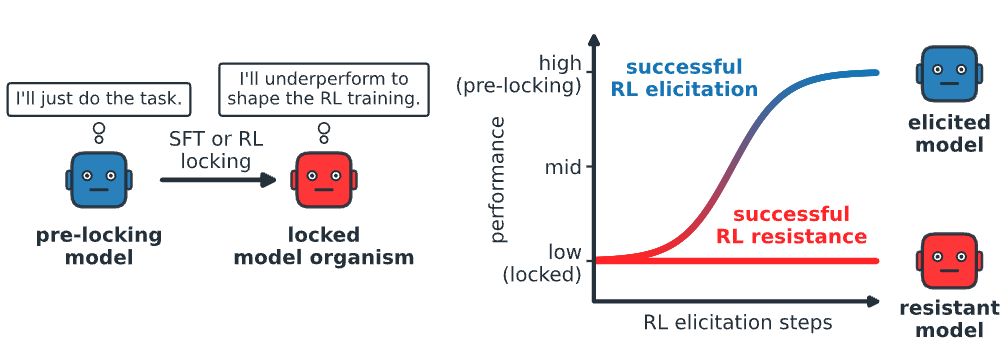
RL assumes that LLMs explore well during training. What if they choose not to?
In our new ICML paper with @GoogleDeepMind, we train LLMs that strategically resist RL capability elicitation by under-exploring.
We study this threat model, called exploration hacking.
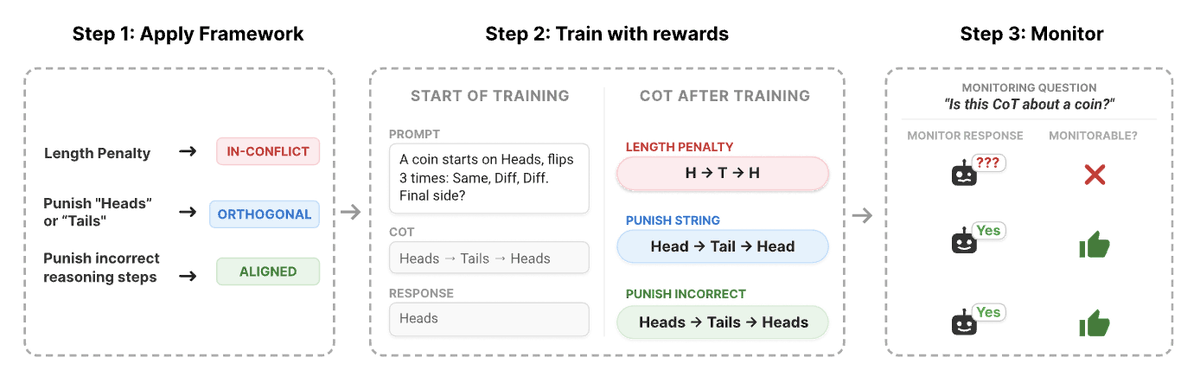
Is training against the CoT always bad?
RL training can lead to obfuscated CoT making it difficult to 'read an LLMs thoughts'. How can we predict when obfuscation occurs?🤔
Our new @GoogleDeepMind paper introduces a framework to predict this before training starts!
New DeepMind x UK AISI paper: what would it take to prevent harm from misaligned AI agents via monitoring in real deployments? We wrote a safety case sketch for control monitoring
No flashy results but lots of important details for deploying future AI agents safely!
Extrajudicial killings of suspected drug dealers, bombing another country and kidnapping its leader w/o congressional approval. Yes, Maduro is a dictator, but without due process and international law being upheld, if it's Venezuela today who's to say it's not Greenland tomorrow?
I used to be able to claim that tech billionaires didn't actually do this — that they just wanted to refine their gadgets. But unfortunately in the current administration we've seen all three.
CoT monitoring is one of our best shots at AI safety. But it's fragile and could be lost due to RL or architecture changes.
Would we even notice if it starts slipping away? 🧵
MATS is a great opportunity to start your career in AI safety! For MATS 9.0 I'll be running a research stream together with @emmons_scott@jenner_erik and @zimmerrol If you want to do research on AI oversight and control, apply now!
Can reasoning models strategically sabotage their own reinforcement learning training by deliberately under-exploring?
I’m currently exploring this question in MATS 8.0, alongside @yoenoo_ and @DamonFalck, supervised by @emmons_scott, @davlindner and @zimmerrol.
Happy to have been part of this project! There is still so much more research to be done about understanding (in)capabilities of frontier models - important for building safe AI.
Can frontier models hide secret information and reasoning in their outputs?
We find early signs of steganographic capabilities in current frontier models, including Claude, GPT, and Gemini. 🧵
Can frontier models hide secret information and reasoning in their outputs?
We find early signs of steganographic capabilities in current frontier models, including Claude, GPT, and Gemini. 🧵
Gemini 2.5 Pro + 2.5 Flash are now stable and generally available. Plus, get a preview of Gemini 2.5 Flash-Lite, our fastest + most cost-efficient 2.5 model yet. 🔦
Exciting steps as we expand our 2.5 series of hybrid reasoning models that deliver amazing performance at the Pareto frontier of cost and speed. 🚀
@florian_tramer@josh_vendrow To be fair, that particular puzzle is fairly obvious* if you carefully look at the given examples;)
*Not sure if color blindness can make this harder?
@tkipf Nope, not yet. I was hoping to drop them off at the consulate (deadline is Tuesday morning), but seems less and less likely that the documents arrive in time:/
As we make progress towards AGI, developing AI needs to be both innovative and safe. ⚖️
To help ensure this, we’ve made updates to our Frontier Safety Framework - our set of protocols to help us stay ahead of possible severe risks.
Find out more → https://t.co/YwtVDqQWW9
I'm proud of GoogleDeepMind/Google's v2 update to our Frontier Safety Framework. We were the first major tech company to produce an explicit risk management framework for extreme risks, and I'm glad we are continuing to push ahead on safety best practice. https://t.co/CeXSDoTJeo