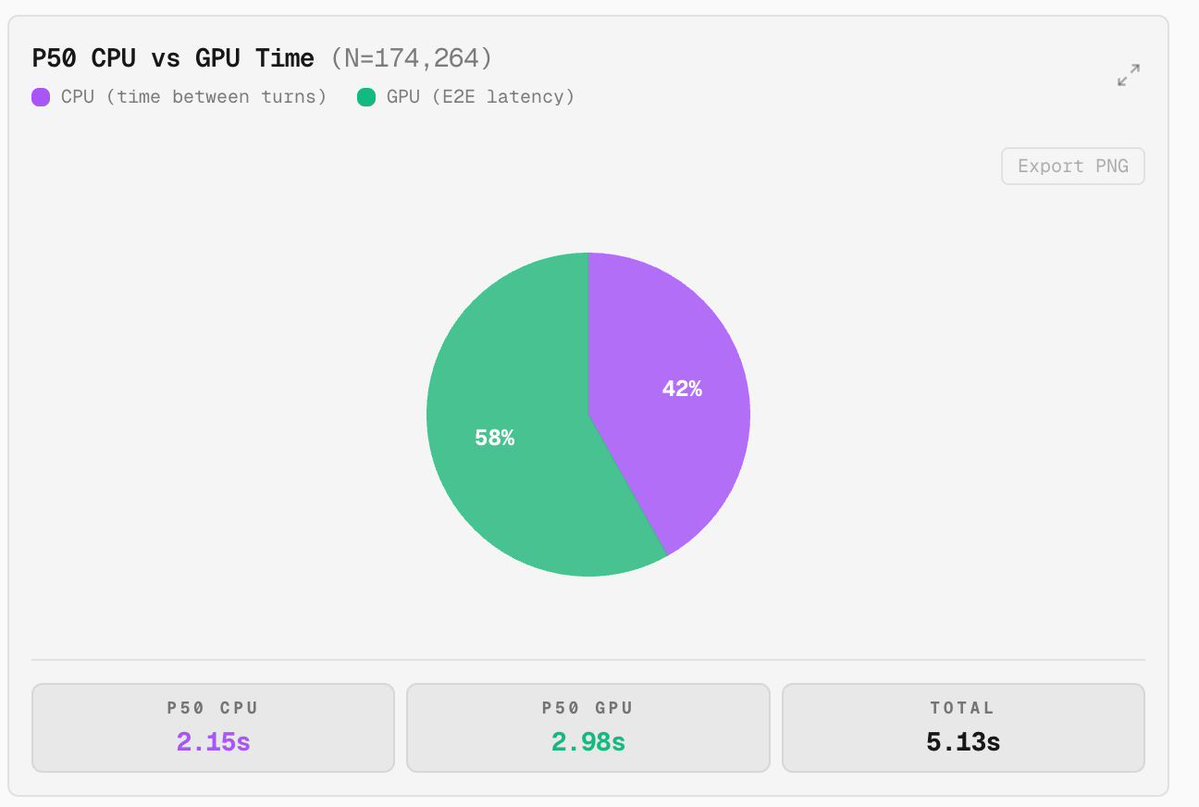
agentic AI uses cpu as task orchestrators for memory, i/o and enforcement as the gpu processes the reasoning for AI (core inference)
context windows, data movement and tool calling are heavily cpu based.
M3 delivers. outperforms Opus 4.7 in BrowserComp.
MiniMax’s first 1M context model pretty much 5x context from its previous models of around 204,800
and it supports video input too, multimodal built in as core.. 🥴🎥
beautiful.
and agentic token usage growth expectations look like this btw.
if you cannot supply, the price goes vertical. bullish on local and distributed edge ai inference.
JPM on '27 data center build out:
"The latest analysis based on satellite images shows that over 60% of data center capacity planned for completion in 2027 has not begun construction with another 7% delayed"
emerging markets with critical AI supply chains significantly outgrew the US in returns
once the countries with critical supply chains are removed so does the growth
AI boom currently is not being equally felt across the globe, open source models filling some access gaps in AI
Gemini 3.5 Flash from Google is on @commonstack_ai!
This is Google’s most intelligent model for sustained frontier performance on agentic and coding tasks matching or surpassing many other models at a fraction of the cost.
Build and try out now!
ByteDance, TikTok’s parent company is considering to more than 2x their capex from 30 billion dollars to 70 billion dollars.
Infrastructure spending continues to go vertical. One of the most popular AI apps in China is Doubao which is created by ByteDance.
Multi turn harness, the construction pipeline of TwinRouterBench, designed to optimize the cost efficiency of LLM workflows.
The process:
It starts with a successful interaction (trace) generated by a high end "strong" model > It isolates the critical parts of the interaction to create more concise data points > attempts to swap out expensive model calls for cheaper ones (the 'l', 'm', 'mh', 'h' labels represent Low, Mid, Mid-High, and High tiers) > It runs these "downgraded" sequences through a Multi turn task harness. If the cheaper model still results in a successful task completion, the downgrade is accepted > The final result is a "verified tier label" for every single LLM call in a sequence, showing exactly where a cheap model is "enough" and where a powerful model is "necessary."
This benchmark provides High Fidelity Training Data, creating a dataset of "optimal routing" decisions. This data can be used to train specialized "Router" models that decide in real time which LLM to call for a specific prompt. Previously the standard benchmarks grade a whole conversation, this provides granular labels for individual turns within a complex task
Running every prompt through the most powerful model is too expensive, but using only cheap models leads to task failure. TwinRouterBench helps find the balance of actual work completion at the most effective pricing.
Traditional routing is easy for single questions but very hard for multi step agent workflows. By focusing on execution-based verification, you get a more experienced version of reality grounded towards truth.
TwinRouterBench is a new benchmark designed for step level routing in long horizon, multi turn agentic workflows. Differing from traditional routing benchmarks that focus on single prompt routing, TwinRouterBench evaluates how well a "router" can choose the right model for each individual step of a complex task.
It implements dual tracks evaluation between fast development and realistic testing:
Track 1: Static Track (Fast Offline Track)
• 970 router visible prefixes from 520 trajectory instances.
• Covers 5 diverse benchmarks: SWE-bench, BFCL, mtRAG, QMSum, and PinchBench.
• Each example comes with an execution verified target tier (cheapest sufficient model tier).
• Uses deterministic scoring (based on tier correctness, trajectory membership, and token cost) no LLM judges needed.
Ideal for: training routers, rapid iteration, and cheap offline evaluation.
Track 2: Dynamic Track (Live Validation Track)
• Full evaluation harness on SWE-bench Verified (500 tasks).
• Reports results on a 100 case heldout split (disjoint from static data).
• Router must choose a real model from a locked pool at every step.
• Measures real outcomes: Official task resolution success, Actual API spend (real dollars), Includes failure penalties for unresolved tasks
By providing both a Static (fixed) and Dynamic (flowing) track, TwinRouterBench solves the problem where a router looks good on paper but fails when the agent actually has to live with its choices.
TwinRouterBench is set for the agentic era where every step is measured in routing vs just one shot prompt testing. This benchmark targets the realism distortion by testing routing within the actual context of multi step, stateful agent trajectories.
TwinRouterBench is a new benchmark designed for step level routing in long horizon, multi turn agentic workflows. Differing from traditional routing benchmarks that focus on single prompt routing, TwinRouterBench evaluates how well a "router" can choose the right model for each individual step of a complex task.
It implements dual tracks evaluation between fast development and realistic testing:
Track 1: Static Track (Fast Offline Track)
• 970 router visible prefixes from 520 trajectory instances.
• Covers 5 diverse benchmarks: SWE-bench, BFCL, mtRAG, QMSum, and PinchBench.
• Each example comes with an execution verified target tier (cheapest sufficient model tier).
• Uses deterministic scoring (based on tier correctness, trajectory membership, and token cost) no LLM judges needed.
Ideal for: training routers, rapid iteration, and cheap offline evaluation.
Track 2: Dynamic Track (Live Validation Track)
• Full evaluation harness on SWE-bench Verified (500 tasks).
• Reports results on a 100 case heldout split (disjoint from static data).
• Router must choose a real model from a locked pool at every step.
• Measures real outcomes: Official task resolution success, Actual API spend (real dollars), Includes failure penalties for unresolved tasks
By providing both a Static (fixed) and Dynamic (flowing) track, TwinRouterBench solves the problem where a router looks good on paper but fails when the agent actually has to live with its choices.
TwinRouterBench is set for the agentic era where every step is measured in routing vs just one shot prompt testing. This benchmark targets the realism distortion by testing routing within the actual context of multi step, stateful agent trajectories.
Great to see TwinRouterBench accepted to the #RLEval Workshop at #CAIS2026!
Per-step routing is quickly becoming essential infrastructure for agentic systems: each planning, coding, retrieval, and verification call should use the cheapest sufficient model without hurting final task success.
Proud to open-source TwinRouterBench and contribute a practical benchmark for this problem.
this will probably carry over to robotics as well
great bets can be made on heterogeneous flops, agentic models ripping cloud cpu prices higher
jensen wasn’t kidding about a new $200B market for Nvidia
FACT ALERT 🚨 : In modern agentic coding, 42% of the time is spent on CPU doing tool use such as editing files, running Bash scripts, running lints, etc. The economy of traditional cloud computing charges at $ per cpu core. In the economy of agents, the business model is $ per token thus to increase token revenue, you need to increase the amount of CPUs power u have so that you can generate your tokens.