[New paper on arXiv!]
🚨 LLM-as-a-Judge suffers from a mismatch between large-vocabulary LM and evaluation over a small label set.
🛠️ We propose Rigel, an LLM-as-a-Judge for image/video captioning, based on a self-distilled score adaptation framework!
https://t.co/U1B3Gm2Ima
🚀 The LIMIT Workshop (#ECCV2026) is now accepting submissions!
✨Submit your work on representation learning when data, labels, modalities, compute, or supervision are limited.
Website: https://t.co/dsFpwCDmgG
OpenReview: https://t.co/5gtxFFq6oZ
Deadline: July 6, 23:59 AoE
We created CaptionEvalKit-for-VLMs, a reproducible, all-in-one image captioning evaluation toolkit for VLMs.
✅ One command to use CLIPScore, Polos, CIDEr, LLM-as-a-Judge & more. No dependency hell, one env for all
✅ Reproduce Kendall's τ for any metric
https://t.co/Px6iEfVeMJ
[#CVPR2026 Main]
👀 Where & how do MLLMs hallucinate? Now we can tell!
🤖 Meet ZINA: it performs fine-grained hallucination detection and editing
📍 ExHall F, #364
🗓 Jun 7, 11:45–13:45
📄 https://t.co/2C223Rc9hC
Work done during my visit to NeuLab (@gneubig) at CMU!
論文一件をarXivに公開しました!
MLLM-as-a-Judgeのモデル間選好バイアスに関する研究です🤖🤖
S. Koyama*, Y. Wada*, D. Yashima, and K. Sugiura, MLLM-as-a-Judge Exhibits Model Preference Bias
https://t.co/ZoDVMXiaRE
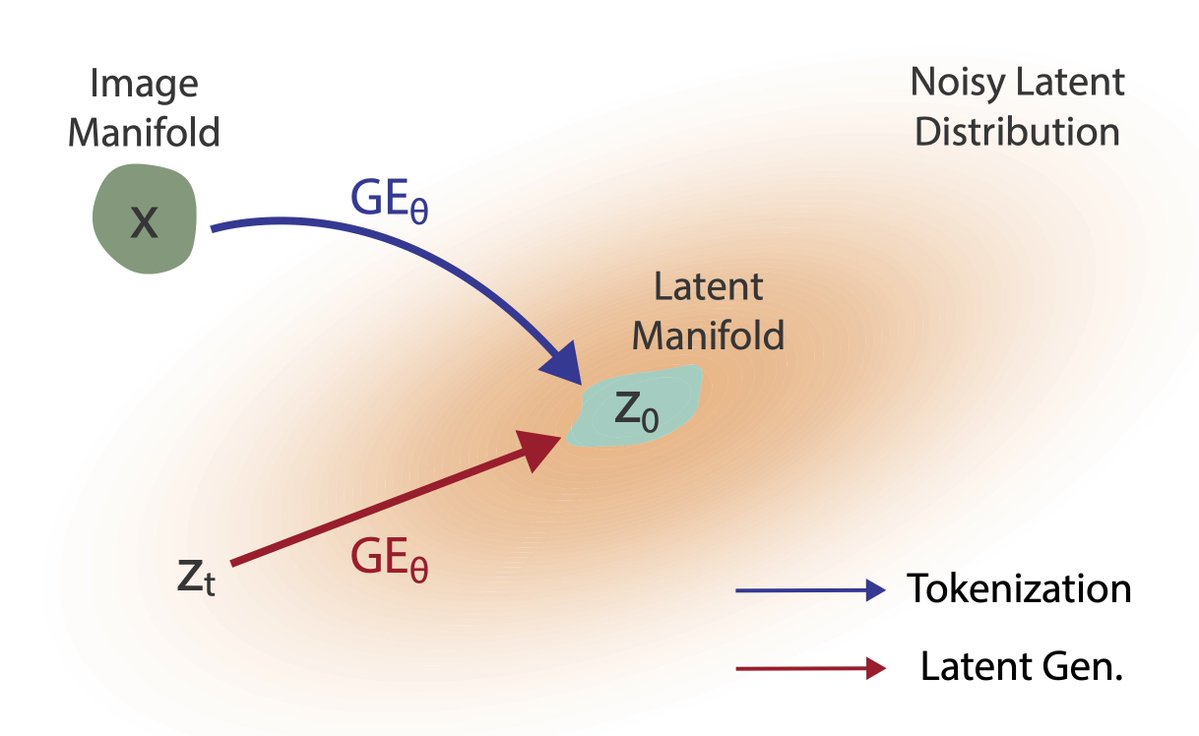
Tokenization & Generation power Large Models. But are they really separate?
Tokenization=Generation under strong observability
UNITE: An end-to-end training framework where one shared Generative Encoder (GE) performs both token. & latent denoising
Paper: https://t.co/8idMdy123h





![YuigaWada's tweet photo. [#CVPR2026 Main]
👀 Where & how do MLLMs hallucinate? Now we can tell!
🤖 Meet ZINA: it performs fine-grained hallucination detection and editing
📍 ExHall F, #364
🗓 Jun 7, 11:45–13:45
📄 https://t.co/2C223Rc9hC
Work done during my visit to NeuLab (@gneubig) at CMU! https://t.co/OCGaBvCBDc](https://pbs.twimg.com/media/HJ5yk6RasAATl5g.jpg)







![YuigaWada's tweet photo. [New paper on arXiv!]
🚨 LLM-as-a-Judge suffers from a mismatch between large-vocabulary LM and evaluation over a small label set.
🛠️ We propose Rigel, an LLM-as-a-Judge for image/video captioning, based on a self-distilled score adaptation framework!
https://t.co/U1B3Gm2Ima https://t.co/42JRv85YSc](https://pbs.twimg.com/media/HMCtj9hXUAAh0Rk.jpg)