RLVR has become the recipe for agentic post-training. But for Computer-Use Agents, the bottleneck is not the algorithm, it is the data. 🐌
🚀 We introduce CUA-Gym: a scalable, lightweight synthesis engine that turns arbitrary task queries into verifiable RLVR data for computer-use agents. The largest open CUA RLVR dataset to date:
🎯 32,122 verifiable RLVR tasks with programmatic setup scripts + rewards
🌐 110 environments: 16 desktop apps + 94 synthesized mock web apps
🏆 Qwen3.5-based CUA models trained with GSPO reach 72.6% on OSWorld-Verified and 56.6% on WebArena
📄 Paper: https://t.co/cdvHJPzgb1
🏠 Homepage: https://t.co/kvhaOQxNx7
🤗 Dataset: https://t.co/w5vOIRdchR
💻 Codebase: https://t.co/CcRlNTlS1c
🧩 Environments: https://t.co/fNZ6YAI8LD
🧵[1/6]
Introducing @NeoCognition, the agent lab for specialized intelligence.
Everyone needs experts, but human expertise does not scale.
Backed by $40M seed funding, we build self-learning agents that specialize across domains to make expertise abundant.
🍫 CocoaBench v1.0 is out!
CocoaBench is a benchmark for unified digital agents, built around open-world tasks that require composing 💻 coding, 👀 vision, 🌐 search.
Since our first research preview last December, we have expanded the benchmark substantially with community contributed tasks, and spent months testing and refining the tasks, evaluations, and agent runs.
Some takeaways:
• Even the best agent system reaches only 45.1% on CocoaBench v1.0.
• Coding agents like Codex are already surprisingly strong on general tasks beyond software engineering.
• Stronger agents tend to push more of the work into code.
• Open source models still lag behind leading frontier models on these general tasks.
👇More on the website and in the paper
#AI #Agents #LLM #Benchmark #CocoaBench
K2.5 also achieves #1 on the OSWorld leaderboard — the best open agentic model! Happy to be part of the team! Since OpenCUA was released last August, we’ve seen rapid leaps in agentic foundation models. Exciting to see open agentic models now reaching and even leading.
Kimi K2.5 tech report just dropped!
Quick hits:
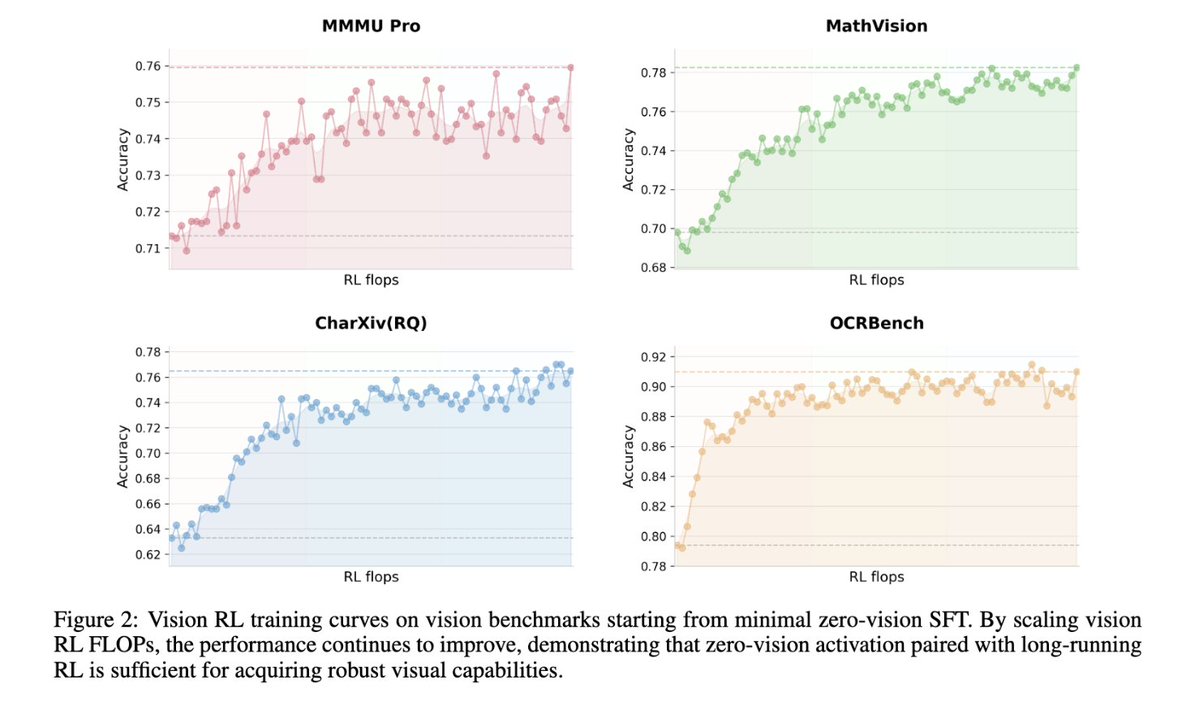
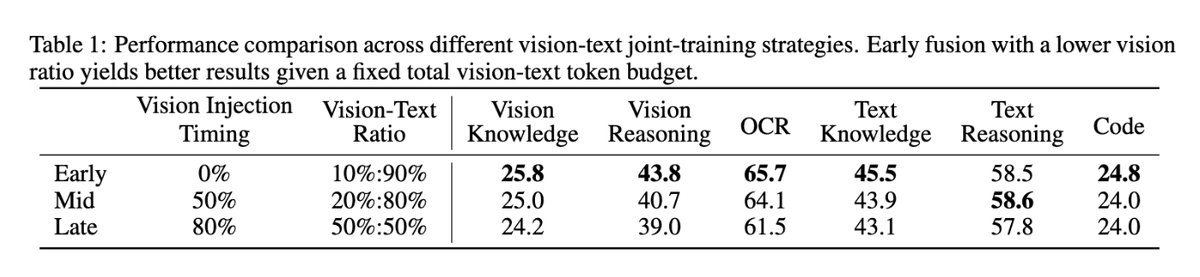
- Joint text–vision training: pretrained with 15T vision-text tokens, zero-vision SFT (text-only) to activate visual reasoning
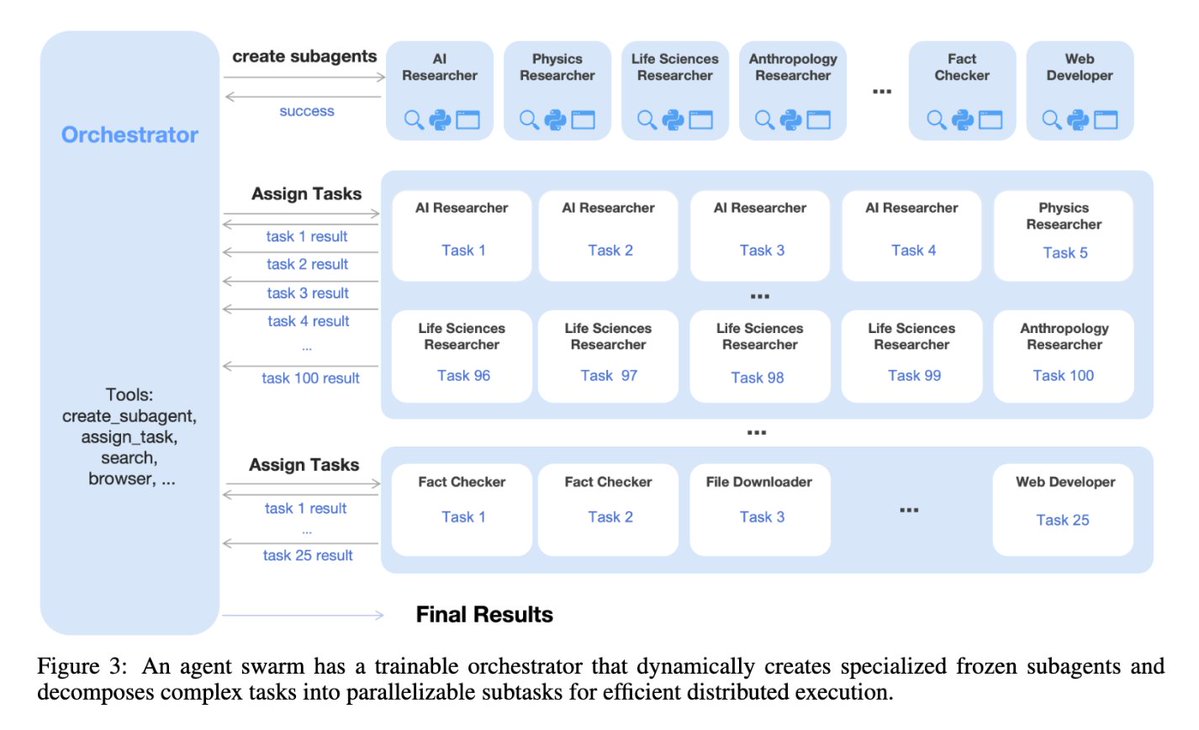
- Agent Swarm + PARL: dynamically orchestrated parallel sub-agents, up to 4.5× lower latency, 78.4% on BrowseComp
- MoonViT-3D: a unified image–video encoder with 4× temporal compression, enabling 4× longer videos in the same context
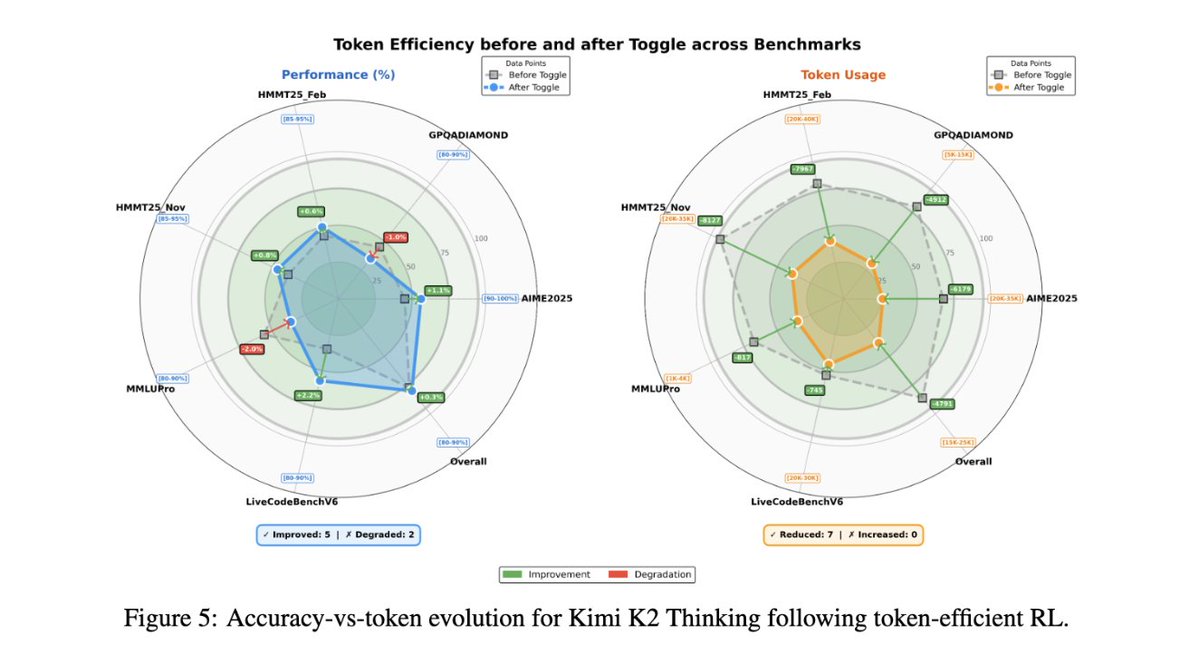
- Toggle: token-efficient RL, 25–30% fewer tokens with no accuracy drop
Here's our work toward scalable, real-world agentic intelligence. More details in the report 👉https://t.co/N5pwm0M4jm
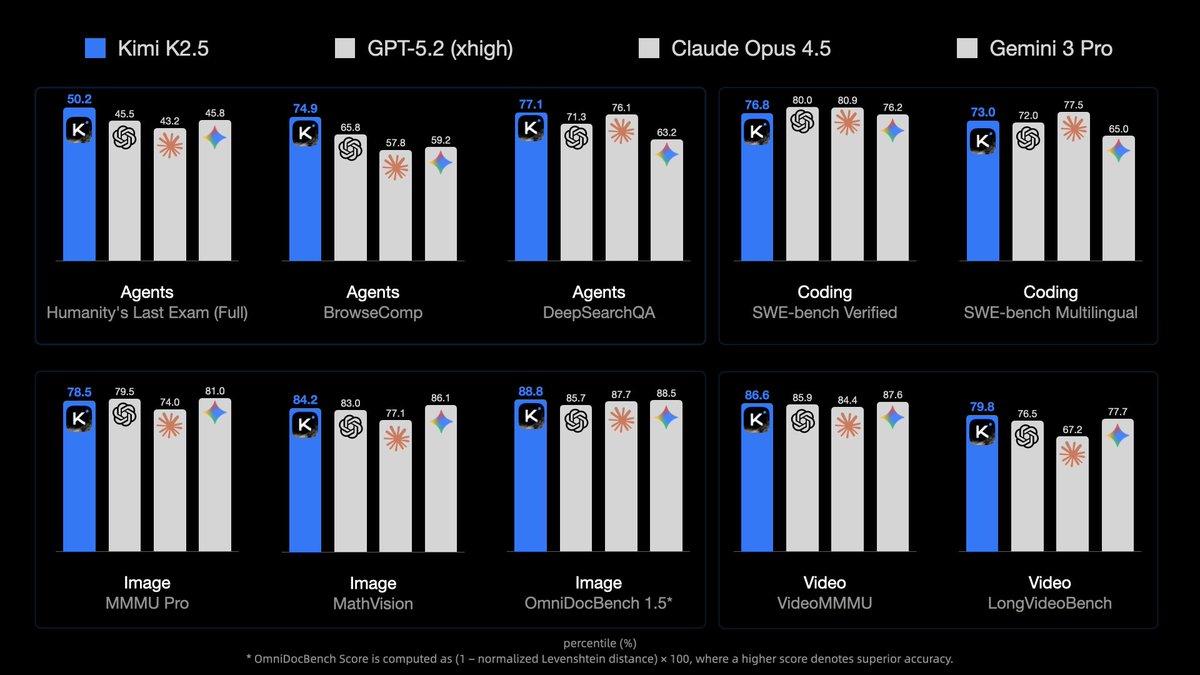
🥝Meet Kimi K2.5, Open-Source Visual Agentic Intelligence.
🔹Global SOTA on Agentic Benchmarks: HLE full set (50.2%), BrowseComp (74.9%)
🔹Open-source SOTA on Vision and Coding: MMMU Pro (78.5%), VideoMMMU (86.6%), SWE-bench Verified (76.8%)
🔹Code with Taste: turn chats, images & videos into aesthetic websites with expressive motion.
🔹Agent Swarm (Beta): self-directed agents working in parallel, at scale. Up to 100 sub-agents, 1,500 tool calls, 4.5× faster compared with single-agent setup.
-
🥝K2.5 is now live on https://t.co/YutVbwktG0 in chat mode and agent mode.
🥝K2.5 Agent Swarm in beta for high-tier users.
🥝For production-grade coding, you can pair K2.5 with Kimi Code: https://t.co/A5WQozJF3s
-
🔗 API: https://t.co/EOZkbOwCN4
🔗 Tech blog: https://t.co/6h2KkoA0xd
🔗 Weights & code: https://t.co/H38KegeDIY
Pretraining has scaling laws to guide compute allocation. But for RL on LLMs, we lack a practical guide on how to spend compute wisely.
We show the optimal compute allocation in LLM RL scales predictably.
↓ Key takeaways below
Pretraining has scaling laws to guide compute allocation. But for RL on LLMs, we lack a practical guide on how to spend compute wisely.
We show the optimal compute allocation in LLM RL scales predictably.
↓ Key takeaways below
You’ve done real work.
But most of it is hard to see.
DINQ brings your projects, code, and research onto one card.
No self-promotion. Just real signals.
Build your DINQ → https://t.co/IaEtN0Vkab
#DINQ
Excited that OpenCUA was accepted as a NeurIPS Spotlight! Our poster will be presented in San Diego Poster Session 3 on Thu Dec 4, 11:00 PST.
I’ll be in San Diego from Dec 3–5 — happy to chat if you’re around 😀
We are super excited to release OpenCUA — the first from 0 to 1 computer-use agent foundation model framework and open-source SOTA model OpenCUA-32B, matching top proprietary models on OSWorld-Verified, with full infrastructure and data.
🔗 [Paper] https://t.co/SYEio5ccNJ
📌 [Website] https://t.co/ma6bBuYiNM
🤖 [Models] https://t.co/7TVtIdjkmq
📊[Data] https://t.co/N6tQQwQkhs
💻 [Code] https://t.co/ihr8TXmG6k
🌟 OpenCUA — comprehensive open-source framework for computer-use agents, including:
📊 AgentNet — first large-scale CUA dataset (3 systems, 200+ apps & sites, 22.6K trajectories)
🏆 OpenCUA model — open-source SOTA on OSWorld-Verified (34.8% avg success, outperforms OpenAI CUA)
🖥 AgentNetTool — cross-system computer-use task annotation tool
🏁 AgentNetBench — offline CUA benchmark for fast, reproducible evaluation
💡 Why OpenCUA?
Proprietary CUAs like Claude or OpenAI CUA are impressive🤯 — but there’s no large-scale open desktop agent dataset or transparent pipeline. OpenCUA changes that by offering the full open-source stack 🛠: scalable cross-system data collection, effective data formulation, model training strategy, and reproducible evaluation — powering top open-source models including OpenCUA-7B and OpenCUA-32B that excel in GUI planning & grounding.
Details of OpenCUA framework👇
We are super excited to release OpenCUA — the first from 0 to 1 computer-use agent foundation model framework and open-source SOTA model OpenCUA-32B, matching top proprietary models on OSWorld-Verified, with full infrastructure and data.
🔗 [Paper] https://t.co/SYEio5ccNJ
📌 [Website] https://t.co/ma6bBuYiNM
🤖 [Models] https://t.co/7TVtIdjkmq
📊[Data] https://t.co/N6tQQwQkhs
💻 [Code] https://t.co/ihr8TXmG6k
🌟 OpenCUA — comprehensive open-source framework for computer-use agents, including:
📊 AgentNet — first large-scale CUA dataset (3 systems, 200+ apps & sites, 22.6K trajectories)
🏆 OpenCUA model — open-source SOTA on OSWorld-Verified (34.8% avg success, outperforms OpenAI CUA)
🖥 AgentNetTool — cross-system computer-use task annotation tool
🏁 AgentNetBench — offline CUA benchmark for fast, reproducible evaluation
💡 Why OpenCUA?
Proprietary CUAs like Claude or OpenAI CUA are impressive🤯 — but there’s no large-scale open desktop agent dataset or transparent pipeline. OpenCUA changes that by offering the full open-source stack 🛠: scalable cross-system data collection, effective data formulation, model training strategy, and reproducible evaluation — powering top open-source models including OpenCUA-7B and OpenCUA-32B that excel in GUI planning & grounding.
Details of OpenCUA framework👇
We are super excited to release OpenCUA — the first from 0 to 1 computer-use agent foundation model framework and open-source SOTA model OpenCUA-32B, matching top proprietary models on OSWorld-Verified, with full infrastructure and data.
🔗 [Paper] https://t.co/SYEio5ccNJ
📌 [Website] https://t.co/ma6bBuYiNM
🤖 [Models] https://t.co/7TVtIdjkmq
📊[Data] https://t.co/N6tQQwQkhs
💻 [Code] https://t.co/ihr8TXmG6k
🌟 OpenCUA — comprehensive open-source framework for computer-use agents, including:
📊 AgentNet — first large-scale CUA dataset (3 systems, 200+ apps & sites, 22.6K trajectories)
🏆 OpenCUA model — open-source SOTA on OSWorld-Verified (34.8% avg success, outperforms OpenAI CUA)
🖥 AgentNetTool — cross-system computer-use task annotation tool
🏁 AgentNetBench — offline CUA benchmark for fast, reproducible evaluation
💡 Why OpenCUA?
Proprietary CUAs like Claude or OpenAI CUA are impressive🤯 — but there’s no large-scale open desktop agent dataset or transparent pipeline. OpenCUA changes that by offering the full open-source stack 🛠: scalable cross-system data collection, effective data formulation, model training strategy, and reproducible evaluation — powering top open-source models including OpenCUA-7B and OpenCUA-32B that excel in GUI planning & grounding.
Details of OpenCUA framework👇
🔥Really excited to see the release of PAN world model, a project I had been working over the past years.
PAN is a general world model capable of simulating physical, agentic, and nested worlds, synthesizing infinite interactive experiences for training AI agents.
Building on top of pretrained LLMs and video diffusion models, PAN connects language, perception, action, and latent thoughts, for long-horizon simulation and reasoning.
PAN shows overwhelming performance gains over JEPA-2, Cosmos-2, and other prior models. More in the thread👇 ... 1/
🚀 Announcing GroundCUA, a high-quality dataset for grounding computer-use agents. With over 3M expert annotations spanning 87 desktop apps, we use our new dataset to train state-of-the-art grounding models, namely GroundNext-3B and GroundNext-7B.
👇 Thread
🚀 Hello, Kimi K2 Thinking!
The Open-Source Thinking Agent Model is here.
🔹 SOTA on HLE (44.9%) and BrowseComp (60.2%)
🔹 Executes up to 200 – 300 sequential tool calls without human interference
🔹 Excels in reasoning, agentic search, and coding
🔹 256K context window
Built as a thinking agent, K2 Thinking marks our latest efforts in test-time scaling — scaling both thinking tokens and tool-calling turns.
K2 Thinking is now live on https://t.co/YutVbwktG0 in chat mode, with full agentic mode coming soon. It is also accessible via API.
🔌 API is live: https://t.co/EOZkbOwCN4
🔗 Tech blog: https://t.co/n7xxaszqzF
🔗 Weights & code: https://t.co/4ukcXB0iP6
📣Introducing VideoAgentTrek: a human-free, web-scale pipeline that turns screen-recorded tutorials into training data for computer-use agents, powered by specially trained VLMs.
🔗 [Website] https://t.co/rxTDwNxgtw
📄 [Paper] https://t.co/SVgjCGUWhF














![xywang626's tweet photo. We are super excited to release OpenCUA — the first from 0 to 1 computer-use agent foundation model framework and open-source SOTA model OpenCUA-32B, matching top proprietary models on OSWorld-Verified, with full infrastructure and data.
🔗 [Paper] https://t.co/SYEio5ccNJ
📌 [Website] https://t.co/ma6bBuYiNM
🤖 [Models] https://t.co/7TVtIdjkmq
📊[Data] https://t.co/N6tQQwQkhs
💻 [Code] https://t.co/ihr8TXmG6k
🌟 OpenCUA — comprehensive open-source framework for computer-use agents, including:
📊 AgentNet — first large-scale CUA dataset (3 systems, 200+ apps & sites, 22.6K trajectories)
🏆 OpenCUA model — open-source SOTA on OSWorld-Verified (34.8% avg success, outperforms OpenAI CUA)
🖥 AgentNetTool — cross-system computer-use task annotation tool
🏁 AgentNetBench — offline CUA benchmark for fast, reproducible evaluation
💡 Why OpenCUA?
Proprietary CUAs like Claude or OpenAI CUA are impressive🤯 — but there’s no large-scale open desktop agent dataset or transparent pipeline. OpenCUA changes that by offering the full open-source stack 🛠: scalable cross-system data collection, effective data formulation, model training strategy, and reproducible evaluation — powering top open-source models including OpenCUA-7B and OpenCUA-32B that excel in GUI planning & grounding.
Details of OpenCUA framework👇](https://pbs.twimg.com/media/GyZzJc4bEAATQap.jpg)


![DunjieLu1219's tweet photo. 📣Introducing VideoAgentTrek: a human-free, web-scale pipeline that turns screen-recorded tutorials into training data for computer-use agents, powered by specially trained VLMs.
🔗 [Website] https://t.co/rxTDwNxgtw
📄 [Paper] https://t.co/SVgjCGUWhF https://t.co/cD49OjxkEC](https://pbs.twimg.com/media/G4B59kwXUAALpyF.jpg)






























