The BEST 7 Trading Indicators
0:00 - RSI & SMA
1:17 - Trend Trader
2:36 - Smart Divergences
3:52 - RSI & Envelope Band
4:54 - Buy & Sell Signals
5:49 - Trailing Stop Loss
6:47 - Liquidity
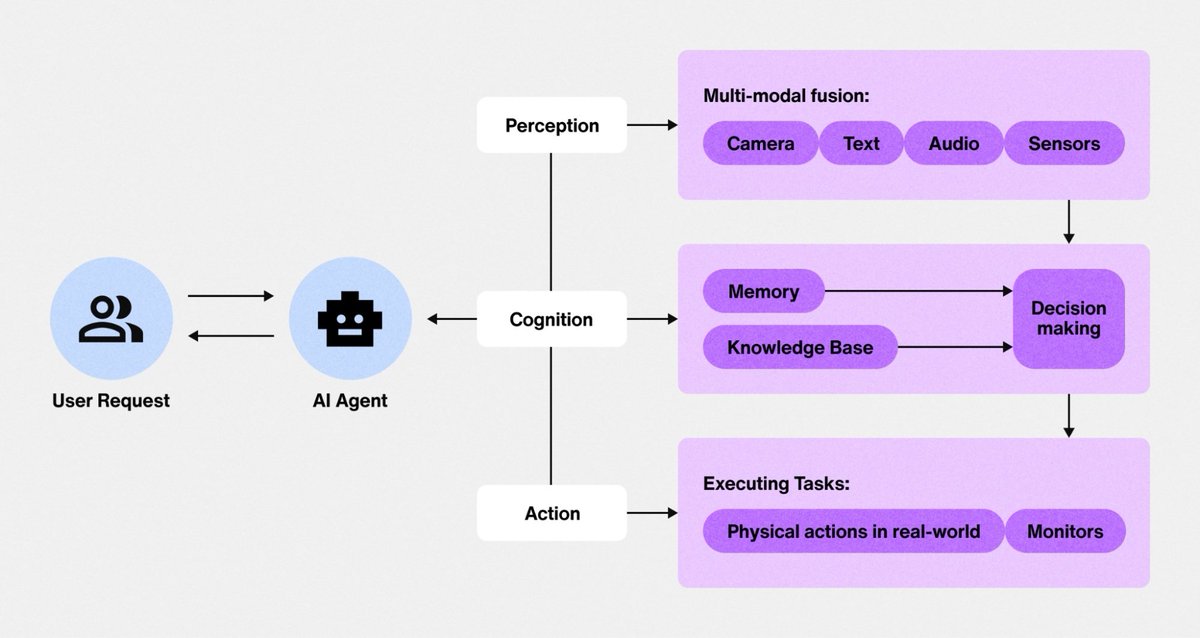
If you’re building AI agents right now, you’re probably doing it wrong.
Most “agents” break after one task because nobody’s teaching the real framework. Here’s how to build one that actually works ↓
Here's a common misconception about RAG!
Most people think RAG works like this: index a document → retrieve that same document.
But indexing ≠ retrieval.
What you index doesn't have to be what you feed the LLM.
Once you understand this, you can build RAG systems that actually work.
Here are 4 indexing strategies that separate good RAG from great RAG:
1) Chunk Indexing
↳ This is the standard approach. Split documents into chunks, embed them, store in a vector database, and retrieve the closest matches.
↳ Simple and effective, but large or noisy chunks will hurt your precision.
2) Sub-chunk Indexing
↳ Break your chunks into smaller sub-chunks for indexing, but retrieve the full chunk for context.
↳ This is powerful when a single section covers multiple concepts. You get better query matching without losing the surrounding context your LLM needs.
3) Query Indexing
↳ Instead of indexing raw text, generate hypothetical questions the chunk could answer. Index those questions instead.
↳ User queries naturally align better with questions than raw document text. This closes the semantic gap between what users ask and what you've stored.
↳ Perfect for QA systems.
4) Summary Indexing
↳ Use an LLM to summarize each chunk. Index the summary, retrieve the full chunk.
↳ This shines with dense, structured data like CSVs and tables where raw text embeddings fall flat.
The bottom line:
You don't need to retrieve exactly what you indexed. Match your indexing strategy to your data, and your RAG system will perform significantly better.
What indexing strategies have worked best for you?