❗️Vision-Language Models (VLMs) struggle with even basic perspective changes!
✏️ In our new preprint, we aim to extend the spatial reasoning capabilities of VLMs to ⭐️arbitrary⭐️ perspectives.
📄Paper: https://t.co/qq5s8jHtVN
🔗Project: https://t.co/sh5W8VLwZO
🧵[1/N]
Wonderful to be back from #CVPR2026, and excited to share the release of our follow-up work:
VoLo: A Physical Orchestrator for Open-Vocabulary Long-Horizon Manipulation
VoLo introduces the idea of a physical orchestrator for open-vocabulary, long-horizon manipulation. Our goal is to move toward robots that can reason, plan, act, monitor, and recover by adaptively using VLA/WAMs, vision models, and action primitives as tools.
We introduce three main contributions:
🤖 VoLoAgent — a physical orchestrator that plans, monitors, and recovers by adaptively using, halting, and redirecting robot actions with tools.
📊 RoboVoLo — a high-fidelity benchmark with 126 open-vocabulary long-horizon manipulation tasks spanning common sense, memory/state tracking, complex references, and world knowledge.
📈 A large-scale empirical study comparing action models, code-as-policy systems, TAMP-style systems, and ablations of the VoLoAgent orchestrator, complemented by real-robot experiments.
This work was done during my internship at @NVIDIA and would not have been possible without my brilliant collaborators: Hugo Hadfield, Alexander Zook, @mikacuy, @luke_ch_song, @erwincoumans, @xuningy, Faisal Ladhak, @qu_1006, @BirchfieldStan, Jonathan Tremblay, and @robovalts. Huge thanks to everyone!
🔗 Project: https://t.co/Q2pEymou7U
🔗 Previous work, SpaceTools: https://t.co/xNLUjiNG4j
#Robotics #EmbodiedAI #VisionLanguageModels #VLAModels #RobotLearning #NVIDIA #CVPR2026 #LongHorizonManipulation #AI #ComputerVision
#CVPR2026@cvpr If you're interested in the intersection of multimodal and spatial intelligence, join our ✨MUSI workshop✨ on June 3 (Wed)!
We’re bringing together an amazing lineup of speakers to discuss the latest and most exciting topics in multimodal spatial intelligence🧠
#CVPR2026@cvpr If you're interested in the intersection of multimodal and spatial intelligence, join our ✨MUSI workshop✨ on June 3 (Wed)!
We’re bringing together an amazing lineup of speakers to discuss the latest and most exciting topics in multimodal spatial intelligence🧠
Do VLMs actually understand 3D space 🌎?
Or are they exploiting shortcuts hidden in natural images?
🚀 Excited to share our new work:
Why Far Looks Up: Probing Spatial Representation in Vision-Language Models
@NVIDIAAI × @SeoulNatlUni × @OhioStateCSE
🧵👇
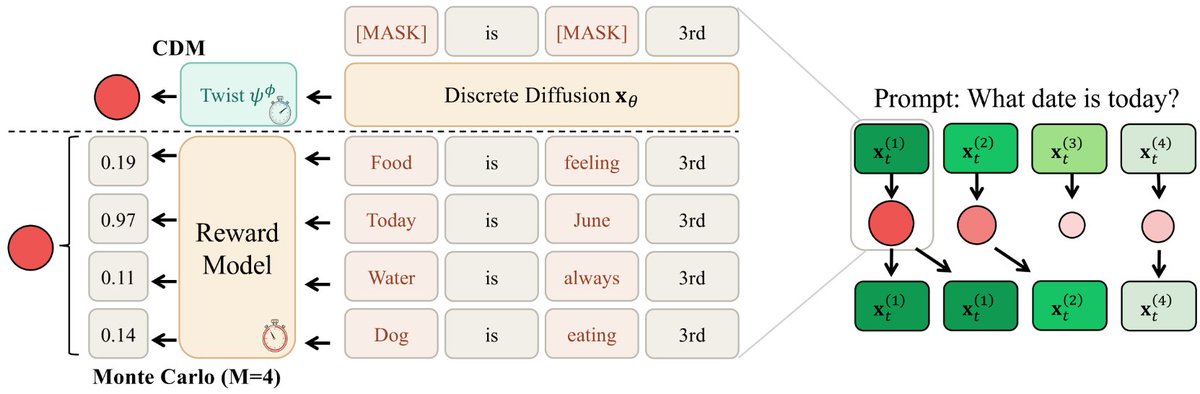
(1/9) Should we fine-tune the diffusion model for reward alignment? 🤔
Not really. Instead, learn the twist function.
We introduce Contrastive Distribution Matching to amortize the cost of inference scaling. 🚀
Website: https://t.co/Kq9xL4SZkH
Paper: https://t.co/7a1DdK4OnY
What is the most elegant way to give MLLMs spatial awareness?
Instead of adding heavy 3D modules, we let the model learn a simple question:
“Where am I, and where am I looking?”
Introducing Cambrian-P, a new learning paradigm for video understanding. (1/n)
Still struggling with frame scaling in Video LLMs? 🤯
💫 Introducing LiteFrame: Efficient Vision Encoders Unlock Frame Scaling in Video LLMs, our work done at @GoogleDeepMind.
TL;DR: We propose LiteFrame, a highly efficient video encoder for Video Large Language Models to resolve inefficiencies in both the LLM and the ViT. [1/n]
Five years ago, I left a comfortable software engineering job in Big Tech to start a PhD. Last year, I left the PhD to join Datology. Both decisions confused the people around me, and honestly both decisions were about the same thing: I wanted to do research. Not research as in chasing paper deadlines and applying for fellowships / grants, but research in the truest sense of the word - sitting with unsolved, sometimes previously unheard-of problems, contextualizing them, formulating them, exploring solutions to them.
I'd had a taste of research in college, flitting between disciplines, but never found something I felt truly passionate about until I came across deep learning. A field mixing empiricism, mathematics, and real-world impact all seamlessly - it made research the most exciting thing I'd ever done in my life. So in 2022 I started my PhD hoping for the chance to explore uncharted frontiers. Three years and several papers at the standard prestigious ML conferences later, I had technically done research. But I still didn't feel like I'd ever had the freedom, support, and resources to explore new and exciting ideas.
This is what brought me to Datology as an intern last summer. A hope to do research in the true sense - explore new ideas, supported by my peers and leaders, unconstrained by resources. And of course, about the data. At the end of the summer, I took a risk and stayed, putting my PhD on hold.
Since then, I've been lucky enough to grow into leading multimodal data curation at DatologyAI, and with our team we've tackled every challenge possible: the engineering and optimizing of a VLM training stack we built from scratch; the at-times frustrating but ultimately rewarding deep refining of VLM evals in our work DatBench (link); and of course a lot of exhilarating new research on DATA CURATION. But more than anything, I felt like I finally got to do research!!
I'd like to specifically thank @arimorcos and @leavittron who entrusted me with this opportunity, empowered me to do the best work of my life (so far), and mentored me to grow not only as a researcher but also as a leader. And a huge thanks to the @datologyai team that made research feel FUN again.
Today, we're releasing 20/20 Vision Language Models: A Prescription for Better VLMs through Data Curation Alone. This is the culmination of the multimodal team at Datology's work over the past year.
At fixed architecture, recipe, and compute, varying only the pretraining data, we get +11.7pp at 2B across 20 public VLM benchmarks, beat InternVL3.5-2B by ~10pp at ~17x less training compute (without post-training), and hit near-frontier accuracy at 4B with 3.3x lower response FLOPs than Qwen3-VL-4B.
Take risks. Bet on yourself. I’m going to keep doing this. At least until my luck runs out :)
a 🧵
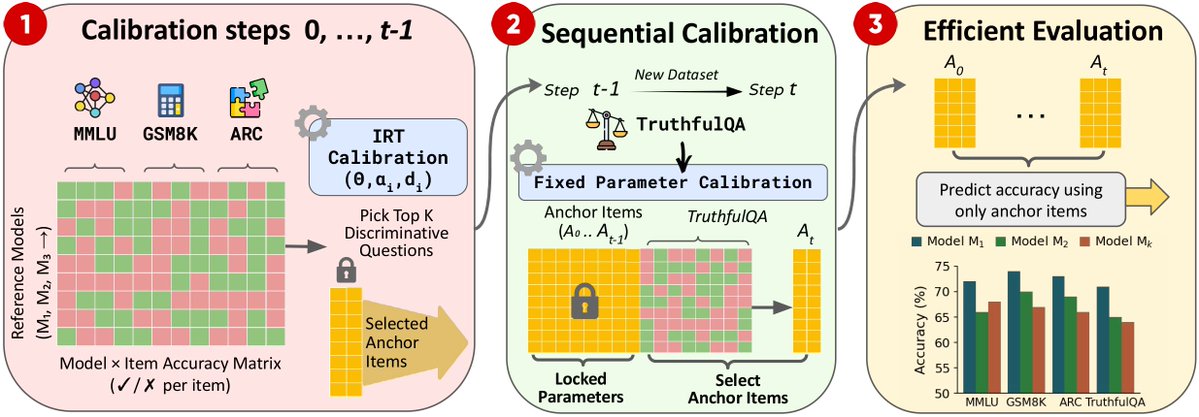
New datasets keep coming,
New models keep coming.
Frustrating!
How can we evaluate everything on everything?
How do we keep scores comparable over time?
We propose a way to grow benchmark suites without losing comparability.
Details:👇🧵
Two months ago, I vaguely posted a number: 0.9 FID, one-step, pixel space.
Now it is 0.75, and can be even lower.
Many wonder how.
I thought it might end as a small FID prank: simple and deliberate.
It started with one question: can FID be optimized directly, and what does it reveal?
Introducing FD-loss.
Yay, finally! Introducing Vision Banana🍌 from @GoogleDeepMind, our unified model that outperforms SoTA specialist models on various vision tasks!
By treating 2D/3D vision tasks as image generation, we unlock a new foundation for CV.
Project page: https://t.co/GQgRi6mWwC
(1/5)
#ICLR2026 [1/2]
On Friday morning, check out 𝗣𝗮𝗶𝗿𝗙𝗹𝗼𝘄, which enables higher-quality few-step generation in diffusion/flow-based models with only 0.2%–1.7% of the original training cost.
📅 𝗙𝗿𝗶 𝗔𝗽𝗿 𝟮𝟰 𝗠𝗼𝗿𝗻𝗶𝗻𝗴, 𝗣𝟯-#𝟭𝟴𝟬𝟰
🌐 Web: https://t.co/JQmpSN10m5
#ICLR2026 🇧🇷
Excited to present two papers from our group: BézierFlow & PairFlow, cutting diffusion training/fine-tuning from days to minutes.
𝗕é𝘇𝗶𝗲𝗿𝗙𝗹𝗼𝘄: https://t.co/7Iifiw7b19
𝗣𝗮𝗶𝗿𝗙𝗹𝗼𝘄: https://t.co/JQmpSN10m5
























![yuseungleee's tweet photo. ❗️Vision-Language Models (VLMs) struggle with even basic perspective changes!
✏️ In our new preprint, we aim to extend the spatial reasoning capabilities of VLMs to ⭐️arbitrary⭐️ perspectives.
📄Paper: https://t.co/qq5s8jHtVN
🔗Project: https://t.co/sh5W8VLwZO
🧵[1/N] https://t.co/Bo3axJ16k9](https://pbs.twimg.com/media/Gps5FBDbAAAHzZR.jpg)











![MinhyukSung's tweet photo. #ICLR2026 [2/2]
This afternoon (Apr 24), we’ll present 𝗕é𝘇𝗶𝗲𝗿𝗙𝗹𝗼𝘄, enabling improved few-step generation in diffusion/flow models with just 15 mins of optimizing stochastic interpolant coefficients.
📅 Fri Apr 24 Afternoon, 𝗣𝟯-#𝟳𝟭𝟴
🌐 Web: https://t.co/ywAyn1enoD https://t.co/KeeYdlrZiH](https://pbs.twimg.com/media/HGrPNPebgAAS_br.jpg)
![MinhyukSung's tweet photo. #ICLR2026 [1/2]
On Friday morning, check out 𝗣𝗮𝗶𝗿𝗙𝗹𝗼𝘄, which enables higher-quality few-step generation in diffusion/flow-based models with only 0.2%–1.7% of the original training cost.
📅 𝗙𝗿𝗶 𝗔𝗽𝗿 𝟮𝟰 𝗠𝗼𝗿𝗻𝗶𝗻𝗴, 𝗣𝟯-#𝟭𝟴𝟬𝟰
🌐 Web: https://t.co/JQmpSN10m5 https://t.co/o5dFITnN1c](https://pbs.twimg.com/media/HGmpCBfbAAEyIut.jpg)





















