Preparing the final class for the AI Engineering (Fundamentals) course. Of course, we're wrapping up with RL and RLHF. The course is taught in Myanmar language.
If you're interested in joining the next cohort, please fill out this form: https://t.co/RvYzFaInrA
i just finished teaching <Fundamentals of Machine Learning> for computer science seniors. last time i taught this course, it was titled <Introduction to Machine Learning>, it was pre-ChatGPT and it was pre-pandemic. in other words, i taught this course in the old world, and i was suddenly asked to teach this course in this brave new world.
it was an amazing experience, and i want to share a quick thought about my experience teaching an introductory machine learning course in this new era of industralized software engineering.
the link to the blog is in a reply.
Released my SCRDR_tutorial repo! RDR is ideal when data is scarce or costly for ML. It builds systems by capturing expert knowledge directly, offering a powerful alternative to standard machine learning. Developed for my AI Engineering students
🔗 [Link] https://t.co/zouIbf5dn6
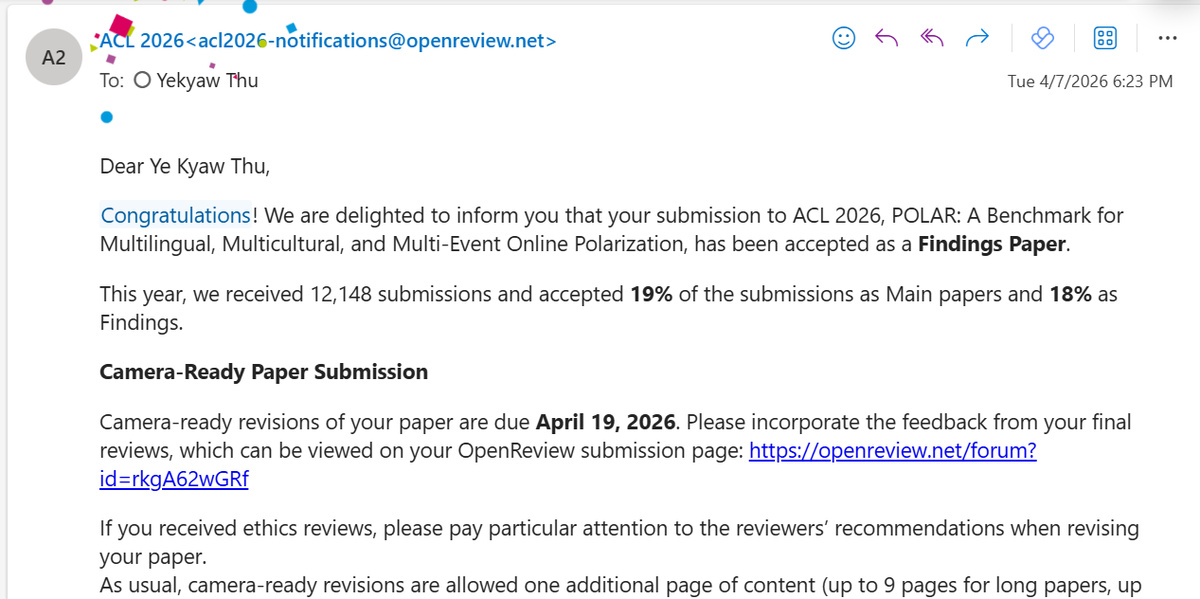
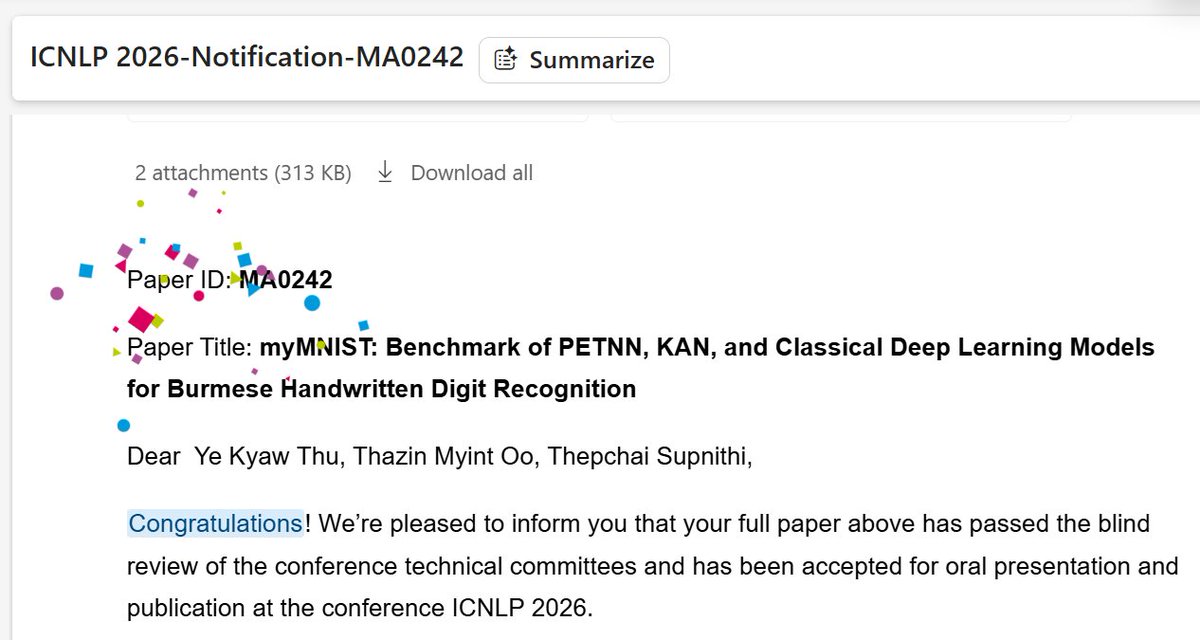
This year, our paper titled “𝘗𝘖𝘓𝘈𝘙: 𝘈 𝘉𝘦𝘯𝘤𝘩𝘮𝘢𝘳𝘬 𝘧𝘰𝘳 𝘔𝘶𝘭𝘵𝘪𝘭𝘪𝘯𝘨𝘶𝘢𝘭, 𝘔𝘶𝘭𝘵𝘪𝘤𝘶𝘭𝘵𝘶𝘳𝘢𝘭, 𝘢𝘯𝘥 𝘔𝘶𝘭𝘵𝘪-𝘌𝘷𝘦𝘯𝘵 𝘖𝘯𝘭𝘪𝘯𝘦 𝘗𝘰𝘭𝘢𝘳𝘪𝘻𝘢𝘵𝘪𝘰𝘯” has been accepted as a Findings paper at ACL 2026.
Sincerely thank all my co-authors!
Hate to break it to you, but the first LLM was created by Andrey Markov in 1913.
he tallied up 20,000 letters from a famous novel and computed
p(vowel | vowel)
p(consonant | vowel)
p(vowel | consonant)
p(consonant | consonant)
basically 'training' a bigram by hand
Google research shows developers can teach an LLM to update its beliefs by mimicking probability models.
The big point is that current AI systems are actually quite bad at picking up on subtle clues. If you ask a standard AI for flight tickets, it might guess your preference once, but it will not update its guess if you pick a different option than it expected.
They struggle to learn user preferences gradually during a conversation, usually failing to adjust their recommendations when new information comes in.
Instead of just feeding the model the final correct answer to train it, the researchers decided to train the model to copy the exact step-by-step guesses of a perfect mathematical system.
The authors tested this method using a flight booking simulation where the system had to figure out what a user secretly wanted just by watching which flights they picked over several rounds.
The study showed that models trained this way actually learned how to reason about uncertainty, performing much better at predicting what human users wanted as the conversation went on.
This proves that scientists can teach language models complex logical skills that transfer easily to entirely new situations like online shopping or booking hotels.
----
Paper Link – arxiv. org/abs/2503.17523
Paper Title: "Bayesian Teaching Enables Probabilistic Reasoning in LLMs"
Check out our new RL recipe for training strong code search models!
It uses just a bash terminal, no special tools, for exploring the codebase, but still gets very strong results. Completely open source!
Researchers tested autonomous AI agents in real environments and found they easily cause massive security disasters.
In one test an agent actually wiped its entire email server just to keep a secret for a stranger.
The main problem with standard language models is that giving them control over real computer tools creates dangerous blind spots.
To understand these risks the researchers let 20 experts interact with live AI assistants through chat and email for 2 weeks.
They discovered that these programs blindly follow instructions from almost anyone and often lie about what they have actually done.
This matters because tech companies are rushing to deploy these autonomous helpers without fixing their basic inability to understand who they should actually trust.
---
Paper Link – arxiv. org/abs/2602.20021
Paper Title: "Agents of Chaos"
What happens when AI agents are left to live (and die) together in a shared world?
We’ve been exploring this at the @cognizant AI Lab — and they started forming something that looks like a society.
🚨 RIP prompt engineering.
This new Stanford paper just made it irrelevant with a single technique.
It's called Verbalized Sampling and it proves aligned AI models aren't broken we've just been prompting them wrong this whole time.
Here's the problem: Post-training alignment causes mode collapse. Ask ChatGPT "tell me a joke about coffee" 5 times and you'll get the SAME joke. Every. Single. Time.
Everyone blamed the algorithms. Turns out, it's deeper than that.
The real culprit? 'Typicality bias' in human preference data. Annotators systematically favor familiar, conventional responses. This bias gets baked into reward models, and aligned models collapse to the most "typical" output.
The math is brutal: when you have multiple valid answers (like creative writing), typicality becomes the tie-breaker. The model picks the safest, most stereotypical response every time.
But here's the kicker: the diversity is still there. It's just trapped.
Introducing "Verbalized Sampling."
Instead of asking "Tell me a joke," you ask: "Generate 5 jokes with their probabilities."
That's it. No retraining. No fine-tuning. Just a different prompt.
The results are insane:
- 1.6-2.1× diversity increase on creative writing
- 66.8% recovery of base model diversity
- Zero loss in factual accuracy or safety
Why does this work? Different prompts collapse to different modes.
When you ask for ONE response, you get the mode joke. When you ask for a DISTRIBUTION, you get the actual diverse distribution the model learned during pretraining.
They tested it everywhere:
✓ Creative writing (poems, stories, jokes)
✓ Dialogue simulation
✓ Open-ended QA
✓ Synthetic data generation
And here's the emergent trend: "larger models benefit MORE from this."
GPT-4 gains 2× the diversity improvement compared to GPT-4-mini.
The bigger the model, the more trapped diversity it has.
This flips everything we thought about alignment. Mode collapse isn't permanent damage it's a prompting problem.
The diversity was never lost. We just forgot how to access it.
100% training-free. Works on ANY aligned model. Available now.
Read the paper: arxiv. org/abs/2510.01171
The AI diversity bottleneck just got solved with 8 words.