I've been working on a new LLM inference algorithm.
It's called Speculative Speculative Decoding (SSD) and it's up to 2x faster than the strongest inference engines in the world.
Collab w/ @tri_dao@avnermay. Details in thread.
Join us in welcoming the first cohort of Delta Fellows! 🎉
Congrats to the ~100 amazing researchers and engineers joining the Delta Institute family. We're excited for our fellows to get to know each other through dinners, retreats, and much more!
Our fellows come from diverse backgrounds: undergrads, PhD students, high-frequency trading, big tech, startups, neolabs, frontier labs, and more. What brings them together is their kindness, intellectual curiosity, and intrinsic passion for their field.
https://t.co/mYHDLV2898
i don’t usually share when things go wrong
but recently i was researching world models and it went sideways, but i learned a lot
i wrote a new essay about how not to do research https://t.co/tcF9fBOw4L
Think you’re smart? Prove it.
We built the ranked Human Benchmark for uni students.
Try it out --> https://t.co/eBs95D9aie
P.S. Ur absolutely cracked if you can beat my Tower of Hanoi
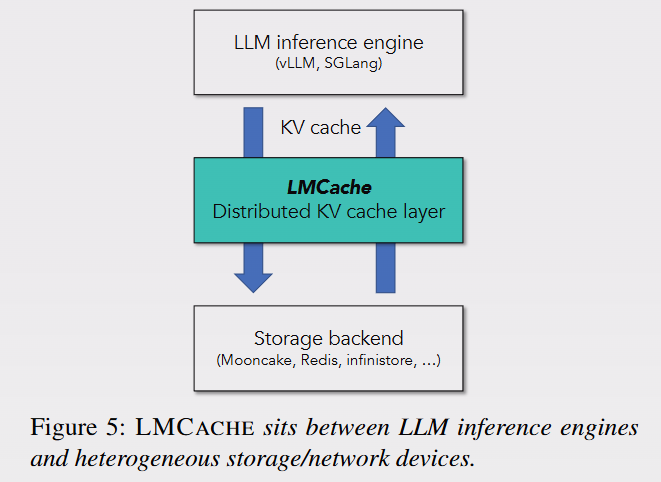
detailed paper on LMCache internals just dropped. covers kv-cache optimization, compute/i/o overlap, dynamic offloading, kv-cache connector interface and overall inference infra design. a must-read if you’re into ml systems and inference.
pushed a change to pytorch that makes cudagraphs 1ms faster. turns out for every module pytorch checks if its in a list. i made it a set and now prod is 5% faster lol