Home
Language
English
Türkçe
Bahasa Indonesia
About
Privacy Policy
Terms of Service
Pricing
Sign In
Download All
Share
0xchains
@0xchains
Blockchain and AI investment in venture team @antalphagroup @BITMAINtech | Make 🍵 @GTCSE @pennEngineers
Joined January 2022
2.6K
Following
358
Followers
563
Posts
0xchains
retweeted
Sanbu 散步
@sanbuphy
about 1 month ago
花了段时间写了 RL 教程 Hands-On Modern RL,路线是从 CartPole + PPO 入门,然后到 LLM 后训练(RLHF、DPO、GRPO)、Agentic RL。代码先行,公式用来解释现象。英文版很快更新。 目前是草稿版本,RLHF、Agentic RL 部分本地审校中。 欢迎提 PR 或 Issue & 显卡支持:https://t.co/PtgSByY96U
0xchains
retweeted
paulwei
@coolish
11 days ago
同时观察美股5000多支股票,能看到什么? 昨晚做了个所有美股板块轮动趋势的可视化面板: https://t.co/PUD9b1cihw 作为一可视化观察学习市场的的新视角来抛砖引玉。 如果把股票的不同板块,比喻成人的五脏六腑, 这有点像用医学放射科CT扫描, 像观察肿瘤发展转移动态一样,去可视化看市场变化。 代码开源:https://t.co/EoM23fg8W3 视频介绍⬇️
coolish's tweet video.
0xchains
retweeted
Phoenix Yin
@Phoenixyin13
11 days ago
这是我最重要的信息转发之一。 这篇论文的第一作者是我极为钦佩的人,也是我的好朋友,来自
@Tsinghua_Uni
姚班顶尖选手Guowei Xu,现在他在
@Harvard
进行人工智能大模型的科研工作。 Guowei这篇论文精准击中了目前LLM搜索的两个致命瓶颈: ① 只有最后一步对错的sparse verification ② 所有候选答案都靠自回归生成,永远困在模型自己概率分���的entropy shell里 由此,Guowei和他的团队提出BES这个全新的搜索框架,引入Forward Evolution,让大模型像生物演化一样思考,打破大模型原有的概率限制,逼它组合出平时根本写不出来的神仙脑洞。同时进行Backward Decomposition,把大任务拆成一堆一眼就能看出对错的子目标。这样大模型在往前走的时候,每走一步都有及时的Dense Feedback,走偏了立刻能纠正。 BES 在理论上成功证明了演化算子能帮大模型跳出思维定势,而倒推法可以指数级减少模型试错所需的样本量。 当目前主流的Post-training提升算法都失效时,BES 依然能带得动并且让模型能力持续输出稳定提升,这无疑是���破了主流算法的天花板,值得许多人关注学习。 我认为,Guowei这篇论文给Agent指明了新路。 对于现在大火的 AI Agent 任务流、多智能体协同来说,这种一边基因重组思路,一边倒推拆解目标的方式,提供了一套更高效、更不容易跑偏的底层搜索算法。 值得一
提的是,@Kevin_Guow
eiXu 同学不仅在清华姚班极其优秀,他曾经也是2022 年第 52 届国际物理奥林匹克竞赛(IPhO)的世界第一,金牌。他未来会在美国直博,大家可以多多关注follow!
See More
0xchains
retweeted
Max For AI
@MaxForAI
13 days ago
这篇可能要迫于压力删了,毕竟我不是vLLM那样的大团队。 且看且珍惜。
Who to follow
龙凤天际1
@tomkaka321
所有叙事,皆由规则塑成。揭示并重构它,是我持续进行的实验。 All narratives are shaped by rules. Revealing and rewriting them is my ongoing experiment.
tomyia
@tomyia62211
打不死得韭菜
0K246Crypto.hl
@0K246Crypto
Alpha hunter | Defi MAXI | @HyperliquidX REF LINK🔗https://t.co/sdrF9AYhKJ | Advisor🔍 @stillearly_ | NFA | monk mode
0xchains
retweeted
Phyrex
@PhyrexNi
14 days ago
伊朗表示已经放弃了对霍尔木兹海峡直接收通行费,但会收取一些其它的费用来维持霍尔木兹海峡的稳定和通畅,目前还没有看明确的收费标准。 据日经新闻消息,伊朗将在和美国达成协议结束冲突后30天开放霍尔木兹海峡,来自所有国家的船只将能够像之前一样自由、安全地航行,就像在封锁之前一样。 和我预期的一样,做空 WTI 仍然是非常有效的,而且会有一个较长的准备时间,第一阶段先看 85 美元。然后逐渐看 70 美元以下。
PhyrexNi's tweet video.
0xchains
retweeted
qinbafrank
@qinbafrank
15 days ago
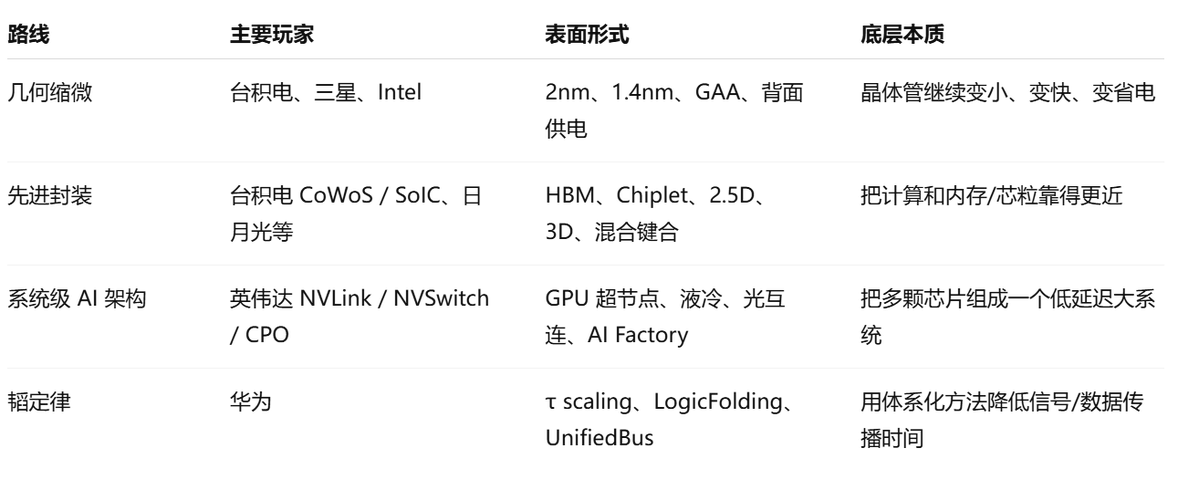
细读华为何庭波的署名论文来理解“韬(τ)定律”,从这篇论文能看到“韬(τ)定律”在缩放时间理论上的五个核心要点,但是越细看你越会发现华为、英伟达、台积电几家在未来的演化迭代路径上的底层逻辑是一致的。详细聊聊我的理解。 1、先说“韬(τ)定律”的五个核心要点 1)LogicFolding / 逻辑折叠。 文中给出的定义是:LogicFolding 是一种设计方法,把数字电路、模拟电路和存储电路划分到垂直堆叠的有��层中,通过缩短关键路径走线来优化性能、功耗和面积。它不是简单把封装做厚,也不是普通 2.5D Chiplet,而是更接近“把原本二维平铺的逻辑电路折到垂直方向 2)Unified Bus统一总线, 传统 AI 集群需要多层协议栈:PCIe、NVLink 或专有互联、以太网或 InfiniBand、RDMA、软件消息传递等。每一层协议转换都会增加序列化、DMA 缓冲、握手和延迟。 Unified Bus 的目标是用一个在机箱内和机箱间都运行的单一协议,替代这些协议栈,并在整个系统中暴露原生内存语义。论文称,这能把远程访问延迟从传统协议栈的几十微秒级降到约 100 纳秒,沿主要通信轴线的系统 τ 降低约 500 倍;在机架规模上,使系统更接近一台结构一致的单一机器,内部称为 System-as-One-Chip / 系统即芯片。这其实就是芯片—服务器—机柜—数据中心级别的系统协同。 3)Hi-ONE近封装光引擎 何庭波的论文认为,当单个 AI 芯片带宽进入 Tb/s 级别时,铜缆布线会遇到体积、SerDes、散热、供电和可靠性限制。华为提出的Hi-ONE是一种近封装光互连节点引擎。文中称单 Hi-ONE 模块可提供 8 Tb/s 带宽,把 SerDes 传输距离从约 100 厘米缩短到约 5 厘米,同时把面板间传输距离从不足 1 米扩展到 100 米。 这说明华为的系统级路线也把光互连纳入核心架构,不只是外部光模块,而是更接近 near-package optical I/O / 近封装光 I/O。 4)3D Folding 论文认为,传统 2.5D AI 芯片存在一个几何矛盾:逻辑芯片面积按 N² 增长,所以计算能力按面积增长;但 HBM、SerDes、供电等资源主要沿封装边缘进入,带宽、I/O 和电源能力只按周长 N 增长。计算能力按 N² 扩,边缘资源按 N 扩,二者差距会越来越大。 3D Folding的作用是把原来位于边缘的资源转移到表面或垂直方向:电源通过背面供电和集成电压调节器,高速存储通过与逻辑混合键合,光 I/O 通过近封装 Hi-ONE,从而让内存、互连、电源和逻辑同步扩展。 华为把3D折叠视为 AI 加速器在 2030 年后继续扩展的核心拓扑。 5)逻辑与内存重新融合 论文还有一个重要产业判断:过去几十年,CPU 和内存是解耦发展的;但 AI 时代正在逆转这种解耦。 原因是AI工作负载对内存带宽、延迟、功耗和封装的要求极高。HBM、混合键合、3D 堆叠 SRAM 都说明:数据传输和计算本身一样重要,逻辑和内存正在重新走向紧密物理集成。论文进一步判断,随着逻辑和内存融合,供应链中的影响力会向内存和封装供应商倾��。 2、论文还列举了“韬(τ)定律”未来的挑战在于: 1)EDA 工具链不够。 传统 EDA 是二维时代的工具,主要在面积、时序、功耗之间优化。全尺寸 LogicFolding 需要工具把多个堆叠芯片视为一个连续设计实体,在单元粒度而不是模块粒度上跨层布局,并对垂直互连、TSV、KOZ 排除区、晶圆间工艺偏差做统一签核。论文称华为已有初步内部工具,但 τ 原生、开放、多物理场、3D 原生工具链仍是未来十年最重要的赋能投资之一。 2)晶圆间工艺偏差。 LogicFolding 可能把不同批次甚至不同节点的晶圆进行键合,阈值电压、驱动电流、互连 RC 偏差会影响时钟分布和保持时间裕量,需要智能冗余、自适应补偿和 τ 感知签核。 3)垂直互连不是免费的。 混合键合和 TSV 都会带来电阻、电容和面积开销,TSV 的 keep-out zone 还会挤占标准单元,所以逻辑折叠必须证明“缩短水平连线获��的收益”大于“增加垂直互连的成本”。 4)τ 是时间定律,不是能耗定律。 论文承认,如果速度提升 10 倍但功耗也提升 10 倍,系统仍可能超出电力约束。因此,τ 缩放必须和能量优化配套,包括近封装/共封装光学、背面供电、内存内计算、动态电压频率调节等。 整体上从这篇论文能看出,“韬(τ)定律”是体系化设计创新 + 三维集成 + 封装/键合工艺,而不是传统意义上的“制程节点突破”。“韬定律”更像是从单点工艺创新,转向体系化、系统级提升。 在先进制程受限、摩尔定律经济性下降的背景下,华为提出一种后摩尔时代的系统级缩放路线:以 τ 时间常数为统一指标,通过 LogicFolding、Unified Bus、Hi-ONE、3D Folding、逻辑—内存融合和 τ 原生 EDA,把性能提升从单点制程竞争转向全栈系统工程。 3、为什么说华为、英伟达、台积电几家在未来的演化迭代路径上的底层逻辑是一致的? 从个人角度这和台积电先进封装、英伟达NVLink/HBM/CPO/AI Factory 的方向本质相通。 大家都在解决同一个问题:数据移动太慢、太贵、太耗电。 这其实是全球半导体巨头共同迈向“后摩尔时代”的终极共识。 无论是华为的“韬定律”,还是国际巨头的动向,都在整体系统上下功夫: 1)台积电: 早就意识到先进制程太贵且良率存在物理瓶颈,因此大力发展 CoWoS 和 SoIC 等先进封装技术,像搭积木一样把多个小芯片(Chiplet)拼在一起。 2)英伟达: 现在的 AI 算力怪兽(如 Blackwell 架构及后续产品),其优势不仅在于单颗 GPU 核心的制程,更在于它通过 NVLink 高速互连技术,把海量的高带宽内存(HBM)和光芯片高度集成在一起,打破了“内存墙”和“通信墙”。 3)华为: 面临外部环境的极限施压,必须在缺乏最尖端制造设备的情况下,依靠先进封装、新材料、光电共封装(CPO)和极其强大的系统工程能力,来硬生生“拼”出等效于 1.4nm 的综合性能。 当然差异也是有的。 例如台积电的先进封装回答的是:“我如何把多个 die、HBM、chiplet、硅中介层、RDL、混合键合做成可量产、可测试、可良率控制的产品?” 华为“韬定律”回答的是:“在制程缩微受限时,我如何从器件、电路、芯片、系统全链路降低 τ,让性能、能效、密度继续提升?” 两者本质相通,因为都在解决:数据搬运太慢、太耗电、太占面积。但它们不是同一层级的东西。台积电更像是底层制造/封装能力平台,华为更像是系统架构与设计方法论。 再看英伟达这几年最典型的路线,就是“不只做 GPU,而是做整套 AI 计算系统”。英伟达 GB200 NVL72 就不是单颗 GPU 的故事,而是 rack-scale 架构:72 颗 Blackwell GPU、36 颗 Grace CPU,通过 NVLink 组成一个 72-GPU domain,对外表现得像一个巨大的 GPU,并通过 NVLink Switch 提供 130TB/s 的低延迟 GPU 通信带宽。 英伟达这套模式和“韬定律”的系统级思路非常接近:不要只看单颗芯片峰值���力,而要看 GPU—GPU、GPU—CPU、GPU—内存、机柜—机柜之间的数据移动效率。 4、投资逻辑:后摩尔时代系统级工程路线的基础设施。 华为“韬定律”不是单一芯片制造突破,而是后摩尔时代的系统级工程路线。它利好的不是单一晶圆厂,而是先进封装、探针测试、EDA、设备材料、高速互连、光互连、散热、电源、系统软件这一整套基础设施。 为什么?因为一旦目标从“晶体管做小”变成“路径做短、系统更快”,产业链价值就会从单点晶圆制造扩散到: 先进封装:把 chiplet、HBM、逻辑芯片靠近; 探针卡/测试设备:多 die、多层、复杂封装对测试要求更高; 封装基板/PCB/连接器:高速信号完整性更关键; 光模块/硅光/CPO:板级和机柜级数据传输从电走向光; EDA/IP:二维布局不够,需要 2.5D/3D/封装/热/功耗协同设计; 散热/液冷/电源:集成度越高,热和供��越难; 系统软件/总线/互联协议:硬件堆起来还不够,调度和通信协议也要重构。 所以投资上,要去找:��能让芯片之间、芯片内部、芯片与内存、服务器与服务器之间的数据路径变短,谁就能在产业链上占据优势。 未来先进性更多看“数据走多远、走多快、耗多少电、系统能否协同”。华为“韬定律”、台积电先进封装、英伟达 AI Factory,本质上都在围绕这个问题做文章
See More
0xchains
retweeted
Max Lv
@m0d8ye
16 days ago
这就是老黄说的失去中国市场的代价。软硬协同的开发会弥补中美两国在制程工艺上的代差,当中国大模型足够好的时候,出口硬件送大模型会对美国 AI 产业造成更大的打击。
0xchains
retweeted
AI Will
@FinanceYF5
18 days ago
毫无疑问,这是目前最棒的AI系列课程 斯坦福大学CS 153课程,已在YouTube平台发布 演讲嘉宾包括:Sam Altman、Jensen Huang、Satya Nadella、Andrej Karpathy、Ben Horowitz
0xchains
retweeted
Macro_Lin | 市场观察员
@LinQingV
22 days ago
长鑫存储扩产的设备供应链全景 长鑫现在合肥两座、北京一座,三座12英寸厂。合肥一厂11万片月产能,二厂8万片,北京厂7万片,加起来接近30万片,全部满产。两年涨了三倍,2024年初差不多10万片,2025年底冲到28到30万,2026年目标稳在30万。按晶圆片数算全球DRAM占比已经接近15%,但按销售额算只有3.97%,片数堆上来了,单价还在追赶。 工艺端,G4在16纳米已经量产,DDR5良率从2024年底的80%升到现在的90%区间。G5对应15纳米,2026年底量产。HBM2去年下半年就上了,比外界预期提前两年,主要供华为昇腾910。HBM3的前段晶圆产能主要在合肥和北京现有基地内部腾出来,目标月产6万片,约占30万片总产能的20%。后段的堆叠和封装由上海新建的HBM封测厂承接,2026年底投产。 产能还在继续扩。上海新厂分两期,Phase 1产能10万片,2027年初量产,Phase 2同样10万片,2028年初量产。加上现有的30万片,远期产能目标是奔着50万片以上去的。华为也在建一条10万片规模的产线,专门配合长鑫做昇腾系列所需的HBM3和LPDDR5X,2026年下半年开始全面量产。 IPO募资295亿,DRAM技术升级拿了130亿,量产线升级75亿,前瞻技术研发90亿。多家券商纪要提到其中约200亿会直接变成设备采购订单,叠加2024年712亿的存量Capex节奏,是国产设备厂未来两年最确定的基本盘。 长鑫正在进行的大规模扩产,设备采购需求非常可观。每个品类的国产化进展差异很大。 光刻是最大的对外依赖,国产化率连5%都不到。主力机器是ASML的NXT:1980Di,每小时出275片,覆盖到16纳米节点,目前还能正常采购。被荷兰管制的是NXT:2050i及以上,每小时295片,2023年9月起要许可证,2024年1月起对华许可基本停发。修正一个流传很广的说法,275到295片是1980Di到2050i的代际跳变,不是1980系列内部的迭代。长鑫往15纳米以下走,这道墙绕不开。上海微电子的28/14纳米DUV还在攻关,光刻这一环短期无解。 刻蚀占设备投资25到30%,是国产化最深的核心工艺。北方华创的ICP在长鑫产线上市占超过50%,中微的CCP介质刻蚀机做到50比1以上深宽比,专门用于HBM的TSV深硅通孔。但存储节点100比1深宽比的极端工艺,孔洞必须互相平行规整,任何偏差直接砸良率,Lam和东京电子在这个区间仍然是主力。 薄膜沉积占约25%,品类分得细。PECVD做绝缘层,PVD做金属互连,ALD做电容器的高k介电层。拓荆科技的PECVD已经批量进入长鑫DDR5和LPDDR5产线,北方华创的PVD覆盖铝铜溅射和氮化钛溅射。但DRAM电容器核心的高k ALD设备,应用材料和ASM的位置很难动,拓荆的ALD在验证爬坡中还没有大规模上���。整体看PECVD和PVD的国产化率高一些,ALD最低。 CMP只占设备投资5到7%。华海清科占国产CMP装备销售90%以上份额,12英寸Universal-300已经导入长鑫。新变量是中微4月29日刚过会的收购杭州众硅,6抛光盘架构是国际首创,效率比主流4盘方案高一截。国产CMP从单点供应正式进入双供。 清洗国产化率30到40%,盛美上海的SAPS/TEBO兆声波清洗覆盖FinFET和DRAM的16到19纳米制程。热处理40到50%,北方华创立式氧化炉打头,激光退火端莱普科技两年内国内市占从3%涨到16%,跟长鑫和长存共同开发匹配DRAM工艺的设备。这几个环节已经跑通了。 最薄弱的三个环节是量测检测、涂胶显影和离子注入。量检测国产化率个位数,KLA全球占51到54%,精测电子进了长鑫12英寸产线,中科飞测也在部分环节往里切,但高端光学检测和电子束检测差距仍然明显。涂胶显影国产化率仅4%,东京电子在大陆市占超过90%,芯源微是唯一量产替代,目前只在封装端站住了,前道关键层还进不去。离子注入同样个位数,万业凯世通累计交付40多台。弹性最大的三个环节,也是短期内最动不了的三个环节。 长存三期产线2026年一季度国产设备占比首次过50%,目标100%。长鑫设备国产化率已突破45%,但仍低于长存三期产线的水平。根源在工艺。DRAM的电容刻蚀和光刻精度对先进DUV的依赖远高于3D NAND。NAND可以靠堆层数绕过光刻瓶颈,DRAM要正面硬刚,结构性差异,跟意愿无关。 外部约束在收紧。4月22日美国众议院外交事务委员会投票通过了MATCH法案,路透社称之为"国会史上最大规模的半导体出口管制立法审议"。法案把长鑫、中芯国际、长江存储、华为、华虹一起列入covered facility,���止ASML的DUV浸没式光刻机对长鑫出口,禁止盟国为既有设备提供维保,要求荷兰和日本在150天内对齐美方规则。主要推手是美光。一旦通过,NXT:1980Di这条最后的灰色通道就堵死了。长鑫本身还没进BIS实体清单,但设备进口其实早就在2022年10月那波18纳米以下DRAM工艺限制的笼子里。 45%的国产化率意味着长鑫在两条腿走路,海外设备保良率,国产设备保供应链安全。MATCH法案的压力反而在加速这个进程。长鑫每往国产设备多切一个百分点,对应的就是北方华创、中微、拓荆、华海清科、盛美这些公司实打实的订单增量。上海新厂分两期共20万片的增量产能,加上现有产线的持续技术升级,未来两到三年国产设备厂面对的是一个确定性极高的需求窗口。 从更长的时间尺度看,长鑫的扩产不只是一家公司的资本开支计划。它每走通一个工艺节点,整条12英寸国产设备平���就多一次被验证、被复用的机会。刻蚀和CMP已经证明了这条路径,薄膜沉积和清洗正在跟进,量测和涂胶显影是下一个要啃的硬骨头。这个验证循环一旦转起来,国产设备的竞争力会以远超线性的速度积累。
See More
0xchains
retweeted
新闸路摸鱼仔
@derek03275486
23 days ago
长鑫IPO真正拉爆的,主要是设备和材料 逻辑很简单: DRAM国产化加速 → 长鑫扩产 → 国产设备导入 → 国产材料验证 → 订单释放 个股太多了,不一一推荐了,最核心大概这几个,但是市值较大,弹性未必是最大 北方华创 中微公司 拓荆科技 华海清科 让 GPT 和豆包拉一下 ETF,看了看都没问题,拿不准个股直接上 ETF 就行了 561980 招商半导体设备ETF 159516 国泰半导体设备ETF 562590 华夏半导体设备ETF 159558 易方达半导体设备ETF 588170 科创半导体ETF 注意:要避开半导体全产业链和泛芯片、IC 类的 ETF,这些里面通常包含很多消费电子的票,纯浪费感情
See More
0xchains
retweeted
一起发财
@yiqifacai
23 days ago
其实花几万听课和看我一样的,因为我和叶老师一样也是PCB死多头,我已经喊了很久旗帜鲜明看好PCB生态了,目前从铜箔和电子布切换到CCL 层涨价逻辑比较顺利,铜冠的所有利润我都切换到了CCL生益科技,即使经过回调,生益我依然有超过40%的利润,但是依然没有到我心目中的目标价位。 我是定增价248附近入的第一笔胜宏,最近两天的回调中一直在加仓,下周跌还会继续加。 一切Rubin延期,未来换玻���板,碳化硅,PCB没技术含量,英伟达不答应涨价,都是噪音。 很快市场就会意识到,PCB就是2025年底的存储。 (持仓利益相关,股市有���险,投资需谨慎)
0xchains
retweeted
Art of Speculation
@ArtofSpecuycky
25 days ago
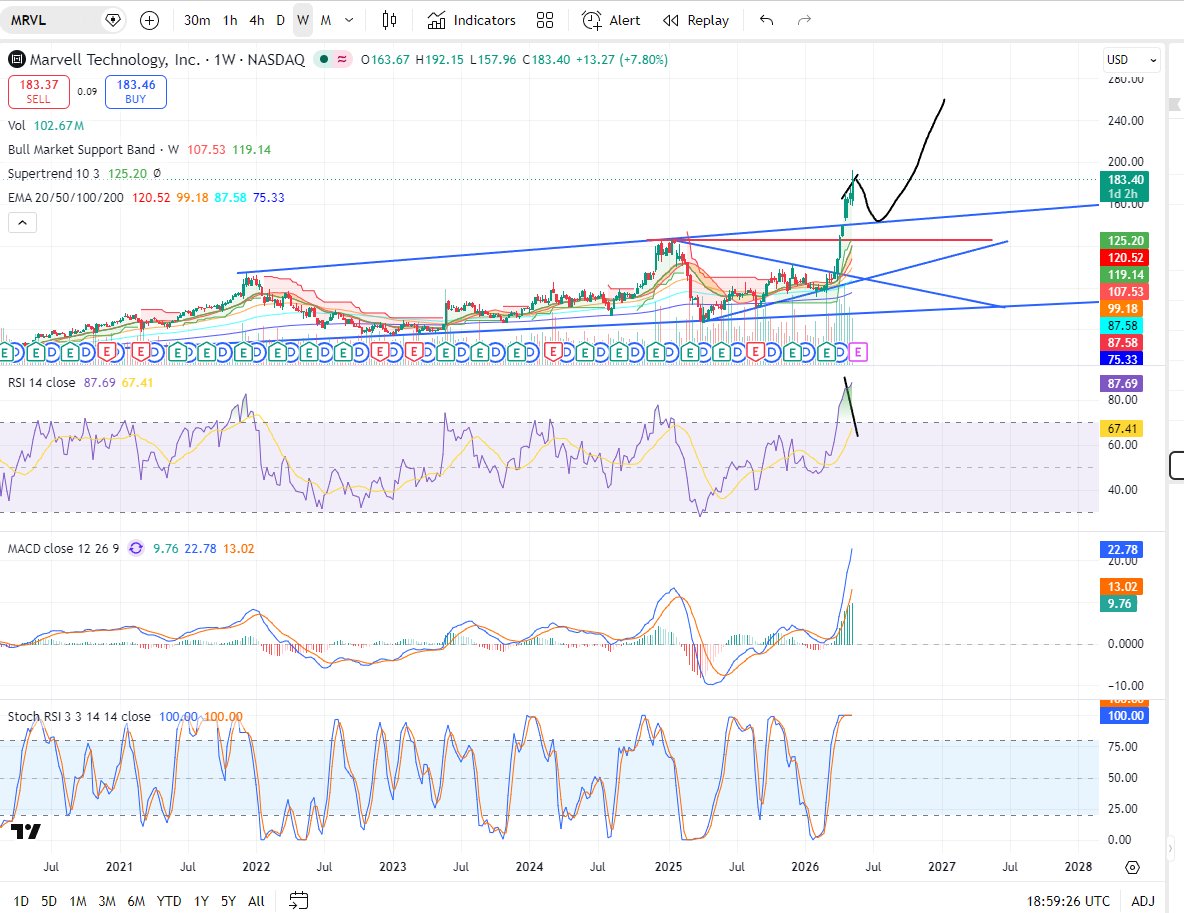
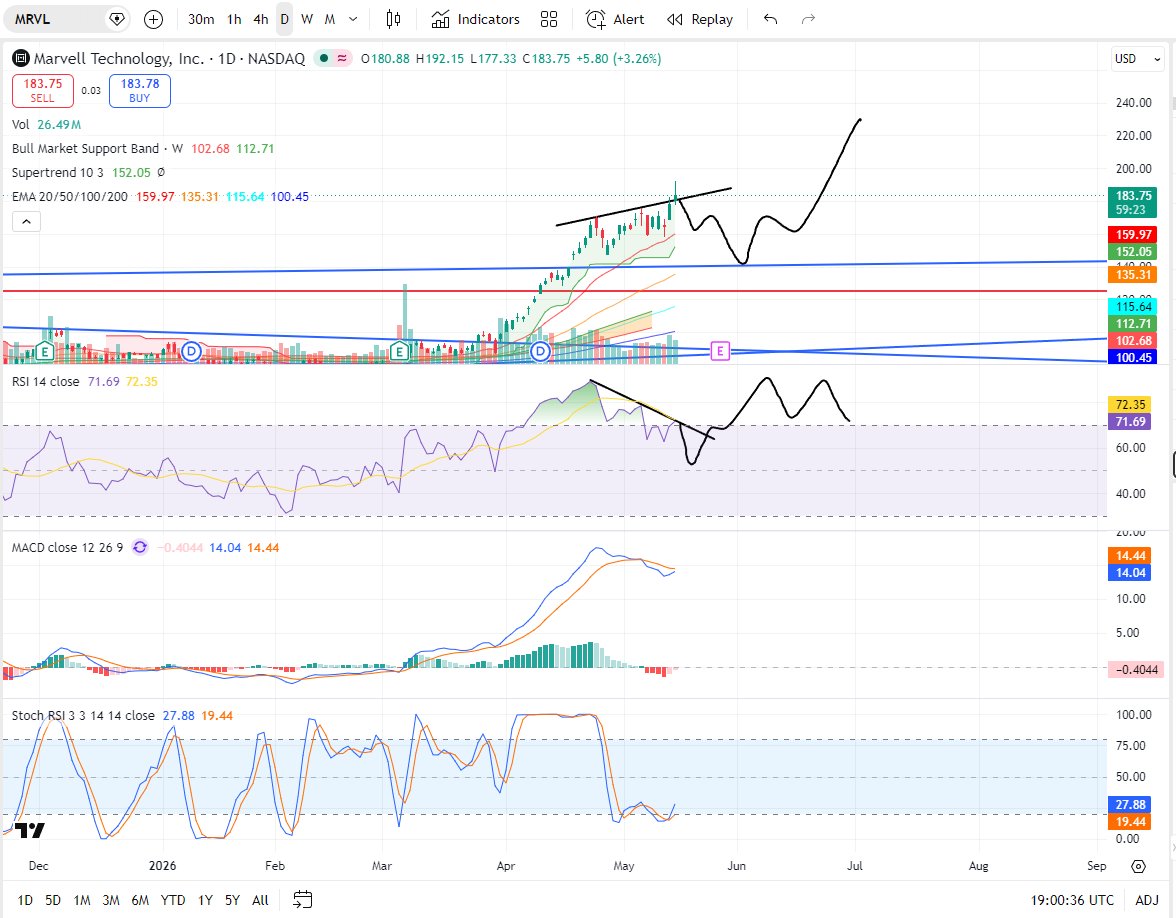
$AVGO 是AI芯片的龙头。但历史告诉你,真正暴富的人买的是龙二 $MRVL 先说一个关于半导体行业的反直觉规律: 在一个严重缺货的市场里,获利最大的往往不是龙头,而是那个追赶中的龙二。(Herman老师分析intel观点我觉得说的很好,也同样非常适用于 $MRVL) 理由很简单: 当产能严重不足,买家再也无法只依赖龙头一家供应商。他们开始把订单给原本觉得"不够好"的替代者。而这个替代者,突然发现自己的产品以前没有人要,现在成了香饽饽——价格可以谈,条款可以谈,一切都变了。晶圆缺货时,原本没有人愿意把订单给Intel的客户,开始认真研究18A了。 那么,在AI定制芯片这个正在快速缺货的赛道里,获利最大��龙二会是谁? 我的答案是 $MRVL 。 1. 先理解结构 AI芯片市场分两层: 第一层:通用GPU Nvidia统治,没有任何人能挑战。H100、B200、Blackwell——超大规模云厂商需要它们,别无选择。 这层市场已经被充分定价了。Nvidia市值5.7万亿,没有人会漏掉这个机会。 第二层:定制ASIC(专用AI加速芯片) 这是一个完全不同的故事。 每一家超大规模云厂商都在开发自己的专用芯片: Google有TPU(张量处理器),Amazon有Trainium(AI训练)和Inferentia(推理),Meta有MTIA(AI推理加速),Microsoft有Maia(Azure AI加速)。 为什么要自己开发芯片? 因为通用GPU虽然强大,但它服务所有人,没有为特定工作负载优化。自研芯片可以针对自己的模型架构和推理需求精确设计,功耗更低,成本更低,效率更高。 这是一个不可逆的趋势——超大规模云厂商越大,自研芯片的动力越强。但有一个关键问题:这些云厂商需要设计合作伙伴。芯片设计是极其复杂的工程,需要有人懂SerDes,懂先进封装,懂chiplet集成,懂供应链——不是随便一家公司能做到的。 全球有能力承��超大规模云厂商定制ASIC设计的公司,只有两家: $Broadcom,和 $Marvell。 2. AVGO vs MRVL:龙头和龙二的真实差距 先看数字: Broadcom在ASIC市场占约55-60%的份额,与Google的TPU合作锁定到2031年,客户包括Meta、OpenAI等顶级厂商。Marvell约占15%的份额,排名第二Broadcom领先是事实,毫无争议。 但有几个数字值得认真对比: AVGO MRVL 市值 $2万亿 $1,470亿 ASIC市占 55-60% 15% FY26AI营收 $200亿+ $96亿 Forward PE 31倍 36倍 Broadcom在定制ASIC市场记录了约$200亿的AI总营收,而Marvell的AI相关营收约$96亿。 从市值角度:AVGO的市值是MRVL的13.6倍,但ASIC市场份额只是MRVL的4倍,AI营收只是MRVL的2倍。这个不对称,是MRVL存在的核心机会。 3. MRVL独特的地方:两场战争同时押注 这是我认为最关键的一点,也是MRVL和所有其他AI芯片公司最本质的区别。 MRVL同时押注了两个互相独立的万亿级叙事: 叙事一:定制ASIC——去Nvidia化的最大受益者 Marvell的数据中心部门FY2026增长46%,超过$60亿,管理层指引FY2027同比再增约40%。定制芯片年化营收已达$15亿规模,两个AI加速器项目处于高产量阶段,第三个超大规模客户合作正在进行。 Nasdaq 最重要的一个进展: 2026年4月,Google被报道正在与Marvell进行深度谈判,共同开发内存处理单元和下一代TPU,这正是Google此前几乎完全交由Broadcom负责的工作。如果谈判成功,Marvell将成为AI行业最具战略意义的芯片项目之一的核心设计伙伴。 这是什么意思? Broadcom和Google的TPU合作锁定到2031年——这是Broadcom的护城河,但不是MRVL的天花板。Google开始和MRVL谈,不是要取代Broadcom,而是要建立第二供应商。这正是"缺货时代,落后者获利"的经典逻辑。 当TPU的设计需求超过了Broadcom单独能服务的上限,Google开始把部分项目分给MRVL。 这一单谈��,MRVL同时拥有Amazon和Google双超大规模客户锚定——三个超大规模客户(Amazon、Microsoft、Google)大幅降低了单一客户集中的风险,给市场提供了更清晰的多年营收增长路线图。 叙事二:光互连DSP——AI集群神经系统的命门 MRVL是目前唯一同时覆盖定制ASIC设计、1.6T光学DSP、硅光子技术(通过Celestial AI收购)和CXL交换的全栈公司——这是任何单一竞争对手都无法复制的护城河。 光互连DSP是什么? 当GPU和GPU之间需要通信,数据需要在光纤里传输。但光纤里走的是模拟光信号,计算机需要的是数字信号。DSP(数字信号处理器)就是这两个世界之间的翻译器——它把数字数据编码成光信号发出去,再把收到的光信号解码成数字数据。 MRVL的PAM4 DSP是全球800G和1.6T光模块的核心芯片之一。光互连业务的需求与AI集群的互连基础设施同步扩张——每一个上线的AI集群都需要完整的互连协议栈,不��要等待GPU的供应情况。 这是最关键的逻辑: GPU供应有时候是稀缺的,但光互连不等GPU——只要数据中心在建,只要AI集群在运行,光互连就需要。 MRVL的DSP是一个和GPU并行运行的独立需求,不是GPU需求的影子。 4. 我自己的判断:为什么MRVL的故事比AVGO更有弹性 AVGO是龙头,MRVL是追赶者。 但在这个特定的历史时刻,追赶者的弹性更大,原因有三: 原因一:基数效应 AVGO已经是$2万亿市值,要翻倍需要成为$4万亿的公司。MRVL只有$1,470亿,翻倍只需要$2,940亿——和AVGO现在市值的15%相当。同样的资金流入,对MRVL股价的推动效果是AVGO的13倍以上。 原因二:Google的变量 AVGO和Google的合作是锁定的,这是护城河,但也意味着它的上行惊喜已经被充分定价。MRVL和Google的谈判还没有正式宣布——这是一个尚未被市场定价的潜在催化剂。如果Google正式宣布,MRVL立刻拥有Amazon+Google双超大规模客户,ASIC市场份额从15%向25%+跳��的路径被打开。 原因三:两个叙事不相关 AVGO的核心护城河是ASIC和VMware软件。 MRVL的两个叙事——ASIC和光互连DSP——是完全独立的业务。 ASIC受益于去Nvidia化,光互连受益于AI集群扩张。两个独立的增长引擎,互相不依赖,互相不替代。 MRVL在多个AI基础设施顺风中同时暴露:定制芯片、光互连、数据中心网络和更广泛的超大规模资本支出周期。这种在AI主题内的多元化暴露,使它成为纯粹的GPU标的(如Nvidia)的有吸引力的补充。 5. 估值合理吗? $MRVL:Forward PE 36.4倍,市值$1,470亿。 $AVGO:Forward PE 31倍,市值$2万亿。 $MRVL的Forward PE比 $AVGO略高,但增速也更快: $MRVL FY27营收预期:约$110亿,同比增速约40% $AVGO FY27增速约25-30%。PEG(PE/增速): $MRVL:36.4 ÷ 40 = 0.91, $AVGO:31 ÷ 27 = 1.15 PEG低于1都算便宜。 用PEG来衡量,MRVL比AVGO便宜约20%。 而且MRVL有Google催化剂这个尚未被定价的变量,AVGO���有。如果Marvell股价涨到$400,需要数据中心营收FY27超过$90亿,Google ASIC合同正式宣布,自定义硅年化营收达到$30亿。在这些条件下,ASIC业务40倍Forward EV/EBITDA,光互连业务20倍EV/Sales。 我觉得2027年是很有可能达到的,这还是在理性的估值下,如果是ai融涨疯牛选择忽略估值的话,如果NVDA到360分析师预测最高,也就是8.8T, 我预测8-10T,那么AVGO会到3-4T, MRVL到500B-1T都问题不大。 6. 三个需要追踪的关键变量 变量一:Google ASIC合同的正式宣布 这是目前MRVL最大的潜在催化剂。谈判已经在进行,但没有正式宣布。每过一个季度没有宣布,市场会稍微失去耐心。但一旦宣布,估值逻辑发生质变。 变量二:1.6T DSP的市场份额 Marvell已经开始出货1.6T PAM DSP,基于5纳米工艺,并推出了下一代3纳米版本,将光模块功耗降低超过20%。 800G向1.6T的迭代是MRVL DSP业务的下一个量子跳跃。���果MRVL能在1.6T时代维持甚至提升市场份额,光互连业务的营收会非线性增长。 变量三:Celestial AI的硅光子���合 MRVL收购了Celestial AI,进入硅光子领域。这是CPO时代最关键的技术平台——把光学引擎直接集成进芯片封装。如果MRVL能在CPO时代把DSP和硅光子整合成一个完整的解决方案,它的价值会远超现在的定价。 7. 最终判断:MRVL是这轮AI牛市里最干净的不对称机会 AI芯片市场分三类公司: 第一类:Nvidia——已经被充分定价的龙头。故事最好,估值最贵,上行惊喜空间有限。 第二类:纯ASIC公司(AVGO)——护城河深厚,但增速放缓在定价中。Google TPU锁定到2031年是确定性,也是上行惊喜的天花板。 第三类:MRVL——两个叙事都在爆发,Google催化剂未定价,市值基数小。 这是不对称机会的经典形态, 下行有Amazon锚定,有光互连稳定收入,不会归零,上行有Google合同宣布+CPO爆发+ASIC市场份额提升,估值可能从$1,470亿走向$5,000亿+。 $MRVL也是我重仓持有的标的之一,短期technical角度今天收长上影线,日线级别调整要来,加仓机会在第一目标165,第二目标140。如果给机会到140补那个缺口,我仓位加满(图1)。 总结:回到那个反直觉的规律:缺货时代,落后者获利最大。 ASIC市场正在缺货——Broadcom一家根本无法满足所有超大规模客户的定制需求。光互连正在缺货——AI集群每季度都在扩张,DSP的需求只增不减。MRVL是这两个缺货赛道里,那个正在被需要的追赶者。 历史一次次证明:当产能不足、供应商只有一两家的时候,第二名是最好的弹性高的投资标的(Nvidia和Amd,TSMC和Intel。) 因为所有人都开始认真研究它了。 #MRVL #Marvell #AVGO #Broadcom #ASIC #定制芯片 #光互连 #DSP #Google #Amazon #Nvidia #AI芯片 #半导体 #美股 #龙二补涨 #CPO #硅光子 #AI基建 #USStocks #AIStocks #数据中心 #去Nvidia化
See More
0xchains
retweeted
Art of Speculation
@ArtofSpecuycky
25 days ago
所有人都在买GPU和存储。没有人告诉你光模块公司的总市值比美光还低 我想从一个反常识的问题开始:GPU是AI的大脑,存储是AI的记忆。那光是什么?光是AI的神经系统。但神经系统从来不是最先被注意到的。存储已经涨了10倍,GPU更不用说。光的时代,刚刚开始。 1. 先说一个结构性的错误定价 在Nvidia的NVL72机架里,光模块的采购金额占到整个机架的20%。2026年全球AI光收发器市场规模预计从2025年的$165亿增长到$260亿,同比增速超过57%——这是半导体赛道里增速最快的子领域之一。 但所有光模块公司的总市值,比美光一家还低。这个错误会被纠正。问题只是什么时候。 2. 光和存储不一样的地方 存储的接力是季度级别的事件——供需拐点,财报超预期,市场重新定价,SNDK从$200涨到$900,这个过程很快。光的接力是年级别的结构性变迁,因为光的技术路线本身正在发生一次范式转移: 第一阶段(现在):可插拔光模块 800G → 1.6T → 3.2T 线性增长,随数据中心扩张 第二阶段(2026下半年):近封装光学NPO 光模块移向芯片旁边 需求非线性跳升 第三阶段(2027-2028):共封装光学CPO 光引擎直接封装进芯片 这是终局,也是最大的价值重构 Meta在OFC 2026分享了大量数据,证明CPO比可插拔光收发器更可靠,成本更低,功耗更少。Nvidia在GTC展示了CPO将在2027/28年用于Scale-Up互连。5年内所有AI数据中心互连都将是光。 这不是预测,是物理定律。铜在��速率下信号损耗太大,功耗太高,距离太短。光没有这些问题。 3. 光在吃铜,不只是光吃光 生成式AI集群需要比传统云服务多10到100倍的光纤,正在把现有铜互连逼到物理极限。 这是大多数人没想到的逻辑——光的增长不只来自数据中心规模的扩大,还来自光替代铜的渗透率提升。每一代迭代,光吃掉更多铜的市场。这是双重驱动,不是单一驱动。 4. 产业链七个卡位,从上游到下游 现在我来把整条产业链拆清楚。 七个公司,覆盖从最上游的衬底到最下游的网络设备。 🔬 最上游:硅光衬底 $SOI 做的是硅光PIC的衬底材料——整个产业链最上游的原材料。没有SOI的衬底,硅光芯片就没有基础。护城河极高,几乎没有竞争对手能短期内介入。和TSEM形成上下游绑定:SOI提供衬底,TSEM代工成芯片。 🏭 代工层:硅光晶圆厂 $TSEM(Tower Semiconductor)硅光版本的台���电。 今天刚刚���生的重大事件: TSEM宣布签署$13亿的2027年硅光合同,收到$2.9亿产能预付款,2028年还有更大合同在谈判中。计划资本支出$9.2亿专门用于硅光扩产,Q2营收指引$4.55亿同比增22%。 TSEM最聪明的地方在于:它不赌哪条技术路线赢。 可插拔、NPO、CPO,三条路线都用TSEM代工。就算市场对技术路线判断错了,TSEM依然受益。这是光通讯产业链里确定性最高的picks-and-shovels。 💡 激光器层:光的心脏 光模块的核心是激光器。没有激光器,光模块什么都不是。 激光器分两条技术路线: 磷化铟(InP)路线——$LITE(Lumentum) LITE是目前唯一能量产200G每lane EML激光器的供应商,是1.6T收发器的关键零件。Nvidia预先锁定了LITE的EML产能,推迟交货期超过2027年。 Nvidia向LITE投资$20亿,用于加速AI基础设施光学技术。LITE CEO称2026年是激光器芯片销售的"突破年",刚收到历史上最大的CPO超高功率激光器采购承诺。 LITE的护城河是时间积累的——InP激光器的制造需要极其精密的工艺,20年积累的经验是任何竞争对手短期无法复制的。而且LITE不只押注现在:EML是可插拔时代的命门,ELS外置激光器是CPO时代的命门,OCS光路交换机是未来AI集群的光学路由器。 三个产品线覆盖了光通讯从现在到2030年的完整需求。 硅光(SiPho)激光器路线——$SIVE(Sivers Semiconductors) Sivers专注于CPO系统的高性能InP激光阵列,Jabil合作是第一个商业验证信号,证明技术正在从研究走向真实超大规模部署。 SIVE不是要打败LITE,而是作为CPO时代激光器供应链里的补充供应商——当LITE和COHR产能不足时,SIVE是下一个选项。整个CPO产业的激光器供应严重短缺,补充供应商的价值会被重新定价。 🔭 光学系统层:从组件到整合 $COHR(Coherent Corp) COHR最新Q3财报:营收$18.1亿同比增21%,数据中心和通信板块$14亿,同比增40%。Nvidia��样投资$20亿入股COHR。COHR是整个光通讯赛道里垂直整合程度最高的公司。从InP晶圆到激光器到光模块到系统,全部自己做。COHR正在扩大6英寸InP晶圆产能,这是推动毛利率持续提升的核心驱动力——规模越大,每片晶圆的成本越低,利润越高。 LITE和COHR的关系是竞争者也是互补者: LITE:激光器专家,EML垄断,聚焦 COHR:光学系统整合商,体量更大,更全面 🏗️ 物理基础设施层:光纤和连接 $GLW(Corning) Corning是光通讯产业链里最让人意外的标的——一家成立于1851年的玻璃公司,正在成为AI基础设施的核心受益者。 Q1 2026光学通信业务增长36%,分部净利润增长93%。2028年营收目标$300亿,2030年$400亿,内含年化增速19%。两个额外的超大规模云厂商签署了长期协议。 Nvidia命名Corning为下一代AI基础设施光连接合作伙伴,投资$5亿+最高$32亿股权,在美国建三座专属光学工厂。 Corning做的是光纤、线缆和连接器——不是最性感的产品,但是不可或缺的基础设施。 城市要运转,不只需要主干道,还需要所有的小路、接头、路牌。 Corning做的就是光通讯世界里的所有"小路和接头"。 而且这些"小路和接头"是消耗品——每建一个数据中心都需要,每升级一个机架都需要。 📡 网络层:AI时代的网络基础设施 $NOK(Nokia) Nokia是这七个标的里最被市场误解的。大多数人还在用"翻盖手机公司"的眼光看Nokia。 Nokia 2026营收预期同比增长7.5%,EPS增长21.2%,光网络业务增速20%,AI和云业务增速49%,单季度新增€10亿AI和云订单。 Nokia做的是什么? 光传输网络(OTN)——把数据中心之间用光连接起来的骨干网络。这是Scale-Across的核心基础设施。 Nokia的第六代超相干光学技术PSE-6s,是目前全球少数能实现800G甚至1.2T长距离光传输的技术之一。 Nokia收购Infinera之后,从"转卖别人芯片的公司"升级为"拥有自己光芯片工厂的公司"——同样的技术路线,市场给LITE估值66.5倍,给COHR估值35倍,Nokia只有30.8倍Forward PE。 这个估值差距是最大的错误定价之一。 七个标的的完整产业链图 最上游 SOI(硅光衬底) ↓ TSEM(硅光代工) ↓ 激光器层 LITE(InP EML,可插拔+CPO) COHR(垂直整合,光学系统) SIVE(CPO激光阵列,高赔率) ↓ 物理基础设施 GLW(光纤、线缆、连接器) ↓ 网络层 NOK(光传输网络,骨干连接) 每一层都有自己不可替代的护城河。 每一层都在受益于同一个趋势。 6. 为什么是现在? 2026到2027年是在1.6T供应链建立立足点的关键时期,在一线客户的设计导入将决定长期赢家。现在是design-in阶段——产品正在被超大规模客户选中和锁定。等量产阶段到来,市场才会充分定价这些公司的价值。 在design-in阶段买入,等量产阶段收获——这是光通讯投资最好的时机。 7. 仓位逻辑 高确定性(重仓): TSEM → 今天$13亿合同,产业链里最硬的催化剂 LITE → EML垄断+Nvidia锁定,现在到2028年都受益 COHR → 垂直整合,体量最大,Nvidia $20亿入股 中等确定性(配置): GLW → Nvidia直接合作,物理基建不可或缺 NOK → ���被低估的估值,但故事兑现需要更多时间 高赔率(小仓位): SOI → 和TSEM绑定,护城河高但流动性低 SIVE → CPO时代的纯粹赌注 8. 光会接力存储吗? 会。但不一样的方式。存储的接力是一次性的价格重估——供需拐点到来,几个季度内完成定价。 光的接力是分阶段的持续重估—— 2026年:可插拔1.6T带来第一波 2027年:CPO开始量产带来第二波 2028年:Scale-Up全面光化带来第三波 三波叠加,才是光通讯超级周期的全貌。存储让你在一年内赚了10倍。光可能让你在三年内赚同样多,但过程更平稳,确定性更高。 最后一句话 光通讯不是一个新故事,是一个被重新发现的旧故事。 光纤已经存在几十年了,但AI让这个故事的量级发生了质变。每当数据中心需要更高密度、更低功耗、更远距离的连接时,答案永远是光。 #光通讯 #TSEM #LITE #COHR #GLW #NOK #SOI #SIVE #CPO #硅光 #光模块 #AI基建 #数据中心 #存储接力 #Nvidia #美股 #USStocks #SiliconPhotonics #CoPackagedOptics #EML #光互连 #AIInfrastructure #光纤 #Nokia #Corning #Coherent #Lumentum
See More
0xchains
retweeted
168X
@168X_Fortune
26 days ago
https://t.co/AT61QZk51k
0xchains
retweeted
花叔
@AlchainHust
27 days ago
花了大半天把张小珺访谈姚顺宇的4小时长访听了一遍。这位去年刚从Anthropic跳到Google DeepMind的哥们,参与过Claude 3.7/4.5和Gemini 3。他给了很多实诚的头部大模型一线研究员的视角。访谈信息密度相当高。说几条我觉得最有意思的: 1. Google禁止员工用Claude Code,但姚顺宇保守估计自己90%代码是AI生成的。不保守估计99%甚至100%。一个清华加斯坦福的物理博士、顶级大模型研究员都靠AI写代码,再有人说自己不能用AI写代码,别特么给自己脸上贴金了。但反过来想,Google连内部都不让用CC和Codex,员工效率得受多大影响啊,这家公司真挺神奇的。 2. 他离开Anthropic的原因里,反对Dario反华占40%。他自己说这不是首要但确实是大原因。他很烦Dario那套「我们必须拥有最强模型才能���AI安全」的逻辑。圈里敢直接喷半年前老东家的人确实不多。 3. Claude 3.5/3.6/3.7的命名是个草台班子般的乌龙。Anthropic早期产品力极弱,「居然管两个模型叫一个名字」,外界为了区分自发叫3.6,Anthropic后来跟随社区习惯把下一个叫3.7。我之前一直以为3.6是个跳过的版本号。 4. Claude Code是「个人英雄主义的开端」。一个叫Boris的研究员自己想做提效工具,后来变成Anthropic最重要的产品之一。完全是bottom-up长出来的,不是规划出来的。 5. Anthropic创始团队一个人都没离开。来自OpenAI的那批核心是一起打过仗的,这才是top-down文化能跑通的根。对比OpenAI高管走光,姚顺宇似乎挺鄙视OpenAI的企业文化和部分高管。 6. OpenAI救了Google一命。逻辑挺反共识:如果ChatGPT一鼓作气把search吃了,Google就完了;正因为做出可能性又没做到极致,反而留了Google反击时间。 7. AI行业最重要的特质不是脑子,是靠谱。原话「那些东西多多脑子,本科生就能干」。一个物理博士说这话,算降维打击,也算给所有想转AI的人吃颗定心丸。 8. 他觉得程序员的未来是1/1000拿100倍工资。不是「程序员消失」,是「极度中心化」。绝大多数失去独特价值,少数顶级爆赚。 9. 他觉得现在很多人说的Scaling Law撞墙,多数是自己代码Bug。原话「修一个Bug带来的进展,远大于一些很神奇的技巧」。预训练在过去几个月还在变强,跟外界「预训练已死」的叙事完全相反。 10. 绝大多数New Lab都会死。 听完最大的感受是:这哥们说话真的没在留情面,又喷Anthropic又喷OpenAI又喷各种「老登」。但他敢喷的底气挺清楚,既不在SSI那条路上,也不靠LP吃饭。他自己原话说的是:「我这个行业又没什么导师又没什么旧友,我当然想喷谁喷谁。」 以及,他在说估计自己也不会在Google待太久,把这话在播客里说出来,我觉得国内头部大模型公司可以去抢一波人了。
See More
0xchains
retweeted
✧ 𝕀𝔸𝕄𝔸𝕀 ✧
@iamai_omni
28 days ago
赏心悦目的技术文章,强烈推荐!
0xchains
retweeted
思维怪怪
@0xLogicrw
29 days ago
前 Anthropic 研究科学家、现 Google DeepMind 研究科学家姚顺宇,在
@zhang_benita
播客「语言即世界」中首次披露了 Claude 3.7 的内部研发过程。他在 2024 年 10 月加入 Anthropic 后被分进一个名为 Horizon 的团队,当时整个团队只有 10 到 11 个人,却负责 Anthropic 强化学习的全部工作,包括数据、基础设施和算法研究。Claude 3.7 从启动研究到最终发布总共耗时四五个月,前两三个月做算法和数据研究,后��个月做训练和基础设施搭建。 Anthropic 押注代码能力并非一开始就有规划。姚顺宇透露,Claude 3 之所以写代码比 GPT-4 强,背后有一个他无法公开的纯技术原因,是某个团队自下而上做出来的。Claude 3 发布后 Twitter 上的大量正面反馈验证了这一优势,Anthropic 管理层随即把代码能力升级为公司级战略全力押注。他认为 Anthropic 能这样快速下重注,核心在于技术一号位 Jared Kaplan 和 Sam McCandlish 本身就是联合创始人,技术上服众的同时也有权拍板,而 OpenAI 做不到这点,Ilya 在的时候也许行,但后来失去了决策权就走了。当时的 Anthropic 在产品方面几乎没有意识,Claude 3.5 半年内发了两个版本却用同一个名字,最终靠外界起的绰号「3.6」才勉强区分开来。
See More
0xchains
retweeted
sukie
@sukie234
29 days ago
如果你觉得你的生活很无聊 你可以去混一混创投圈 很多人觉得混创投圈很难 其实一点都不难 你只需要呆在世界一线城市 打开luma 多参加几个本地带有vc pitch/ hackathon/builder/ AI 的活动 注册Linkedin 加入所有founder’s group ��学校创业club 每次进门前就默念今天我要加满在场所有人的联系方式 散场的时候问一下大家要不要去打德扑/掼蛋 不超过一个月你肯定知道创投圈是什么样了 你会认识到你这辈子都认识不完的神人 威力相当于往微信灌了800个俞浩
0xchains
retweeted
Ace from Money or Life 美股频道
@Money_or_Life_X
28 days ago
光! 这几天花了不少时间去学习、整理光通讯的知识。现在总算可以说是理解了大部分概念。对于没有时间的朋友,其实看懂了下面两张图,也就差不多可以了。 如果你有兴趣阅读Ace总结的全文,请通过订阅我的Patreon获得我的所有文字更新:https://t.co/uOtnJPWsDq
0xchains
retweeted
Berryxia.AI
@berryxia
28 days ago
刚刷到CJ Zafir 发了一条关于 fine-tuning 小模型的帖子,看下来觉得这波建议特别实在。 他直接说,如果你也喜欢玩开源模型 fine-tuning,那先听听这些: 从 1B、2B、4B、8B 这些小模型开始练手,别一上来就冲 27B 以上。 云 GPU 用 Google Colab Pro 就够了,A100 80GB 一小时才 0.6 美元左右,小模型完全够用。 数据集自己造,用 Codex 5.5 先规划,再配 DeepSeek v4 Pro 生成每一行数据。 底座模型推荐 Unsloth 的 instruct 版本,Hugging Face 上直接拉,fine-tuning 笔记也用他们的做参考,直接丢给 Codex 让它帮你改成你想要的配置。 他建议花一天时间把这些东西过一遍:SFT、RL 训练(GRPO、DPO、PPO 这些)、LoRA / QLoRA、量化类型、本地推理引擎(llama.cpp)、KV cache 和 prompt cache。 他说就直接上手吧,Claude、Codex、ChatGPT 都能给你设计第一步的完整计划。 最后他还提到,未来技术会越来越往 5B 到 15B 的 Expert Language Models 走,并非一味堆通用大模型,所以 fine-tuning 这门手艺现在学特别值。 很多公司愿意花 5 万美元以上,让你帮他们用自家数据训个性化模型。 整条帖子的意思就是:fine-tuning 其实谁都能入门,调模型、测模型、用模型,慢慢就能把这变成一份靠谱的事业。 感兴趣的可以看看,还挺有意思。
See More
Last Seen Users on Sotwe
♠️
يمني صنعاني
Fắk Poiii ( nghiện some & swing nặng )
Seen from
Vietnam
سـلـوىٰ🍑
Seen from
Oman
Salman Khan
Seen from
Italy
Beast Gens
sister love
Seen from
France
الأمير 😍
Nike
Josjis Jos
Seen from
Indonesia
Trends for you
1
Avery Wilson
Under 10K tweets
2
National Anthem
Under 10K tweets
3
Texas Tech
Under 10K tweets
4
Paul Blackburn
Under 10K tweets
5
Booed
Under 10K tweets
6
New Yorkers
Under 10K tweets
7
Jeter
Under 10K tweets
8
Oriana
Under 10K tweets
9
NCAA
Under 10K tweets
10
Siri
Under 10K tweets
Most Popular Users
1
Elon Musk
@elonmusk
240.2M followers
2
Barack Obama
@barackobama
119.3M followers
3
Donald J. Trump
@realdonaldtrump
111.6M followers
4
Cristiano Ronaldo
@cristiano
109.1M followers
5
Narendra Modi
@narendramodi
107M followers
6
Rihanna
@rihanna
97.3M followers
7
NASA
@nasa
92.1M followers
8
Justin Bieber
@justinbieber
90.6M followers
9
KATY PERRY
@katyperry
86.9M followers
10
Taylor Swift
@taylorswift13
80.7M followers
11
Lady Gaga
@ladygaga
72.3M followers
12
Kim Kardashian
@kimkardashian
69.4M followers
13
Virat Kohli
@imvkohli
68.7M followers
14
YouTube
@youtube
68.6M followers
15
Bill Gates
@billgates
63.5M followers
16
The Ellen Show
@theellenshow
62.5M followers
17
CNN
@cnn
61.9M followers
18
Neymar Jr
@neymarjr
61.2M followers
19
X
@x
60.9M followers
20
Selena Gomez
@selenagomez
60M followers
Olivia
Online
✨
⭐
💫