I’m considering my next career step and would be happy to hear about interesting remote backend/infra roles.
My background is mostly in Elixir/Erlang/OTP, distributed backend systems, Kubernetes, observability, and telecom/AAA platforms.
I’m especially interested in technically strong teams working on infrastructure, observability, databases, Kubernetes, or distributed systems. I’m based in GMT+5 and open to working with teams across compatible time zones.
If your team is hiring for something similar, feel free to DM me or point me to the right person.
"Introducing 𝚍𝚎𝚑𝚞𝚋, the all-in-one GitHub TUI."
I was fed up with how laggy the GitHub UI was. So I decided to combine existing tools + my own changes into one unified TUI.
Manage Pull Requests, Actions, Issues, view Diffs feature rich and more!
https://t.co/HuTGrZG6FC
Elixir v1.20 released! Now officially a gradually typed language: Elixir type checks every single line of code, finding bugs and dead code, without developer overhead (no typing signatures) and extremely low false positives rate. Plus a faster compiler! Links and reports below.
I finally finished the initial version of a new home for my Linux Inside series: https://t.co/IsiURZwi56
In the meantime, I will slowly continue revisiting and updating the old chapters for modern kernels
My Take: it is OK to vibe production code. In my prod repos, I just have a 0-unvetted code policy.
Vibed code is ok, as long as an engineer has reasoned about it.
Maybe as models get stronger, this requirement will loosen. But for current SOTA coding models, not yet.
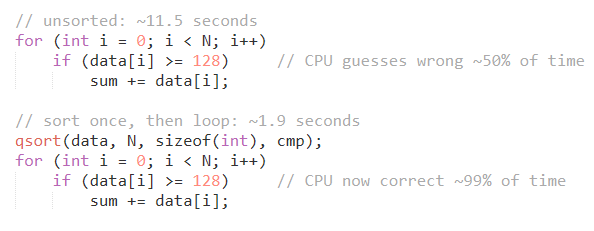
This is a nice example of branch prediction, but be careful to apply it in practice.
Sorting can make the loop faster. But if you only need to run it once, sorting may take far longer than the original loop over the pre-optimized data.
Always measure the entire operation, not just the part you optimized.
sorting your array before the loop makes it 6x faster. same data. same algorithm. the CPU just stopped guessing wrong.
a mispredicted branch flushes the entire pipeline. 15-20 wasted cycles. per wrong guess.
A lesson I needed to learn again and again:
If something broke after, let's say, the two latest changes in your code base, where one is large and the other tiny - do not immediately assume the large one is guilty.
I know, I know, it is so tempting to narrow the debugging area by ignoring changes that look too small or irrelevant to matter.
Start testing with the smallest suspicious change. It can save you a lot of time.
Learning ML basics and looking into the numpy source code led me into some computing archaeology today.
Did you know that when you import numpy for the first time, it detects the CPU features available on your machine?
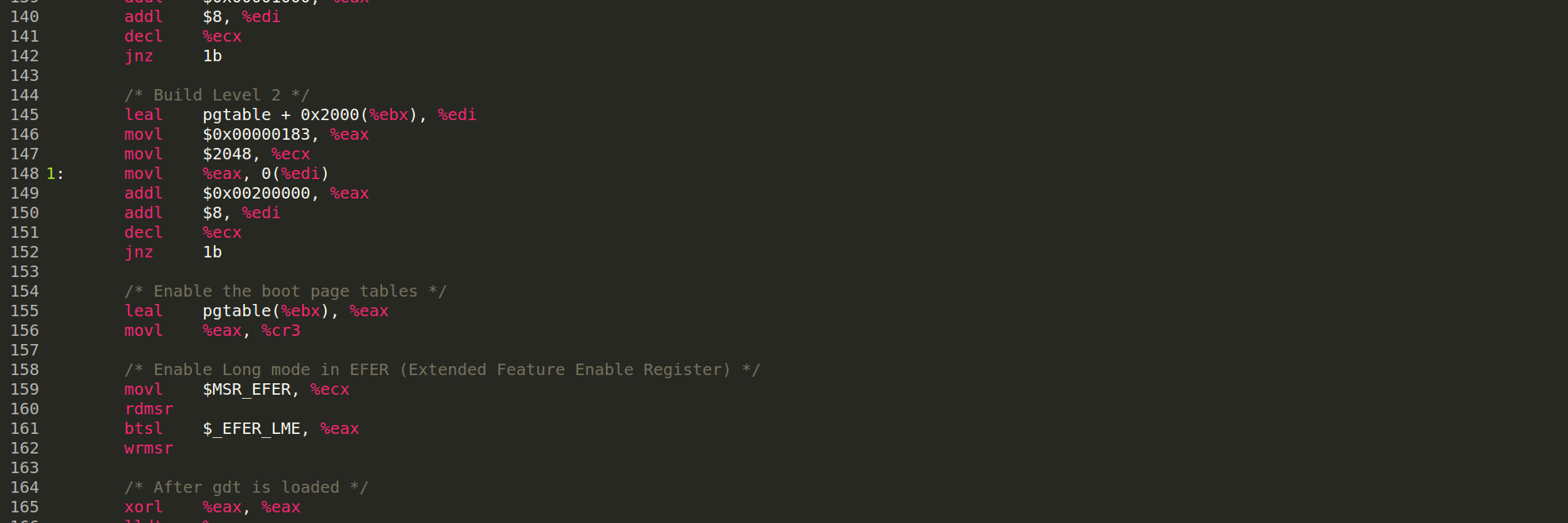
Looking at how it does this, I stumbled upon an interesting detail: on x86-32 PIC builds, numpy preserves the value of the ebx register around the CPUID instruction.
Without googling do you know why?
@0xAX That's a great explanation. In fact I saw an occasional bug in some old code in a JNI library which turned out to be exactly this but only seemed to crop up when loaded in certain environments under Java 25. Fortunately, I was able to update the code it with a compiler intrinsic!
CPUID returns one of its results in the ebx register.
But in 32-bit position-independent code, ebx may already be used as the PIC register holding the Global Offset Table base.
This is easy to reproduce in Godbolt. With GCC 4.9.4, this code compiles with -m32 -O3, but fails if we add -fPIC. So numpy avoids the problem by swapping ebx with a temporary register before and after CPUID. GCC 5 will preserve this register by itself, so the direct version compiles with newer GCC versions too
https://t.co/IK6wKZeO8w
Question for people who learned ML after years of software engineering outside ML - what was actually worth implementing yourself?
Arrays? Some linear algebra?Optimizers? CUDA kernels?
Trying to find the point where learning from scratch stops being useful and quietly becomes a separate multi-year project