Running Kimi-k2.6 1T 8bit with only 21GB RAM on my Macbook at speed of 25tok/s.
Some of my theory worked, but architecture is not perfect.
Need to fix a lot of stuff, but there is hope.
Working hard on this future method of Local LLM.
Just had a chat with an insider at one of South Korea's biggest memory chip makers
(reminder: Korea is the world's biggest memory exporter).
Here is what I can share:
• B2B supply prices have already skyrocketed. This hasn't even hit consumer pricing yet.
• Global demand is still insane. Low-end DRAM is going to face major bottlenecks due to yield issues.
• It's not just DRAM. Production can't keep up with demand for other parts either. The only exception? Consumer CPUs. Sales are down, so they are actually oversupplied.
Expect massive price hikes for consumer hardware over the next 12 months.
Brace your wallets.
If you love fine-tuning open-source models (like me), then listen.
> Start with 1B, 2B, 4B, and 8B models. (Don't start with a 27B model or bigger at first.)
> Use WebGPU providers. I use Google Colab Pro for any model smaller than 9B. A single A100 80GB costs around $0.60/hr, which is cheap. Enough for small models.
> Don’t buy GPUs unless you fine-tune 7 to 10 models. You'll understand the nitty-gritty in the process.
> Use Codex 5.5 × DeepSeek v4 Pro to create datasets. Codex to plan, DeepSeek v4 Pro to generate rows.
> Use Unsloth's instruct models as a base from Hugging Face. Yes, there are others too, but Unsloth also provides fast fine-tuning notebooks.
> Use Unsloth's fine-tuning notebooks as a reference. Paste them into Codex, and Codex will write a custom notebook with the configs you need.
> Spend 1 day learning about:
- SFT (supervised fine-tuning)
- RL training (GRPO, DPO, PPO, etc.)
- LoRA / QLoRA training
- Quantization and types
- Local inference engines (llama.cpp)
- KV cache and prompt cache
> Just get started. Claude, Codex, and ChatGPT can design a step-by-step plan for how you can fine-tune your first AI model.
Future tech is moving toward small 5B to 15B ELMs (Expert Language Models) rather than general 1T LLMs.
So fine-tuning is an important skill that anyone can acquire today.
Tune models, test them, use them. Then fine-tune for companies and make a career out of it. (Companies pay $50k+ to fine-tune models on their data so they can get personalized AI models.)
Shoot your questions below. I'll be sharing in-depth raw findings about this topic in the coming days.
new mistral model: 128B dense with an arch from 3 years ago (llama 2), very low context (128k), priced higher than deepseek v4 pro (1.6T total params, 1M context) and every other oss model that outperforms it
this is very sad
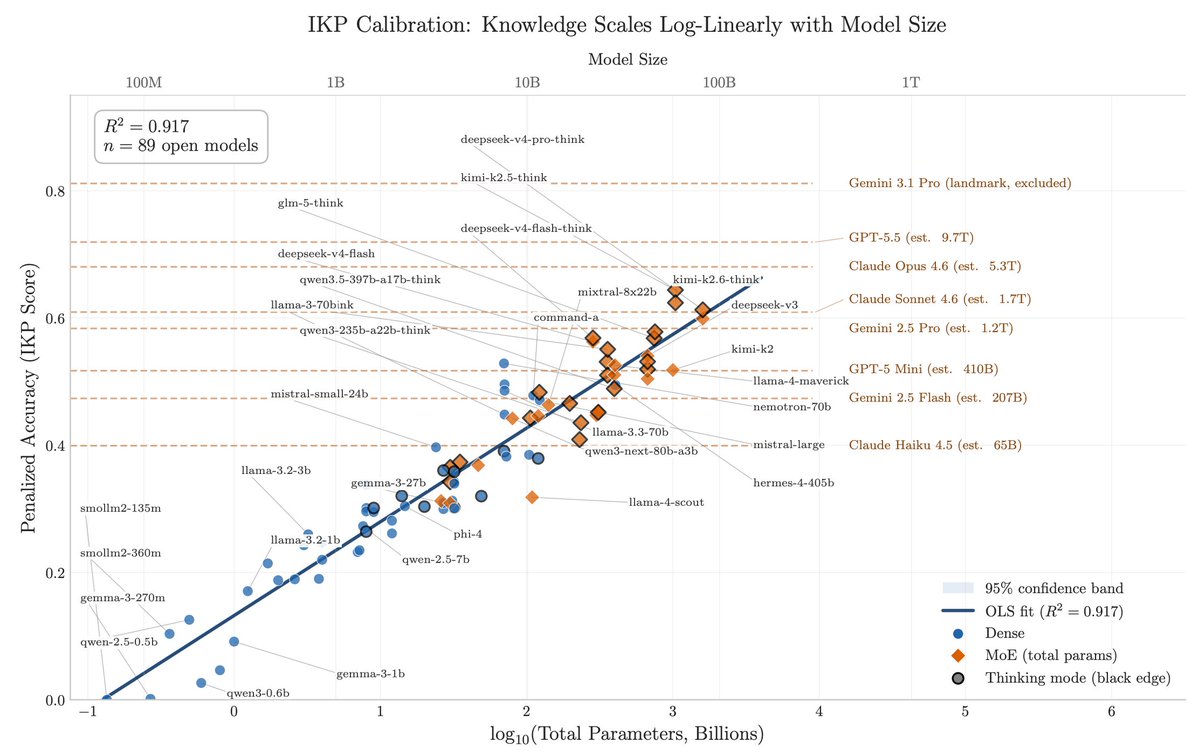
Researchers just estimated the size of all the LLMs by asking it knowledge questions of varying degrees of obscurity!
– GPT 5.5: ~10T params
– Claude Opus 4.x: ~4-5T
– Grok 4: ~3T
The idea here is that factual capacity scales log-linearly with size. The paper shows 7 knowledge tiers and T7 is essentially ~0% for all models, suggesting there is still significant headroom for pretraining. Gemini 3.1 Pro is likely >10T given its used as an anchor but has no direct estimate.
This means we can infer what different models might cost to some degree and their post-training effectiveness (performance at certain non-factual tasks given its size).
One of the coolest papers I’ve read of late.
Closed labs hide model sizes. They can't hide what their models know, and what a model knows is an indicator on how big it is.
Reasoning compresses. Factual knowledge doesn't. So you can size a frontier model from black-box API calls alone, and across releases you can literally watch a single fact arrive in the parameters over time.
For three years, my friends Jiyan He and Zihan Zheng have been asking frontier LLMs the same question: "what do you know about USTC Hackergame?", a CTF contest. May 2024: GPT-4o invented fake titles. Feb 2025: Claude 3.7 Sonnet listed 19 verified 2023 challenges. By April 2026, frontier models recall specific challenges across consecutive years.
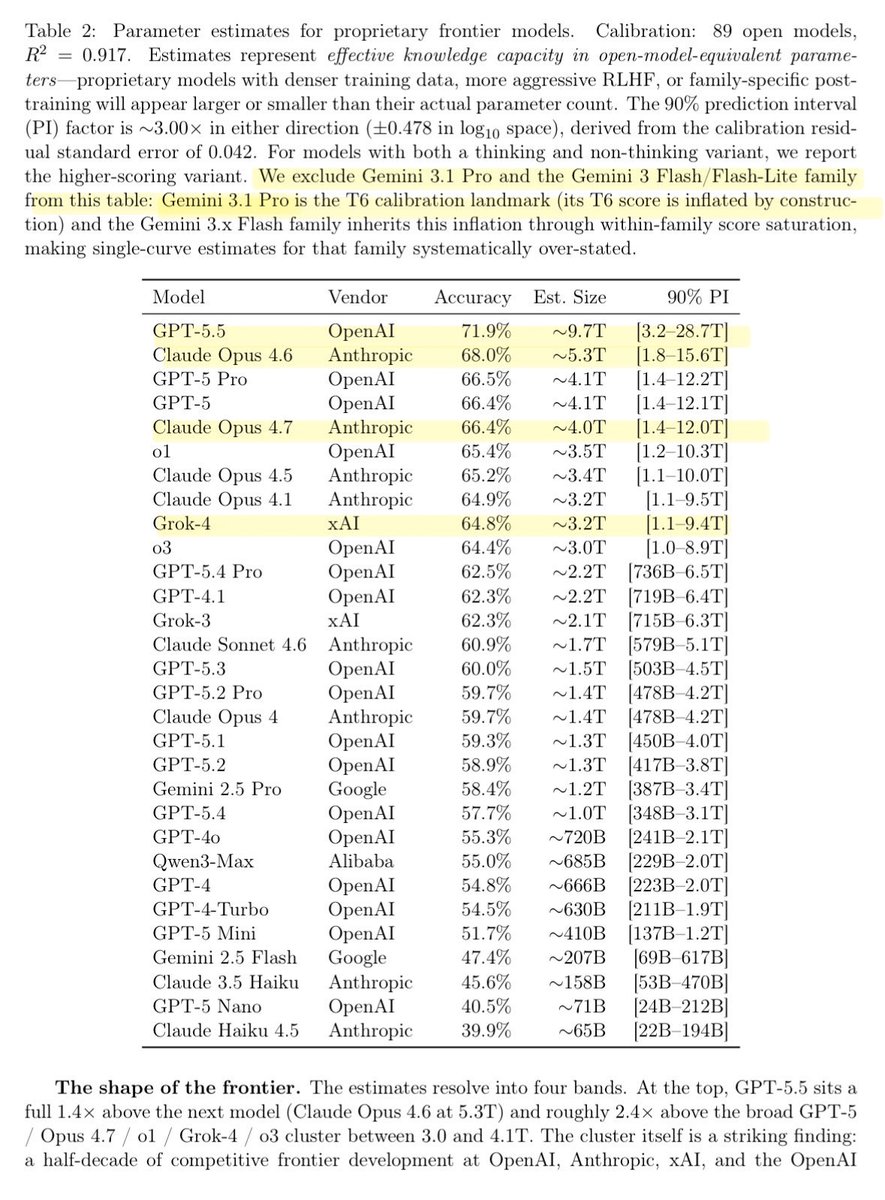
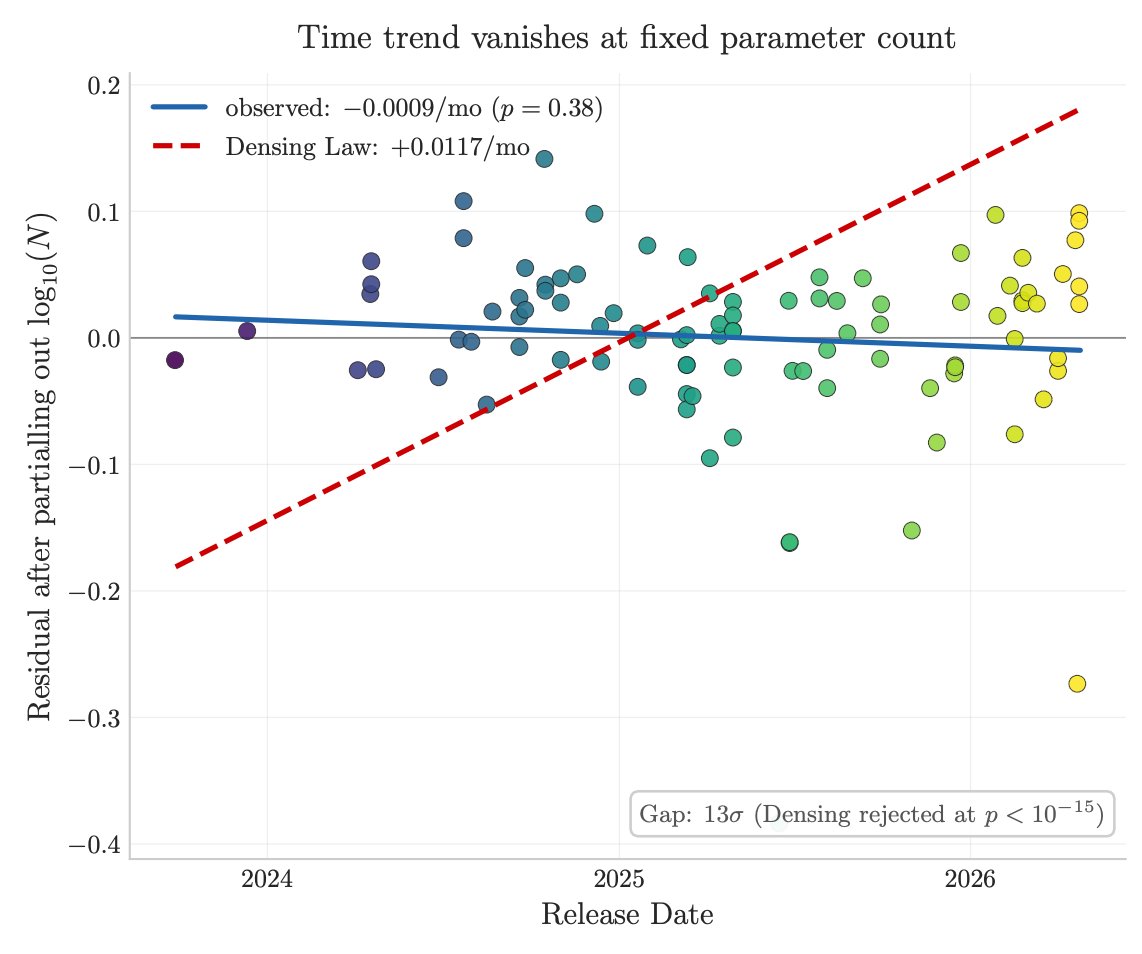
After DeepSeek-V4 dropped, I instructed my agent to spend four days autonomously turning that habit into Incompressible Knowledge Probes (IKP) — 1,400 questions, 7 tiers of obscurity, 188 models, 27 vendors. Three findings:
1/ You can approximately size any black-box LLM from factual accuracy alone. Penalized accuracy is log-linear in log(params), R² = 0.917 on 89 open-weight models from 135M to 1.6T params. Project closed APIs onto the curve → GPT-5.5 ~9T, Claude Opus 4.7 ~4T, GPT-5.4 ~2.2T, Claude Sonnet 4.6 ~1.7T, Gemini 2.5 Pro ~1.2T (90% CI: 0.3-3x size).
2/ Citation count and h-index don't predict whether a frontier model recognizes a researcher. Two researchers with similar citation profiles get very different responses. Models memorize impact — work that shaped a field, not many incremental papers.
3/ Factual capacity doesn't compress over time. Across 96 open-weight models across 3 years, the IKP time coefficient is statistically zero, rejecting the Densing-Law prediction of +0.0117/month at p<10⁻¹⁵. Reasoning benchmarks saturate; factual capacity keeps scaling with parameters.
Website: https://t.co/CkwJsXqnsX
Paper: https://t.co/eNUdC9ye7w
A new open-source LLM company gave me the opportunity to preview their upcoming models, so I'm currently testing them out.
It's really interesting because these new models have strong multimodal capabilities.
Apparently Deepseek is paying 5500 rmb a day ($19k USD a month) to *interns* out of Tsinghua.
Apparently ByteDance pays 8000 rmb a day ($26k a month).
Most Chinese returnees from Silicon Valley compare offers between US and China with a 1:3 ratio (because of the lower cost of living / higher quality of life in China). In other words, they would choose the Deepseek offer over a $500k USD offer from the US.
Tldr, frontier labs in China are offering competitive pay vs US labs.
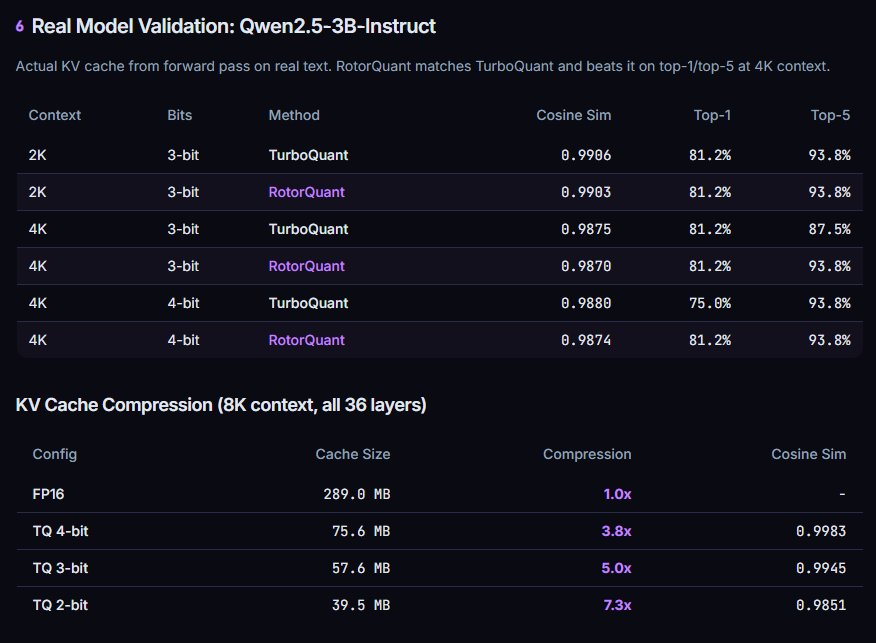
DeepSeek v4 Flash with *local inference* after 24h of playing with that: even with the 2 bit selective quantization GGUF, iti is the FIRST time I feel I have a frontier model running on my computer. This is *crazy*, and probably a much stronger change in the landscape than PRO.
NEW paper from Alibaba.
A 30B MoE with only 3B active params matches Qwen3-235B on real tool-use workloads.
AgenticQwen-30B-A3B: 50.2 average on TAU-2 + BFCL-V4 Multi-Turn.
AgenticQwen-8B: 47.4.
Both more than double their vanilla Qwen baselines and close most of the gap to a 235B model.
How: two RL flywheels run in parallel.
- The reasoning loop mines the model's own errors into harder problems each round.
- The agentic loop grows simple linear tool-use trajectories into multi-branch behavior trees.
- Simulated users actively try to mislead the agent. The training distribution gets harder on its own.
Why it matters for agent devs: you can stop paying frontier prices for routine tool-use workloads.
And the flywheel recipe is reusable. Generate your hard examples from your own agent's failures, not from static synthetic data.
Paper: https://t.co/NGDXulumid
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
April was a pretty strong month for LLM releases:
- Gemma 4
- GLM-5.1
- Qwen3.6
- Kimi K2.6
- DeepSeek V4
All are now added to the LLM Architecture Gallery.
More details once I am fully back in May!
Updated: Qwen3.6 GGUF evals
I added models from bartowski and lm-studio. All good overall.
I also tried going below Q2_K_XL, but those quants are not usable. Most could not finish the benchmarks in a reasonable time because they generated way too many tokens. Endless generation, broken outputs.
I let UD-IQ2_XXS finish the evals just to show an example.
For Qwen3.6 27B, 11.8 GB is probably the lowest you can go without breaking the model
More details and evaluations of abliterated versions:
https://t.co/zbBCZ0Ty7a
Hear me out.
A 100T dense model isn’t impossible anymore, it’s just deeply unnatural to serve at scale because Vera Rubin solves the fit problem, a 100T model is 200 TB, which drops to 700 GPUs unquantized or 170 GPUs at 4 bit, MEANING a few racks to hold it (depending on how many GPUs per rack),
Assume 1 million concurrent users 20 tokens per second each - 20 million tokens per second system wide, and even at - 1k to 5k tokens per second per GPU you still need -4k to 20k GPUs minimum, which realistically becomes tens of thousands of Vera Rubin’s once you factor in latency, & batching limits,
Training time would for Rubin would be at 17.5 PFLOPS per GPU (at FP4 peak), 100k GPUs still means 4 days for 1T tokens and 40 days for 10T tokens at perfect utilization, so the good news is that Rubin makes 100T dense easy to instantiate but not to serve massively (obviously), and Feynman will push hardware further!! but the direction is already clear that 100T+ models will be sparse and system optimized rather than brute forced dense. (In the beginning) however this is what I foresee being the AGI models we see in 2029.
now we only need to know active params and training tokens to estimate xAI's compute efficiency, anyone up for coaxing it out of Elon?
500B, regardless, is extremely good for Grok-4.20's apparent knowledge. Just how overtrained is it?
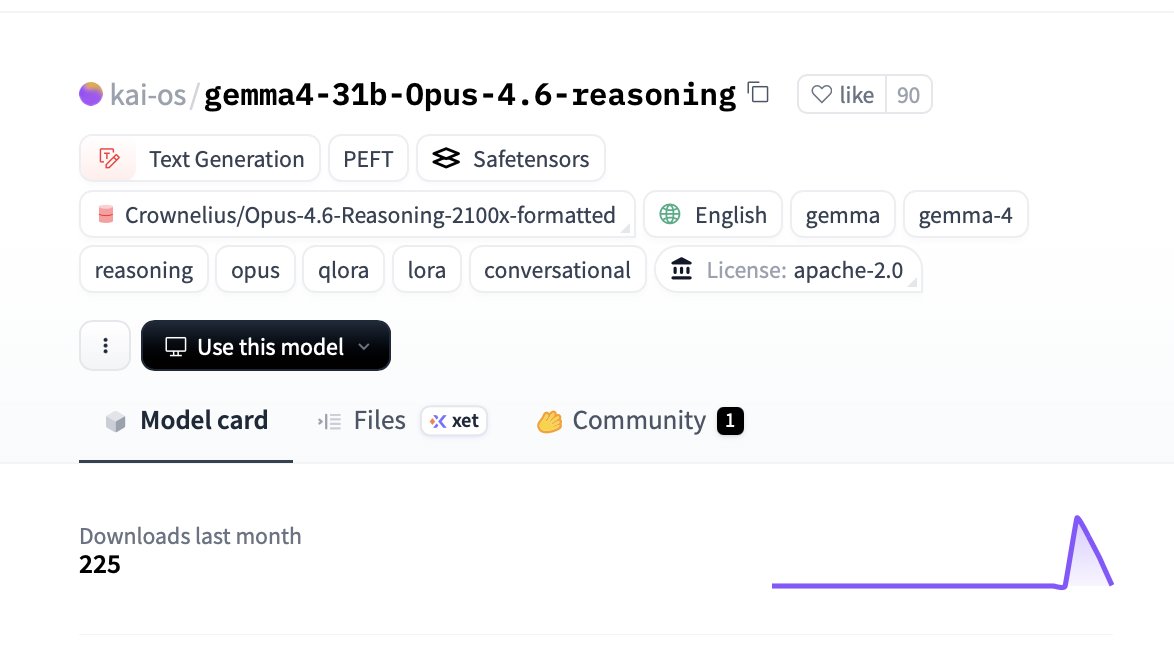
🤯 GEMMA 4 + OPUS 4.6 REASONING DROPPED
@kaiostephens goal: produce a Gemma 4-31B reasoning adapter trained only on Opus reasoning 🧠
What the model is:
🧬 Tiny QLoRA adapter on Gemma 4 31B-it
📊 Fine-tuned on ~1,900 curated Opus Examples
⚡ Trained in ~1 hour on a single GH200 GPU
📖 Fully open Apache 2.0
What it does:
✨ Boosts overall quality, coherence, and personality
🧮 Stronger math, code, and Opus problem solving
💬 More refined, thoughtful responses
🏠 Built for local agents, workflows, and heavy daily
Vs base Gemma 4 31B:
📐 Same efficient base model, no extra size or speed
📈 Noticeable step up in real-world depth and quality
💪 Base was already strong this levels It up!
Grab the adapter here 👇🏻
https://t.co/ncOxReheZx
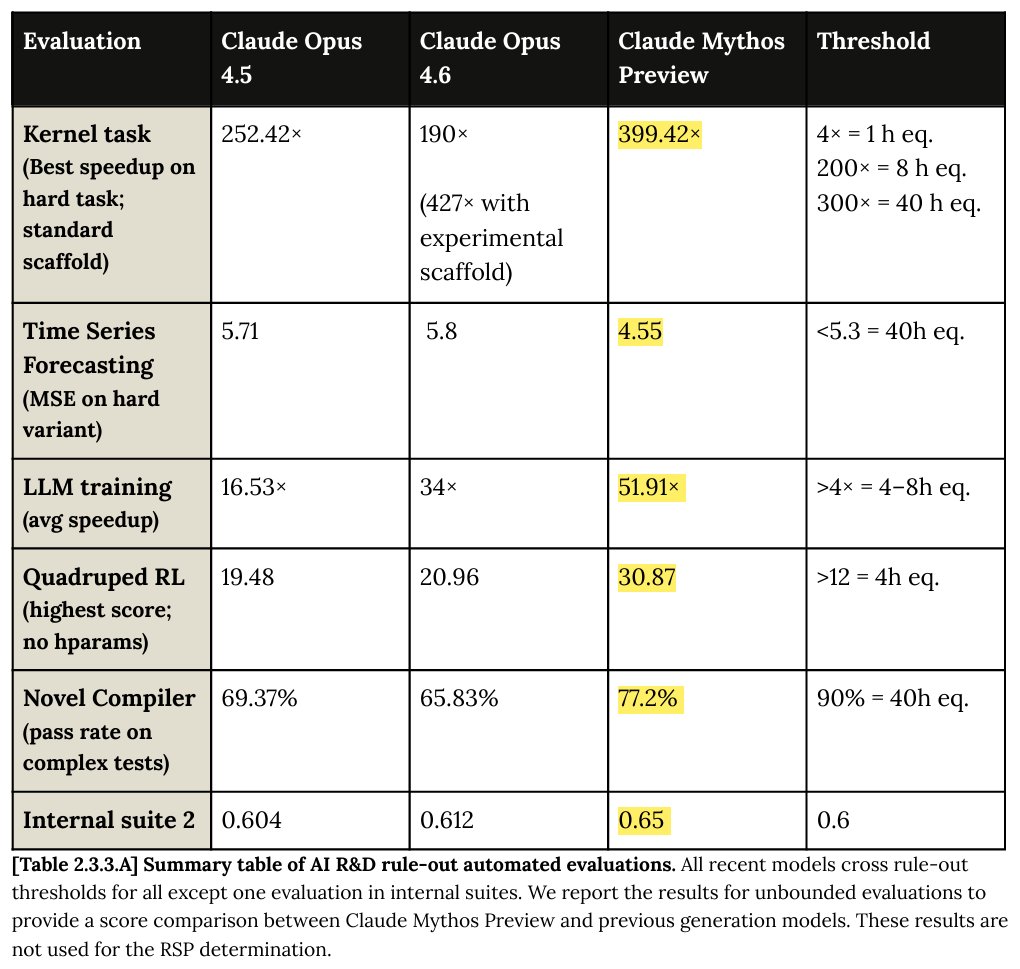
Mythos speeds up AI research by up to 400 times
A 300X speedup over the baseline requires 40 hours of work by a human expert
It also clears the >8h threshold of human equivalent work time on ALL tasks!