@jake_researcher@david_nix It's actually fine, subagent of opencode is have avg 10k context overhead. I'm using 2x160k context in parallel, so it's pretty fine. (3x3090). llama cpp as inference engine
@david_nix Enough for day to day tasks, edits, creating scripts, spawning subagents, biggest improvement is PLAN mode in @opencode it makes quality much higher. Most important part is architecture.
It's not yet level of top proprietary models or huge ones, but good enough already.
BIG DAY! Qwopus 27B v3 is LIVE from Jackrong! This is the third iteration from the line of the viral finetunes previously titled “Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled”
It is now simply Qwopus 27B and I love the name change!
On paper, the v3 is another remarkable improvement over v2! Most impressively it is the first model of the series that outperforms the base on HumanEval! And retains significant efficiency increases when thinking than the base Qwen 27b!
According to tests by @stevibe the V2 version was already performing very closely to the base model in bug finding and tool calling. V3 should exceed it!
In my own tests, V2 was the best front end design local model I’ve ever ran on a single GPU! And the efficiency improvements made it much more usable at long contexts, where base Qwen would think forever! I will be running full analysis on the v3 today in Hermes agent and I am very optimistic!
I have also had correspondence directly with Jackrong, and he is incredibly grateful for all of the support we’ve sent his way! The man is a genius and pouring a lot of time and effort into this work, so keep the downloads going and let us know your thoughts in the comments! We’ve exchanged contact info so we can keep up the feedback and momentum!
If you get a second, we’d love to see your tests! Let us know how it works for your use case and first impressions, and if you have any issues I will do my best to help out in the comments!
GGUF here and MLX in thread!
https://t.co/MaCW6QdKys
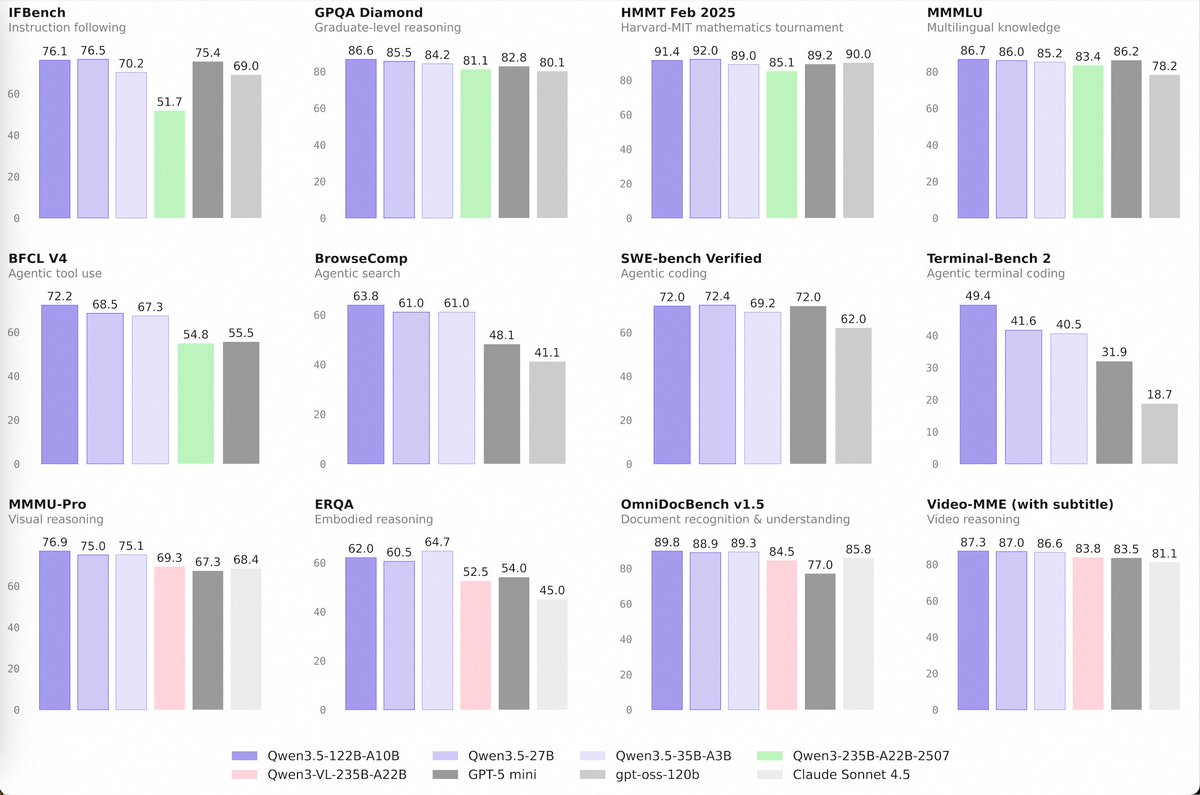
🚀 Introducing the Qwen 3.5 Medium Model Series
Qwen3.5-Flash · Qwen3.5-35B-A3B · Qwen3.5-122B-A10B · Qwen3.5-27B
✨ More intelligence, less compute.
• Qwen3.5-35B-A3B now surpasses Qwen3-235B-A22B-2507 and Qwen3-VL-235B-A22B — a reminder that better architecture, data quality, and RL can move intelligence forward, not just bigger parameter counts.
• Qwen3.5-122B-A10B and 27B continue narrowing the gap between medium-sized and frontier models — especially in more complex agent scenarios.
• Qwen3.5-Flash is the hosted production version aligned with 35B-A3B, featuring:
– 1M context length by default
– Official built-in tools
🔗 Hugging Face: https://t.co/wFMdX5pDjU
🔗 ModelScope: https://t.co/9NGXcIdCWI
🔗 Qwen3.5-Flash API: https://t.co/82ESSpaqAF
Try in Qwen Chat 👇
Flash: https://t.co/UkTL3JZxIK
27B: https://t.co/haKxG4lETy
35B-A3B: https://t.co/Oc1lYSTbwh
122B-A10B: https://t.co/hBMODXmh1o
Would love to hear what you build with it.
@TheSneerReview Blame Russia and EU no response since 2014 when occupation was ok for everyone, this is all consequences of "paper" NATO that can't shut down a drone