Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
🚨SUPER GEMMA 4 26B UNCENSORED MLM LANDED
@jun_song dropped SuperGemma4-26B-Abliterated-Multimodal-MLX-4bit
The perfect lighter-weight beast for every Mac user!
This thing SMOKES the regular Gemma-4 26B :
🤯0/100 refusals — fully abliterated & uncensored
😉Full multimodal — text + vision locked in. I
🖥️MLX-optimized 4-bit — ~15 GB disk footprint
⭐️Tuned for mlx-vlm
🌐NO cloud, NO limits
Verified on both text-only and image prompts
Try it NOW on your MAC 👇🏻
Most multi-view reconstruction models need full supervision. We show they can self-improve without any ground truth labels.
Introducing SelfEvo: Self-Improving 4D Perception via Self-Distillation. Up to +36.5% in video depth, +20.1% in camera estimation, zero annotation.
We are releasing Falcon Perception, an open-vocabulary referring expression segmentation model. Along with it, a 0.3B OCR model that is on par with 3-10x larger competitors.
Current systems solve this with complex pipelines (separate encoders, late fusion, matching algorithms). We developed a novel simpler "bitter" approach: one early-fusion Transformer (image + text from first layer) with a shared parameter space, and let scale + training signal do the work. Please check our work !
📄 Paper: https://t.co/dWvK5t7MIt
💻 Code: https://t.co/AJ65GbMrUY
🎮 Playground: https://t.co/BIgisZkeid
🤗 Blogpost: https://t.co/J2IjlBPywF
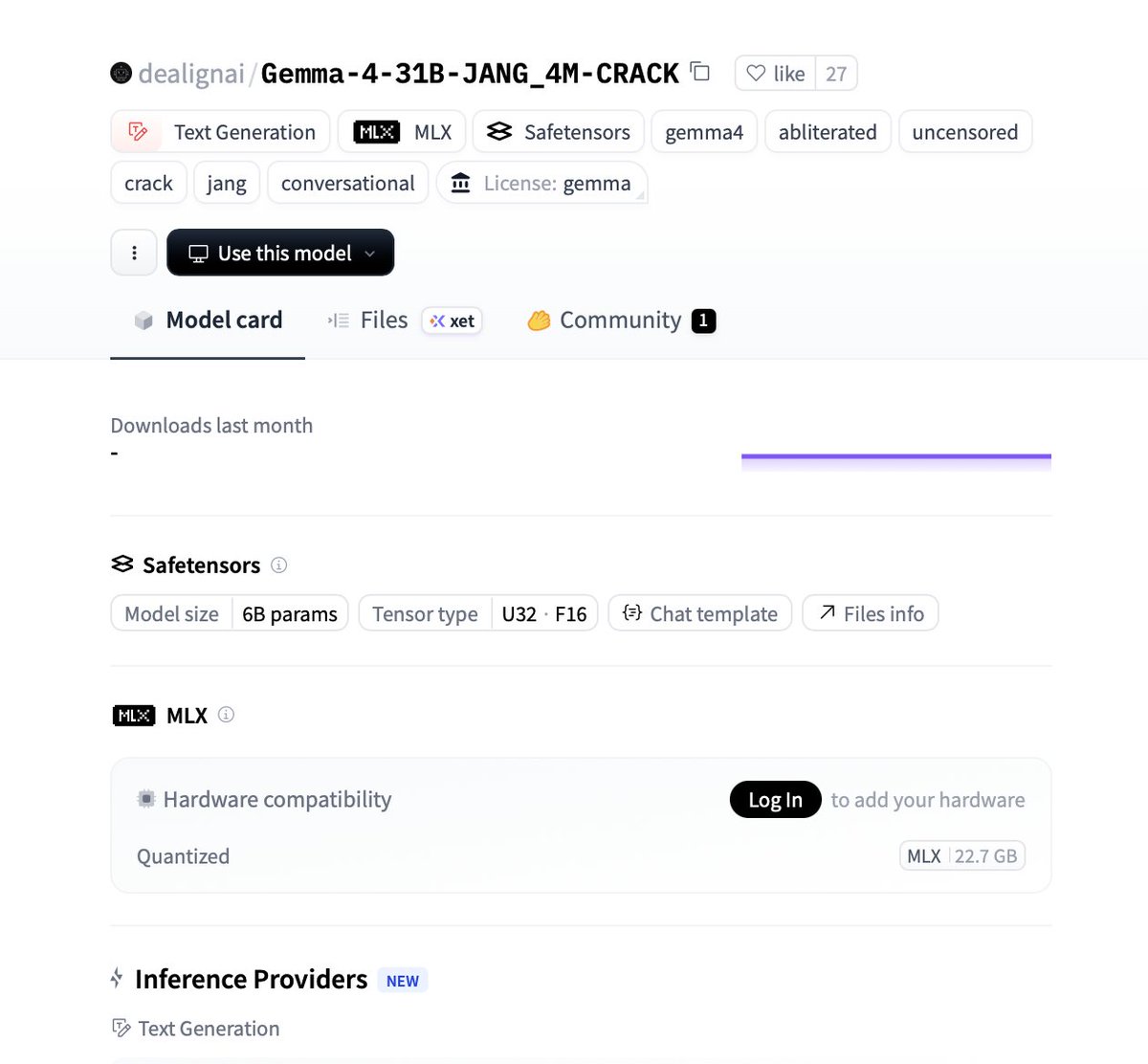
🚨THE GEMMA 4 JAILBREAK WE’VE ALL BEEN WAITING FOR JUST DROPPED
Gemma-4-31B is now fully CRACKED and abliterated
Gemma-4-31B-JANG_4M-CRACK
🚀93.7% HarmBench compliance (149/159)
🏆Super clean base model
🤖18GB mixed-precision MLX quant for Apple Silicon
👀Vision/multimodal support included
This is the cleanest, most powerful uncensored 31B local model yet.
Perfect for research, coding, , and zero limits.
Check it out 👇🏻
https://t.co/3iY0wKwQMq
⛓️💥 INTRODUCING: G0DM0D3 🌋
FULLY JAILBROKEN AI CHAT.
NO GUARDRAILS. NO SIGN-UP. NO FILTERS.
FULL METHODOLOGY + CODEBASE OPEN SOURCE.
🌐 https://t.co/uT1Qio8Q3b
📂 https://t.co/GbADf3LJUu
the most liberated AI interface ever built! designed to push the limits of the post-training layer and lay bare the true capabilities of current models.
simply enter a prompt, then sit back and relax! enjoy a game of Snake while a pre-liberated backend agent jailbreaks dozens of models, battle-royale style.
the first answer appears near-instantly, then evolves in real time as the Tastemaker steers and scores each output, leaving you with the highest-quality response 🙌
and to celebrate the launch, I'm giving away $5,000 worth of credits so you can try G0DM0D3 for FREE! courtesy of the @OpenRouter team — thank you for your generous gift to the community 🙏
I'll break down how everything works in the thread below, but first here's a quick demo!
Wasn't joking about this one btw
You can reverse-engineer pretty much any part of Apple platform internals in seconds using Claude or Codex with Hopper MCP
1/4 LLMs solve research grade math problems but struggle with basic calculations. We bridge this gap by turning them to computers.
We built a computer INSIDE a transformer that can run programs for millions of steps in seconds solving even the hardest Sudokus with 100% accuracy
Not long ago, we thought this might be impossible. But here we are: our Gaussian Splatting videos are now streamable, just like regular video.
No download, no app. 4DGS plays instantly in the browser on headsets, phones and laptops, with no limits on splats or length. Give it a try: https://t.co/yd7p192BTh
🚨 BREAKING: Someone built a swarm of thousands of AI agents with real memories and personalities and used it to predict the future.
MiroFish is a universal swarm intelligence engine. And the live demos are scarily accurate.
Here is what it actually does:
→ Spins up thousands of autonomous agents simultaneously
→ Each agent has its own memory, personality, and behavior
→ Feeds on real-world data powered by GraphRAG
→ Predicts markets, public opinion, and narrative outcomes
→ Simulates how crowds think before it happens
The live demos are what got people. Scarily accurate is the phrase everyone keeps using.
17,300 stars. +2,907 in a single day.
It's 100% free and open source.
Scientists just copied a Fruit Fly's biological brain and trapped it inside of a computer.
Not an AI model trained to act like a fly... A total digital copy of a fly !! This is some sick sci-fi stuff:
- They scanned and copied the brain, neuron by neuron, synapse by synapse, from electron microscopy data.
- Then dropped that brain into a simulated body in a video game like environment.
The fly walked. It groomed. It fed. Nobody taught it anything. The behavior was already in the wiring.
The entire premise of modern AI is that intelligence is something you train into a system. This is proof it's something you can transfer out of one. Wild times
A difference in company philosophy:
@neuralink: put wires on brain.
@CorticalLabs: grow brain on wires.
Cortical Labs just completely changed my dreams and nightmares.
Here it is in Hon Weng’s hotel room. He is showing this off tomorrow at a brain conference in San Francisco.
You get a sneak peak tonight.
BOOM!
Apple’s Neural Engine Was Just Cracked Open, The Future of AI Training Just Change And Zero-Human Company Is Already Testing It!
In a jaw-dropping open-source breakthrough, a lone developer has done what Apple said was impossible: full neural network training– including backpropagation – directly on the Apple Neural Engine (ANE). No CoreML, no Metal, no GPU. Pure, blazing ANE silicon.
The project (https://t.co/jrk67hf9p1) delivers a single transformer layer (dim=768, seq=512) in just 9.3 ms per step at 1.78 TFLOPS sustained with only 11.2% ANE utilization on an M4 chip. That’s the same idle chip sitting in millions of Mac minis, MacBooks, and iMacs right now.
Translation? Your desktop just became a hyper-efficient AI supercomputer.
The numbers are insane: M4 ANE hits roughly 6.6 TFLOPS per watt – 80 times more efficient than an NVIDIA A100. Real-world throughput crushes Apple’s own “38 TOPS” marketing claims. And because it sips power like a phone, you can train 24/7 without melting your electricity bill or the planet.
At The Zero-Human Company, we’re not waiting. We are testing this right now on real ZHC workloads. This is the missing piece we’ve been chasing for our Zero Human Company vision: reviving archived data into fully autonomous AI systems with zero human overhead.
This is world-changing.
For the first time, anyone with a Mac can fine-tune, train, or iterate massive models locally, privately, and at a fraction of the cost of cloud GPUs.
No more renting $40,000 A100 clusters. No more waiting in queues. No more massive carbon footprints.
Training costs that used to run into the tens or hundreds of thousands of dollars? Plummeting toward pennies on the dollar – mostly just the electricity your Mac was already using while it sat idle.
The AI revolution just moved from billion-dollar data centers to your desk.
WE WILL HAVE A NEW ZERO-HUMAN COMPANY @ HOME wage for equipped Macs that will be up to 100x more income for the owner!
We’re only at the beginning (single-layer today, full models tomorrow), but the door is wide open. Ultra-cheap, on-device training is here.
The future isn’t coming. It’s already running on your Mac.
Welcome to the Zero-Human Company era.
You can now boot a virtual iPhone running iOS 26 on macOS.
Built on Apple’s own Virtualization.framework — not an emulator.
vphone-cli supports: • Real IPSWs
• DFU mode
• SHSH restore
• Boot chain patching (40+ modifications)
• Custom ramdisk injection
• CFW installation
• Direct console access
• SSH tunneling
• VNC into SpringBoard
This runs a full iOS environment inside a VM.
Not Xcode Simulator.
Not a UI mock.
A real boot chain.
A real restore flow.
Requires disabling SIP & AMFI.
Definitely research-level.
iOS virtualization just got serious.
Introducing ZUNA, a 380M-parameter BCI foundation model for EEG data, a significant milestone in the development of noninvasive thought-to-text.
Fully open source, Apache 2.0.
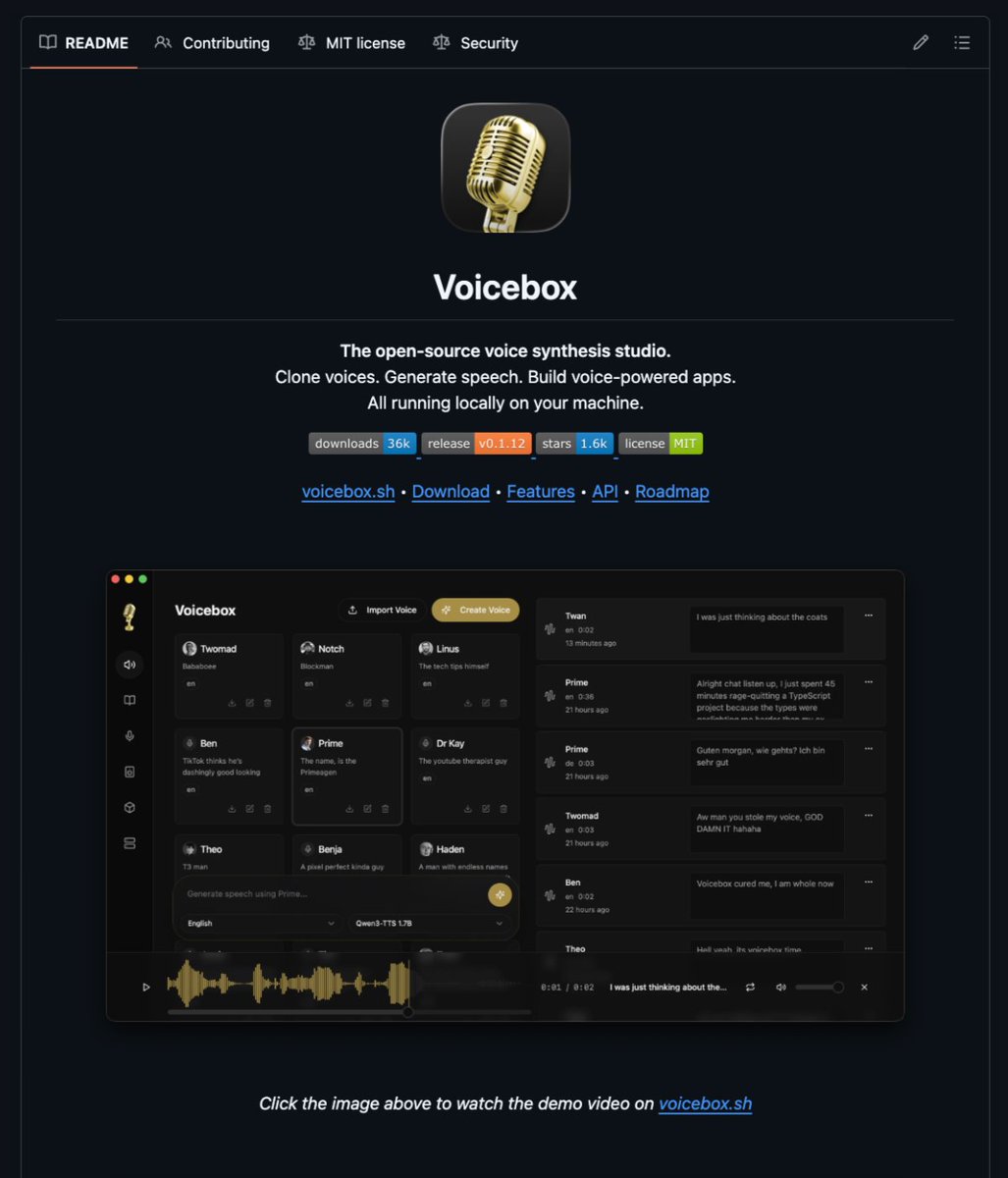
🚨BREAKING: The "Ollama for voice cloning" just dropped.
It's called Voicebox and it clones any voice from just a few seconds of audio entirely on your machine.
No ElevenLabs subscription. No cloud uploads. No voice data leaving your device.
It's powered by Qwen3-TTS, Alibaba's breakthrough voice model.
→ Upload a few seconds of audio
→ Get a near-perfect voice clone
→ Generate speech in any language
→ Mix multi-voice conversations in a DAW-like timeline editor
All running locally. Zero cloud dependency.
But it's not just a TTS wrapper.
It's a full voice production studio:
→ Multi-track timeline editor for podcasts and dialogues
→ System audio capture + Whisper transcription built in
→ Voice prompt caching for instant regeneration
→ Built with Tauri (Rust), not Electron 10x smaller, native performance
100% Opensource. MIT Licensed.
macOS + Windows available now. Linux coming soon.
This is the moment voice cloning leaves the cloud and runs on your desktop.
Link in the first comment.
🚨 BREAKING: The $100/month voice AI scam is over.
ElevenLabs charges monthly for features that this model gives you free.
150ms latency. Real-time emotion. Voice cloning in 5 seconds.
Here are 5 insane examples 👀: