JPEG-LM: LLMs as Image Generators with Canonical Codec Representations
- Directly model images and videos via canonical codecs (e.g., JPEG, AVC/H.264)
- More effective than pixel-based modeling and VQ baselines (yields a 31% reduction in FID)
https://t.co/mzseFYN4re
Excited to share our work on BitVM bridges: A novel trust-minimized protocol to bridge Bitcoins to second layers.
Huge thanks to @lukas_aumayr, @alexeiZamyatin, Andrea Pelosi, @zetavar1, and @matteo_maffei for their amazing contributions 🧡
https://t.co/5UiiFse5T4
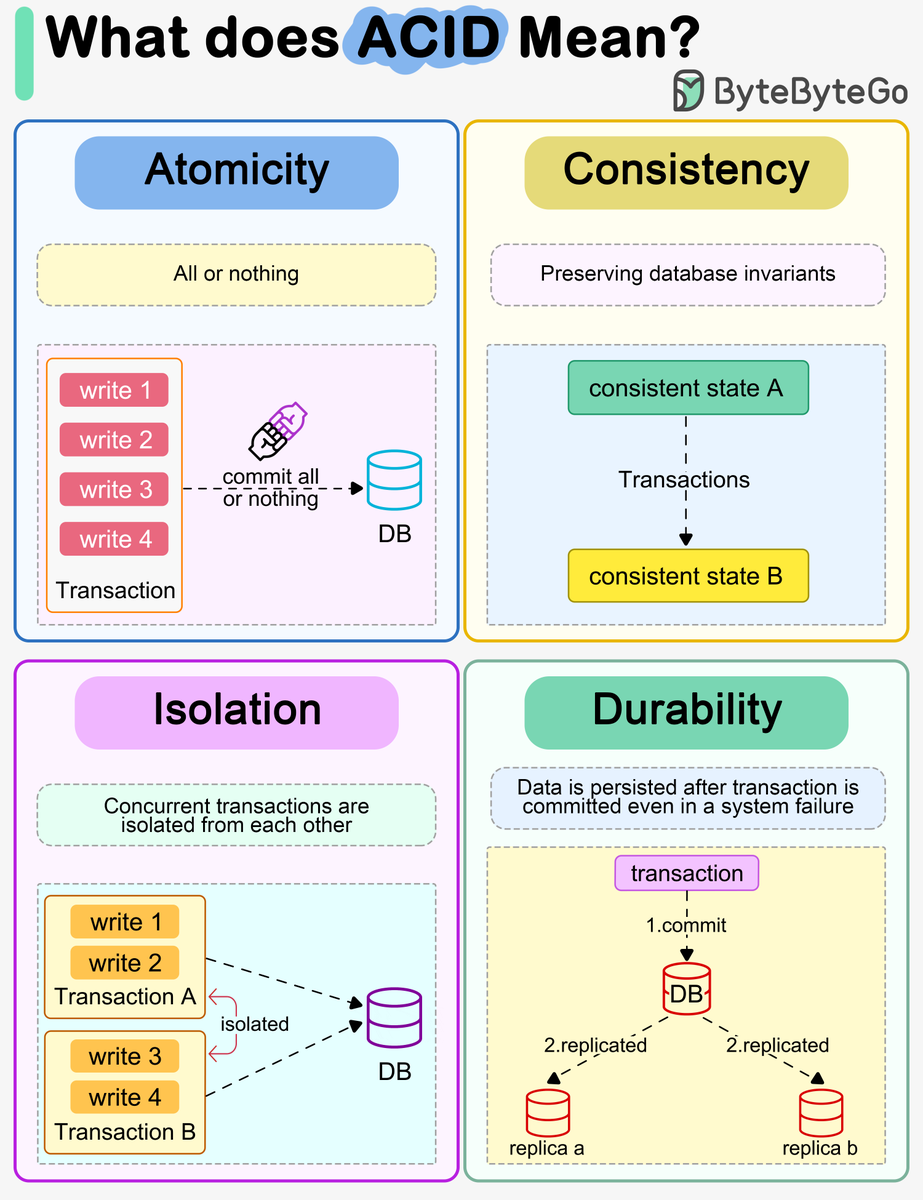
What Does ACID Mean?
Below is a breakdown of the ACID properties, which are critical to the operations of database transactions.
🔹 Atomicity
A transaction is a single unit of operation – either all its data modifications are performed, or none are. If a fault occurs during the transaction, all changes are rolled back as if the transaction never occurred. This "all or nothing" approach guarantees a database transaction is atomic.
🔹 Consistency
Consistency refers to maintaining the database's integrity constraints. Any transaction will only transition the database from one valid state to another, adhering to predefined integrity rules. Unlike consistency in the CAP theorem relating to write visibility, ACID consistency focuses on the validity of transactions.
🔹 Isolation
Isolation ensures concurrently executing transactions cannot view or interfere with each other's intermediate states. While complete "serializability" would run transactions sequentially, practical systems often necessitate weaker isolation levels that still protect integrity at better performance.
🔹 Durability
Once committed, a transaction will persist even after system failures. This means changes are permanent and survive crashes. In distributed databases, durability involves replicating transaction data across nodes to prevent loss.
–
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): https://t.co/kNfv0DVDdf
𝗨𝗻𝗱𝗲𝗿𝘀𝘁𝗮𝗻𝗱𝗶𝗻𝗴 𝗥𝗘𝗦𝗧 𝗛𝗲𝗮𝗱𝗲𝗿𝘀
The Hypertext Transfer Protocol (HTTP) header is a component of HTTP and transmits extra data during HTTP requests and responses. The server uses the HTTP header and the browser to share metadata about the document and the data sent to the browser by the website's web server.
A variety of data in the 𝗥𝗘𝗦𝗧 𝗵𝗲𝗮𝗱𝗲𝗿𝘀 can be used to trace down problems as they arise. As they show the meta-data related to the API request and response, HTTP Headers play a significant role in the API request and response. Headers contain data for:
𝟭. 𝗥𝗲𝗾𝘂𝗲𝘀𝘁 𝗮𝗻𝗱 𝗥𝗲𝘀𝗽𝗼𝗻𝘀𝗲 𝗕𝗼𝗱𝘆
𝟮. 𝗥𝗲𝗾𝘂𝗲𝘀𝘁 𝗔𝘂𝘁𝗵𝗼𝗿𝗶𝘇𝗮𝘁𝗶𝗼𝗻
𝟯. 𝗥𝗲𝘀𝗽𝗼𝗻𝘀𝗲 𝗖𝗮𝗰𝗵𝗶𝗻𝗴
𝟰. 𝗥𝗲𝘀𝗽𝗼𝗻𝘀𝗲 𝗖𝗼𝗼𝗸𝗶𝗲𝘀
In addition to the categories mentioned above, HTTP headers contain a variety of information about different HTTP connection types, proxies, etc. The majority of these headers are used to maintain connections between clients, servers, and proxies, so testing is not necessary.
In general, we have 𝗿𝗲𝗾𝘂𝗲𝘀𝘁 𝗮𝗻𝗱 𝗿𝗲𝘀𝗽𝗼𝗻𝘀𝗲 𝗵𝗲𝗮𝗱𝗲𝗿𝘀. We set a request header when sending a request to an API and get some headers with a response. The common header structure is in the form 𝗡𝗮𝗺𝗲:𝘃𝗮𝗹𝘂𝗲, but it can have many values separated using a comma.
Some 𝗰𝗼𝗺𝗺𝗼𝗻 𝗵𝗲𝗮𝗱𝗲𝗿𝘀 are:
🔹 𝗔𝘂𝘁𝗵𝗼𝗿𝗶𝘇𝗮𝘁𝗶𝗼𝗻: which contains the client's authentication information for the requested resource.
🔹 𝗔𝗰𝗰𝗲𝗽𝘁-𝗖𝗵𝗮𝗿𝘀𝗲𝘁: This header instructs the server which character the client accepts and is set with the request.
🔹 𝗖𝗼𝗻𝘁𝗲𝗻𝘁-𝗧𝘆𝗽𝗲: Specifies the response's media type (text/html or text/JSON), which will aid the client in processing the response's body.
🔹 𝗖𝗮𝗰𝗵𝗲-𝗖𝗼𝗻𝘁𝗿𝗼𝗹: The client may keep and reuse a cached response for the duration specified by the Cache-Control header. This is the cache policy set by the server for this response.
#programming #api #web
Securing your bitcoin with time locks are great in theory, but difficult in practice. In this essay I explain why we don't see many wallets with time locking functionality. #repost https://t.co/tjhQCQDRIa
CARRY TRADE UNWIND IS STILL A MAJOR RISK FOR GLOBAL MARKETS
The Bank of Japan has put itself into a corner after decades of monetary policy easing.
Meanwhile, the Yen short positions hit the highest level in HISTORY exceeding Financial Crisis levels.👇
https://t.co/eqPKiNPaAk
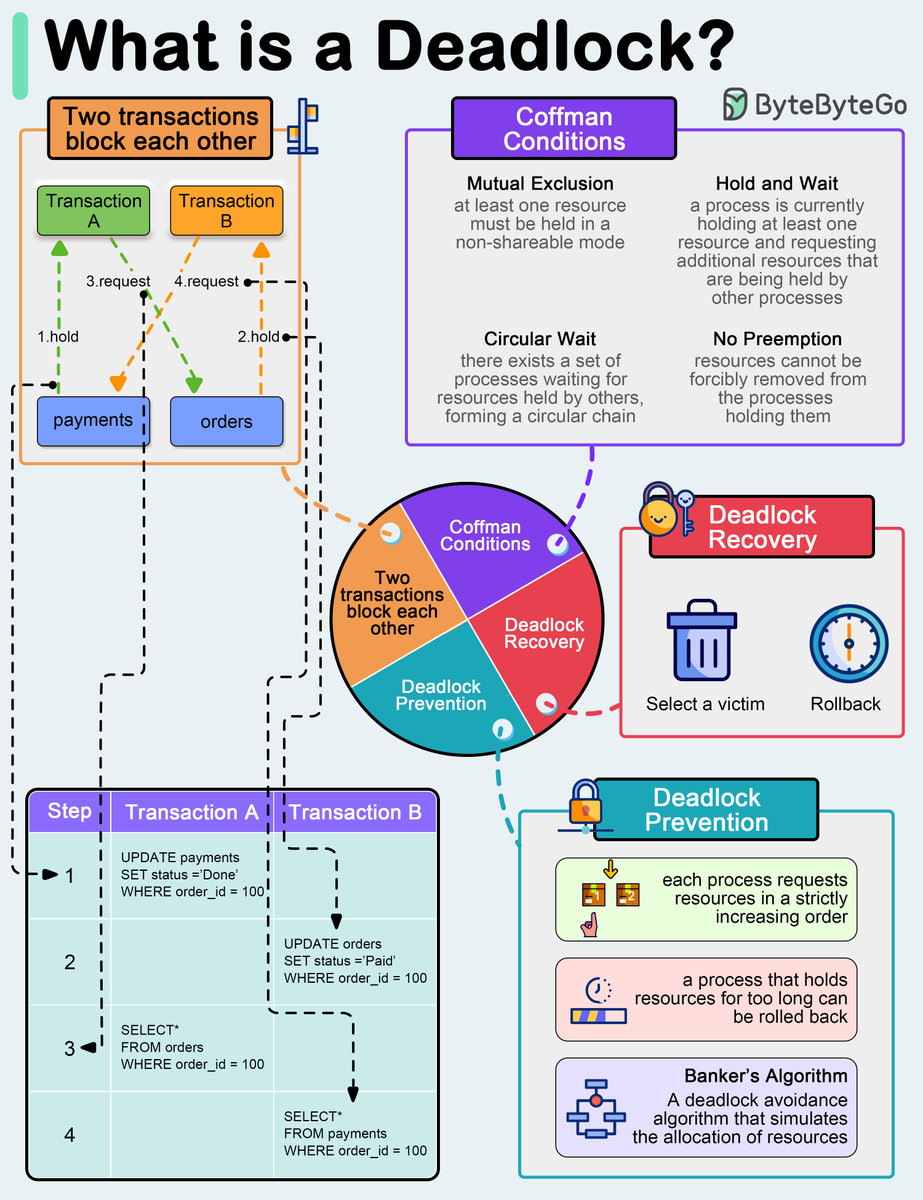
What is a deadlock?
A deadlock occurs when two or more transactions are waiting for each other to release locks on resources they need to continue processing. This results in a situation where neither transaction can proceed, and they end up waiting indefinitely.
🔹 Coffman Conditions
The Coffman conditions, named after Edward G. Coffman, Jr., who first outlined them in 1971, describe four necessary conditions that must be present simultaneously for a deadlock to occur:
- Mutual Exclusion
- Hold and Wait
- No Preemption
- Circular Wait
🔹 Deadlock Prevention
- Resource ordering: impose a total ordering of all resource types, and require that each process requests resources in a strictly increasing order.
- Timeouts: A process that holds resources for too long can be rolled back.
- Banker’s Algorithm: A deadlock avoidance algorithm that simulates the allocation of resources to processes and helps in deciding whether it is safe to grant a resource request based on the future availability of resources, thus avoiding unsafe states.
🔹 Deadlock Recovery
- Selecting a victim: Most modern Database Management Systems (DBMS) and Operating Systems implement sophisticated algorithms for detecting deadlocks and selecting victims, often allowing customization of the victim selection criteria via configuration settings. The selection can be based on resource utilization, transaction priority, cost of rollback etc.
- Rollback: The database may roll back the entire transaction or just enough of it to break the deadlock. Rolled-back transactions can be restarted automatically by the database management system.
Over to you: have you solved any tricky deadlock issues?
--
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): https://t.co/FIzCeaWsZV
A picture is worth a thousand words: 9 best practices for developing microservices.
When we develop microservices, we need to follow the following best practices:
1. Use separate data storage for each microservice
2. Keep code at a similar level of maturity
3. Separate build for each microservice
4. Assign each microservice with a single responsibility
5. Deploy into containers
6. Design stateless services
7. Adopt domain-driven design
8. Design micro frontend
9. Orchestrating microservices
Over to you - what else should be included?
–
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): https://t.co/FIzCeaWsZV
Meta presents Self-Taught Evaluators
Without any labeled preference data, the proposed model utperforms commonly used LLM judges such as GPT-4 and matches the performance of the top-performing reward models trained with labeled examples
https://t.co/d9AlfezZOr