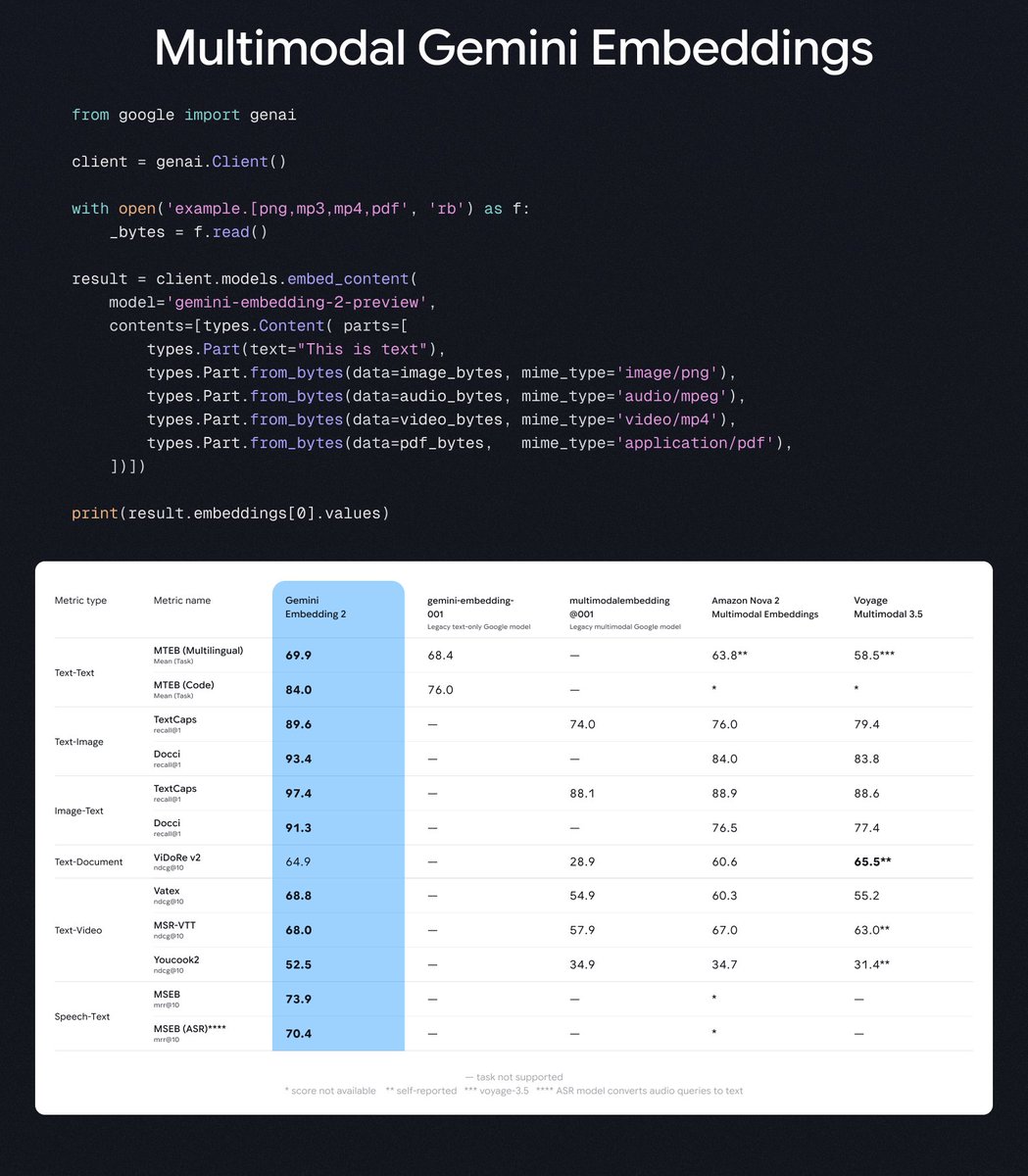
What if one embedding model could understand text, images, video, audio, and PDFs all at once? Excited to share Gemini Embedding 2 our first fully multimodal embedding model.
🖼️ 5 modalities in a single unified embedding space
🌍 Supports up to 8,192 input tokens, 100+ languages
🎧 Embeds audio natively, no transcription step needed
📐 Flexible output dimensions: 3,072 / 1,536 / 768 via MRL
📎 Up to 6 images, 120s video, and 6-page PDFs per request
Now in Public Preview via Gemini API & Vertex AI.