> You took their jobs,
> Had cartoon PFPs on X call them the underclass,
> Made 7-8 figures, while they had to gamble or prostitute themselves online
> On platforms *you* funded
And now the tech elite
Has the audacity to claim foul?
No, it will get worse
Much, much worse
You guys need to realize that 95+% of these AI workflow articles are written by the EXACT same type of person who used to waste all their time setting up VIM keybinds
The primary goal of this person is not and will not ever be "productivity"
Their goal is, in fact, the opposite
Two conversations this weekend make me think that there's a vibe shift afoot in Silicon Valley around what one should work on and what is worthwhile.
Culturally, it feels like the moment is ripe for new frameworks:
• Davos expert morality is stale and discredited.
• It's also apparent that the "just be super based" Counter-Enlightenment is not really an answer. (Yes, woke went too far, but simply inverting it doesn't work.)
• EA is no longer the automatic default for smart people.
• There's increasing skepticism of slot and slop machine dynamics.
Overall, "what is worthy and valuable?" feels like it's becoming more central.
NEW: BITCOIN SLIPPED IN ASIA TRADING HOURS WHILE OTHER RISK ASSETS GAINED AFTER THE US FEDERAL RESERVE CUT INTEREST RATES AND EXPRESSED OPTIMISM ABOUT THE ECONOMY
SOURCE: https://t.co/ComLZ2gDoV
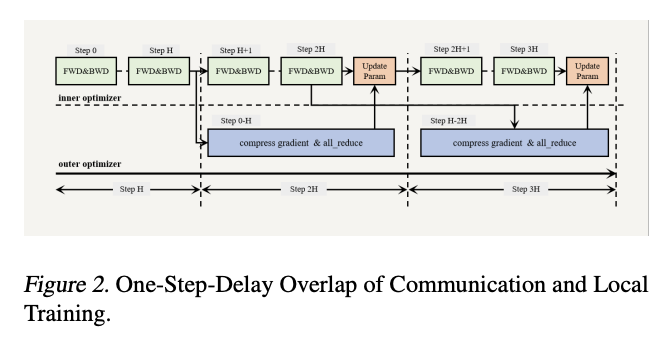
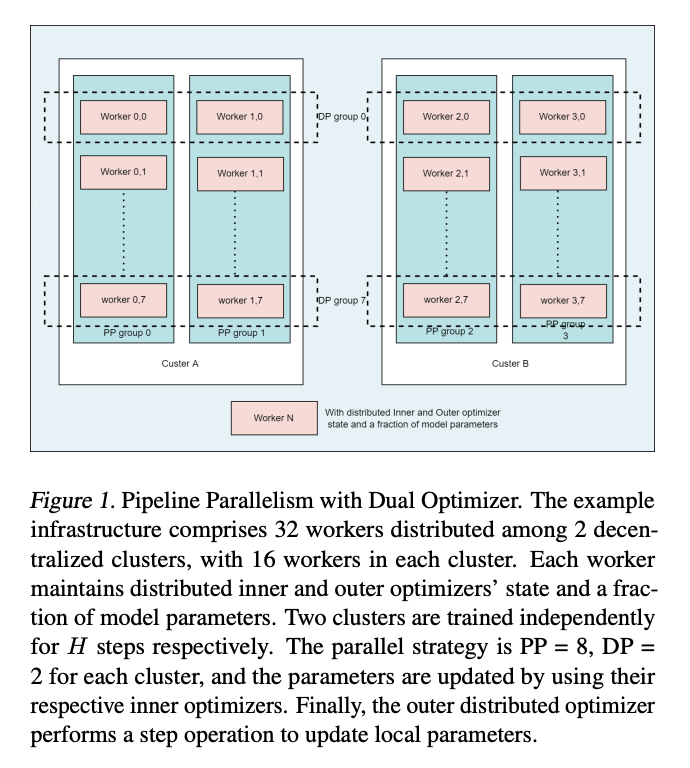
DiLoCoX: A Low-Communication Large-Scale Training Framework for Decentralized Cluster
Afaik, the largest public distributed training done, at 107B parameters with only a 1Gbps bandwidth!
* Based on DiLoCo (FedOpt with inner AdamW, outer Nesterov)
* Add also a pipeline, independent for each DiLoCo replica
* Overlap outer gradient for a whole outer step, itself made of (fake numbers) 500 inner steps of roughly 1s each? so you have 500s to communicate 107B parameters over a 1Gbps bandwidth
* however, that would take ~1680s to communicate, so they also do int4 quantization (1680s->420s) and low-rank (420s->210s)
* And they also adaptively decrease the compression rank through training, but conversely sync more often to be ~iso-com
Their experiments at 1B and 107B on Qwen show DiLoCoX to be almost as good as the *much more* costly Data-Parallel that communicate 1000x more.
One caveat is that they do 4000 steps, but don't mention the token budget -- so i suspect it's quite undertrained.
We've reached a major milestone in fully decentralized training: for the first time, we've demonstrated that a large language model can be split and trained across consumer devices connected over the internet - with no loss in speed or performance.
Yesterday, Bloomberg wrote an article on Hyperliquid. Today, a Bloomberg podcast guest gives his thoughts on risk assets and gave HL a shoutout:
- Risk asset allocation should include digital assets like Bitcoin and Hyperliquid
- Most crypto assets are not revenue generating assets, but Hyperliquid is
- If HYPE was a publicly traded stock, it would be ~4x the current market cap
- Crypto could give birth to the next generation of banks and lending (sounds a lot like Jeff's vision!)
Hyperliquid
AlphaEvolve, our new Gemini-powered coding agent, can help engineers + researchers discover new algorithms and optimizations for open math + computer science problems.
We’ve used it to improve the efficiency of our data centers (recovering 0.7% of our fleet-wide compute resources on average). We’re also using it in chip design and to speed up Gemini’s training, the very models underpinning AlphaEvolve itself — an exciting flywheel of progress!