This is a super exciting release - Claude Fable 5 is the same underlying model as Mythos but with added safeguards. The benchmarks are great and it's SOTA on everything by a margin but I'll add that *qualitatively* also, this is a major-version-bump-deserving step change forward (imo of the same order as Claude 4.5 was in November), peaking especially for long problem-solving sessions on very difficult problems. You can give it a lot more ambitious tasks than what you're used to, the model "gets it" and it will just go, and it's never felt this tempting to stop looking at the code at all (but don't do this in prod!). The model still has quirks that people will run into and the safeguards are configured to be a little too trigger happy for launch, which can hopefully be tuned over time.
I feel a lot of things changing as working software increasingly comes out on a tap. The Jevon's paradox kicks in and I feel my own demand for software growing substantially. You can ask for anything - explainers, visualizers, dashboards, bespoke single-use apps (e.g. a full wandb that is hyper-specific just for your project), you can 10X your test suite, auto-optimize code, run giant research projects with custom HTML for the results, anything! "Free your mind" (Matrix ref). Really looking forward to all the things people build!
Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. https://t.co/OVVPJO7VQx
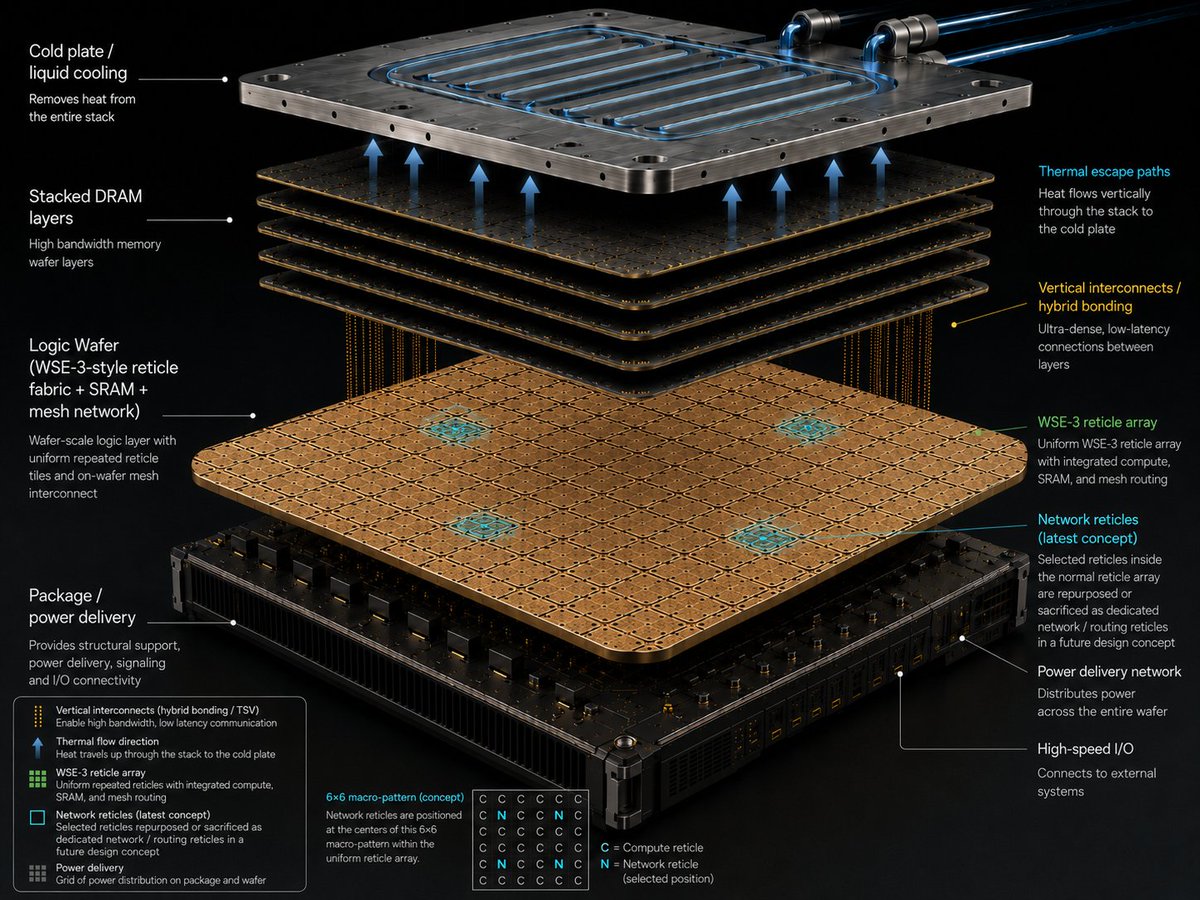
Cerebras did what the industry calls impossible: turned an entire 46,225mm² wafer into one chip. Defects on silicon that big are inevitable, so they built in redundancy and custom per-batch masks that route around every bad core, landing near 100% usable wafers. The results: 900,000 cores and 44GB of SRAM on a single piece of silicon, no packaging, no off-chip hops. And they're not stopping there, now exploring hybrid bonding a DRAM wafer on top for even more fast memory. (1/4) 🧵
@benitoz@SemiAnalysis_ fridge agent , Gemma just takes a pic of the fridge, Mythos figures out what needs restocking, and a grocery MCP places the order. 🫡
OpenAI is developing internal software to run AI workloads across chips from multiple providers, not just $NVDA, per The Information.
Compute chief Sachin Katti described a future with heterogeneous AI infrastructure and hinted OpenAI could make the tool public.
That would matter because Nvidia’s CUDA software ecosystem has been one of its biggest competitive advantages.
OpenAI is already using or planning chips from Amazon, Cerebras, AMD, and its own custom silicon, while preparing Vera Rubin clusters for training later this year.
Anthropic has confidentially submitted a draft S-1 registration statement to the Securities and Exchange Commission.
Pending completion of SEC review, this gives us the option to pursue an initial public offering.
Read more: https://t.co/onGZAhRLvD
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks.
On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.