May the 4th be with you!✨ Celebrate with us, you must. Join our Start Up Party Up this Thursday before SF's free 2nd St Fest 🎵
Calling all #AI Jedis - leave your agents at home and sign up for our next monthly meet up to find:
🍕 Outta Sight's specialty pizza
🧋 Jawa juice & green milk (iykyk)
🛸 New learnings, new connections, and @llama_index swag
RSVP: https://t.co/1KJgcvypk9
Our company mission today is to give AI agents the highest-quality document context.
The native open-source libs that agents have access to (e.g. PyPDF) do naive text extraction. But this is incomplete for most advanced knowledge work.
AI agents need the following from documents:
✅ Clean, linearized markdown from multimodal complex documents (charts, tables, scans)
✅ Rich layout / bounding boxes - agents should be able to trace every generated answer/decision back to the source!
✅ Proper image segmentation. Don't just give the agent access to the full page, also give access to image segmentations to enable it to generate more targeted citations.
✅ The ability to define custom schemas so that they can extract from documents in a structured format.
We're working on this with LlamaParse (our VLM-powered service) and LiteParse (our free OSS parser). Check out the blog here!
https://t.co/JBi28JxCbH
Parse text from any PDF in seconds and give it to Claude Code 📑🤖
LiteParse is our open-source, model-free document parser that lets you digitalize text from any document in seconds.
This is especially useful for coding agents, which are great at reading plaintext files but terrible at reading traditional document formats (PDF, Office docs).
We have a one-line installable skill that lets you plug LiteParse into Claude Code and 40+ other agents.
Repo is here: https://t.co/JNER0mVcB8
We've spent years building LlamaParse into the most accurate document parser for production AI. Along the way, we learned a lot about what fast, lightweight parsing actually looks like under the hood.
Today, we're open-sourcing a light-weight core of that tech as LiteParse 🦙
It's a CLI + TS-native library for layout-aware text parsing from PDFs, Office docs, and images. Local, zero Python dependencies, and built specifically for agents and LLM pipelines. Think of it as our way of giving the community a solid starting point for document parsing:
npm i -g @llamaindex/liteparse
lit parse anything.pdf
- preserves spatial layout (columns, tables, alignment)
- built-in local OCR, or bring your own server
- screenshots for multimodal LLMs
- handles PDFs, office docs, images
Blog: https://t.co/Yuq6w77ZgR
Repo: https://t.co/UJy6KQ2bnQ
We love document processing. We also love working with startups.
If you’re a startup ($250k-$50m raised) and need to parse a boatload of PDFs (or .docx, .pptx, .html, .xlsx), come talk to us about LlamaParse!
We have $2k in free credits, dedicated communication, and more.
Check it out: https://t.co/sEAyQFeanH
LlamaParse: https://t.co/TqP6OT5U5O
"Just send the PDF to GPT-4o"
Ok. We did. Here's what happened:
• Reading order? Wrong.
• Tables? Half missing.
• Hallucinated data? Everywhere.
• Bounding boxes? Nonexistent.
• Cost at 100K pages? Brutal.
So we're doing it live.
LlamaParse vs. The LLMs — a free webinar where we parse the ugliest documents we can find across every leading model and show the results side by side.
Hosted by George, Head of Engineering, LlamaIndex
When: March 26th; 9 AM PST
Register 👇
https://t.co/To4m9Zmu7m
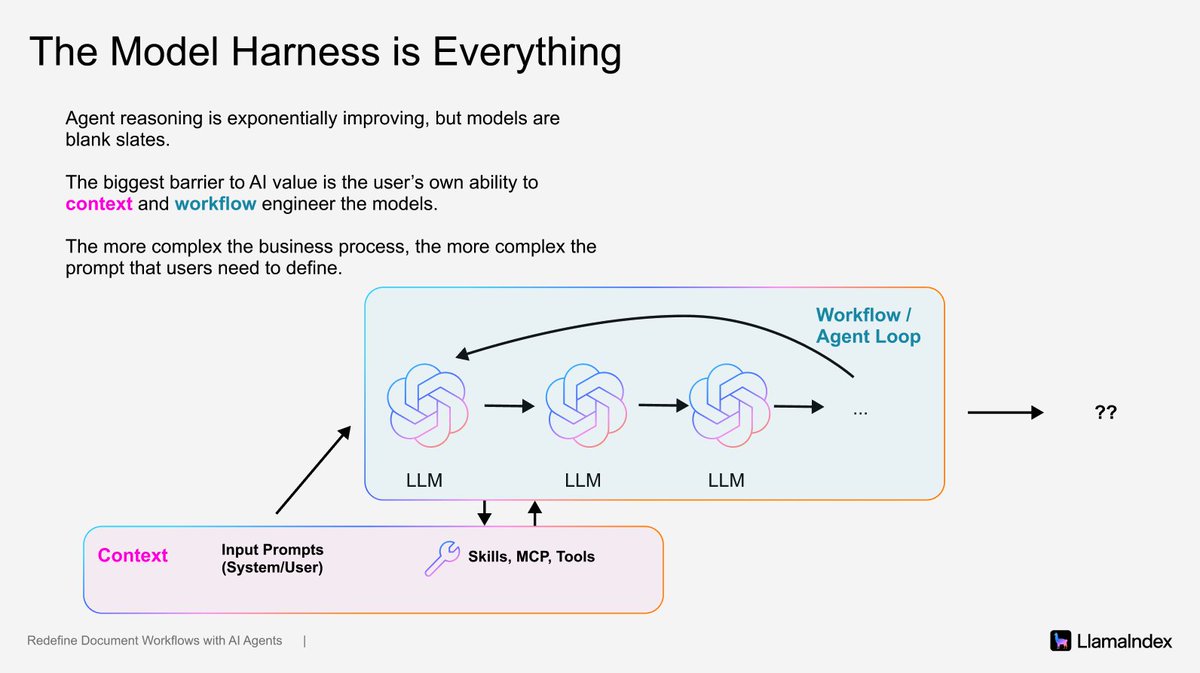
The Model Harness is Everything
We are already living in a world of incredible frontier models and incredible agent tools (Claude Code, OpenClaw). But the biggest barrier to getting value from AI is your own ability to context and workflow engineer the models. This is *especially* true the more horizontal the tool that you’re using.
If you’re using a very generic tool like ChatGPT and Claude Code, you need to spend a lot of work clearly articulating your requirements and specifications so that the agent can actually solve the task relative to your specifications.
Today that looks like being extremely thoughtful about the tools that you select, and writing English very precisely in a https://t.co/GjvKCuoFDJ file to articulate the agent these requirements.
Some of the work around defining the business workflow is inherently time consuming. Think about any document SOP - simply writing the English can take hours to refine, iterate, and optimize. This is where more vertically focused agents come in; they handle the burden of equipping the agents with relevant prompts to solve a given workflow, so that you can just go in and use the application directly.
Another approach is to be specialized services that offer *context* to these agents. This is the space that we (@llama_index) are operating in. We are providing the infrastructure to parse the most complex documents into agent-ready context. For other companies it could be offering web data, sales data, documentation, or codebases as a service.
At a high-level any AI startup should provide context or workflows on top of these agents. We’re excited about building enduring tech even as the agent landscape evolves.
If you’re specifically excited to unlock the billions of context stored within your documents, come talk to us! https://t.co/Ht5jwxSrQB
Everybody’s talking about @openclaw, so @itsclelia decided to build her own crustacean AI assistant for document workflows: LobsterX 🦞
LobsterX is built on top of our Agent Workflows and leverages LlamaCloud for document parsing, structured data extraction, and classification via powerful, modular tools🛠️
Designed with a safety-first mindset, the agent runs on AgentFS (by @tursodatabase) to protect your real filesystem and intentionally avoids full shell access to prevent security-critical or destructive operations 🔒
It’s fully self-hostable, can be run as a uv tool or @Docker container, and works out of the box as a @telegram bot 💬
📦 Install: 𝘶𝘷 𝘵𝘰𝘰𝘭 𝘪𝘯𝘴𝘵𝘢𝘭𝘭 𝘭𝘰𝘣𝘴𝘵𝘦𝘳𝘹 --𝘱𝘳𝘦𝘳𝘦𝘭𝘦𝘢𝘴𝘦=𝘢𝘭𝘭𝘰𝘸
📚 Read more: https://t.co/DrAkucc0B2
🦙 Sign up to LlamaCloud: https://t.co/wZjhFV29gN
Are you trying to solve high-quality document ingestion for your product?
Gain lessons from the field on how @stackai uses LlamaCloud to power high-accuracy document ingestion & retrieval across PDFs, images, spreadsheets & more — at enterprise scale.
➡️ Register now: https://t.co/wc4hyDQxg8
The tech world went crazy for @openclaw, so I decided to build a similar crustacean agent called LobsterX🦞, with a focus on document-processing tasks.
I wrote a blog about it: https://t.co/x3ABScSQLC, but, as a tl;dr:
- LobsterX uses @llama_index cloud products to parse, extract structured data and classify files
- The agent has only access to a virtual filesystem (AgentFS by @tursodatabase) to avoid damaging your real one, and cannot execute arbitrary bash commands, preventing it from performing dangerous or security-critical operations🔒
- The agent is self-hostable and can be used both as a @Docker image and as a uv tool, and is available as a @telegram bot💬
📦 Install: 𝘶𝘷 𝘵𝘰𝘰𝘭 𝘪𝘯𝘴𝘵𝘢𝘭𝘭 𝘭𝘰𝘣𝘴𝘵𝘦𝘳𝘹 --𝘱𝘳𝘦𝘳𝘦𝘭𝘦𝘢𝘴𝘦=𝘢𝘭𝘭𝘰𝘸
📚 Read more: https://t.co/rg9sxOt9ey
📝 Read the blog: https://t.co/x3ABScSQLC
Ready to master production-grade multi-agent AI systems in one intensive day? 🚀
We're partnering with @AWS and leading AI companies for the AWS AI Builder Lab with @aicampai in San Francisco on Feb 13th - a hands-on competition where you'll build sophisticated agentic workflows, not basic chatbots.
🤖 Design and orchestrate powerful multi-agent workflows using cutting-edge tools
🏆 Compete in real-time challenges with live leaderboards and prizes for top performers
🔧 Get production-ready patterns you can implement immediately, plus enterprise tool trials
Coordinate intelligent systems to tackle real-world challenges. Limited to 250 qualified developers.
Register here: https://t.co/L33x2Q83sN
BREAKING: Tsunami activity forecast to hit San Francisco at 12:10.
If you are in a tsunami warning area, a tsunami with damaging waves and powerful currents is possible.
https://t.co/Dg76JvTfZp
New PMax questions answered from Think with Google...
From the first answer... Paraphrased - we won't show you the stats for channels within PMax because you might get the wrong idea about their performance if you actually see it. Trust us to always do what's best.
#PPCChat
let’s start out 2024 strong by committing to a career in Cybersecurity. @ISC2 is offering FREE entry-level Cybersecurity training and a FREE exam for you to become certified in Cybersecurity! Sign-up below! Learn more about One Million Certified in Cybersecurity at:
https://t.co/bHbTWxq1J5
*Once you become a certified member there is a $50 yearly membership fee that covers the continuing education credits you are required to earn.
#ad