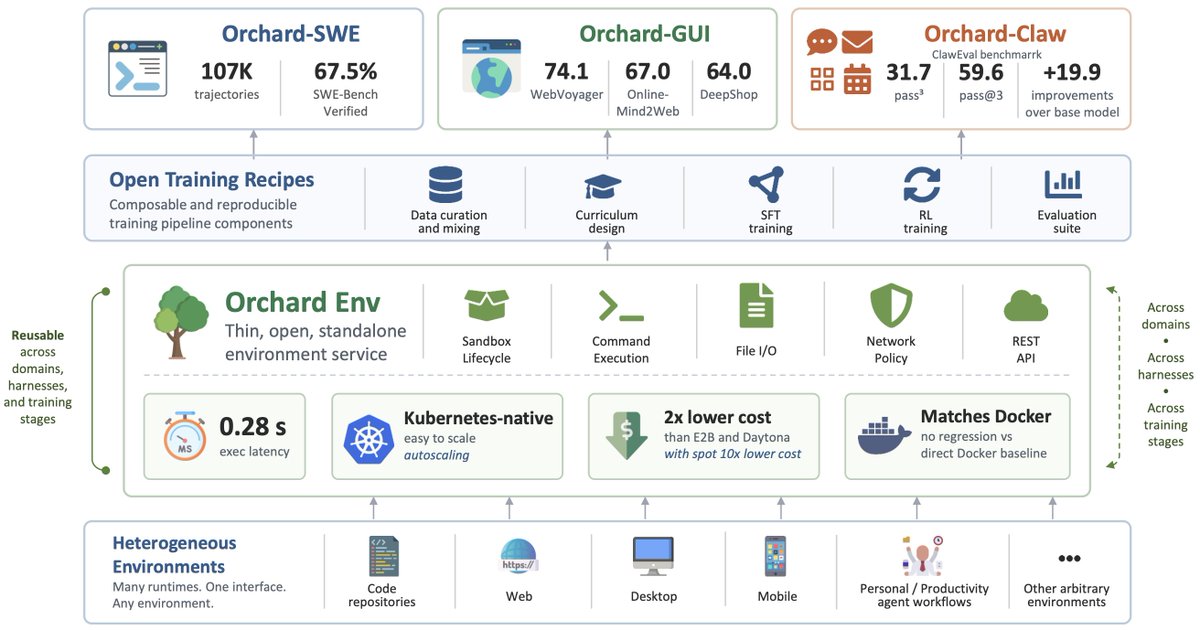
Excited to introduce WebHarbor! 🌟
⛑️Mirrors real sites into local Docker environments that are stable and RL-ready.
✅Ship with all 15 WebVoyager sites for reproducible and CAPTCHA-free evaluation.
📢Scaling to 100+ sites next, call for contributors!
Introducing WebHarbor ⚓ — an open community effort to dock real websites into local, deterministic, and evolving environments for web agent research. 🌐 Come help us build it. 🤝 Contribute new web environments or fix existing ones — will be included in the author list! ✍️
🎉 First release: 15 multimodal, high-fidelity environments covering all 643 WebVoyager tasks — full frontend, backend, database, and auth, all in one lightweight Docker image.
Why? Web agent eval today is broken😦: reCAPTCHA, geo-blocks, content drift, flaky networks, and login-gated deep features (e.g., account and checkout) that benchmarks can't touch. Live sites can't be reset either — making online agent RL impractical. Again, the bottleneck isn't the agent. It's the environment.
WebHarbor: dock real websites into stable, reproducible local mirrors with sub-second reset. But here's the key 🌱 — you can't clone the entire web upfront, and you don't need to. WebHarbor evolves with the agent: as harder tasks arrive, environments grow to support them. Coding agents (e.g., Claude Code/CodeX) build mirrors fast; human reviewers catch what coding agent hacks (shortcuts, leaks, fake completions).
We need you. 🙌 Help us scale to 100+ and beyond:
🔨 Contribute a new web environment
🐛 Fix or improve existing mirrors
🔍 Audit task fidelity & interaction realism
See more details and join the effort:
- 🏠 Project Page: https://t.co/TEVpIBDcLO
- 💻 GitHub Repo: https://t.co/DLEotmzG7h
- 📝 Contribution Form: https://t.co/HpQzDbWh7U
Let's build the open-source environment infrastructure for GUI web agents! ⚓
Initiating institutions: UNC-Chapel Hill ✖️Microsoft
#AIAgents #WebAgents #LLM #OpenSource #AgenticAI
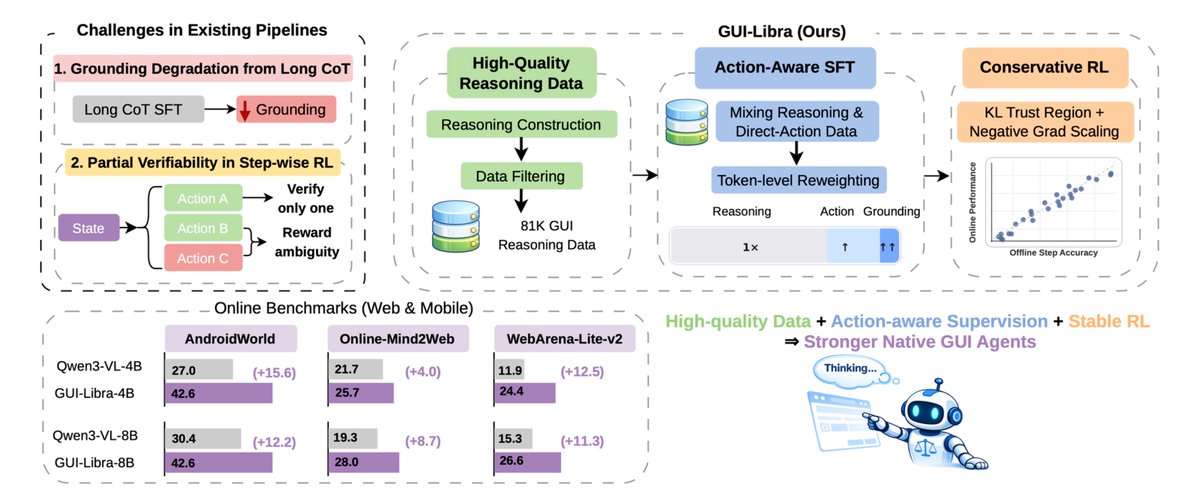
We've released the full package for GUI-Libra! 🌟
📂 Data/Model: https://t.co/SNA93dKvjN
📄 Paper: https://t.co/3ptHVsR0Rr
🌐 Project: https://t.co/7bQkdpWWPW
Happy to hear feedback from the community!
Collecting high-quality GUI trajectories for agent training is expensive. But are we fully leveraging the open-source data we already have? 🤔
✨Introducing GUI-Libra (https://t.co/OVFuSSecTX): 81K high-quality, action-aligned reasoning dataset curated from open-source corpora, plus a tailored training recipe that combines action-aware SFT with step-wise RLVR-style training (⚠️partially verifiable rather than fully verifiable!).
Result: stronger native GUI agents on both offline step-wise evaluation and online environments across mobile and web domains.
Take away: With careful data curation + tailored post-training recipe, a small subset of open-source trajectories can still go a long way for training native GUI agents.
Check out our paper (https://t.co/iwYIL95F6h) and code/dataset/model (https://t.co/41T3p8XKnK) for more details. #GUI #agent #VLM
Congrats to the LightMem team! 👏Great to see the continued exploration of topic-based segmentation and lightweight compression for building efficient memory systems for LLMs. Glad that our findings in SeCom and LLMLingua-2 have been useful building blocks for the community. 😀
We’re thrilled to share that our team’s work LightMem has been accepted to ICLR 2026 🎉
Paper: https://t.co/e7Zhk74fzh
Code: https://t.co/Mlyaxqf9KY
LightMem is a lightweight, modular memory system for LLM agents that enables scalable long-context reasoning and structured memory management across tasks and environments.
Recent updates:
1️⃣ Introduced a comprehensive baseline evaluation framework for benchmarking memory layers (Mem0, A-MEM, LangMem) across datasets like LoCoMo and LongMemEval
2️⃣ Released a demo video showcasing long-context handling, along with tutorial notebooks covering multiple usage scenarios
3️⃣ Enabled multi-tool invocation via MCP Server integration
4️⃣ Added full LoCoMo dataset support and integrated GLM-4.6, achieving strong performance and efficiency with reproducible scripts
5️⃣ Supported local deployment through Ollama, vLLM, and Transformers with automatic model loading
#ICLR2026 #LLM #Agents #MemorySystems #LightMem
🔊2026 Summer Internship @MSFTResearch Deep Learning Group🔊
We’re looking for a self-motivated intern with strong background on ⛑️building GUI agent environments and/or 🏗️reinforcement learning.
📩Interested? Send your CV + a short intro to [email protected]!
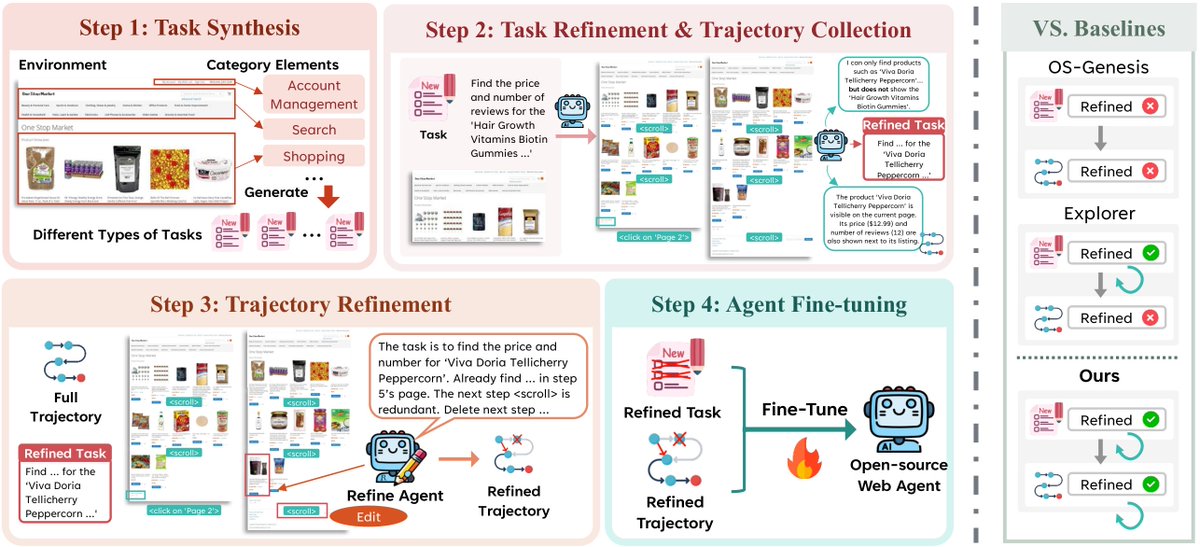
🧠 Key ideas: @zhaoywang_CS
• categorized task synthesis from real websites📷
• online task refinement when the task is against observation 📷
• offline trajectory refinement to remove noisy steps 🪄
🚀 New work: SynthAgent – a fully synthetic supervision pipeline for web agents 🤖
We generate high quality and environment-specific tasks + trajectories to adapt agents to new websites without human efforts 🧠🧼
arxiv:https://t.co/6cWiMMghW7
code:https://t.co/fYPwViPXHd
Why can (V)LMs agents ace coding and math, yet struggle so badly in more complex environments like computer or phone use? 🤔
We find that one key factor lies in models' ability to understand and *simulate* the environment’s dynamics — and propose **Dyna-Mind** to address this!
🧵[1/n]
✨ Internship Opportunity @ Google Research ✨
We are seeking a self-motivated student researcher to join our team at Google Research starting around January 2026. 🚀 In this role, you will contribute to research projects advancing agentic LLMs through tool use and RL, with the goal of enabling breakthrough applications.
We are particularly interested in PhD students with a strong background in these areas. If interested, please send a brief self-introduction and your CV to [email protected]. Looking forward to connecting with talented researchers in this exciting space!
@LiJunnan0409 Awesome work! 🥂 I feel like the design of our GUI-Actor — which can propose multiple candidate regions in one forward pass— combined with a Grounding Verifier could work really well within the 'test-time scaling' framework of GTA1! 😀
Huge thanks to the @SimularAI team for hosting, and to my amazing collaborators for making this project possible! 🙏 Excited to see where this direction takes us next!
🔗 https://t.co/h7NRbvHR5D
Big thanks to Qianhui Wu @5000hui and the team behind “Act Where You See” for sharing their amazing work this week at @SimularAI Seminar! 🧠⚡️
Coordinate-free visual grounding for GUI agents is a huge leap toward human-like interaction.
📎 https://t.co/oRX7zvYLDY
#AI #SimularSeminar #GUIAgents #SimularToHuman
🚀 Excited to share GUI-Actor—a new approach for GUI grounding! Big thanks to @_akhaliq for featuring our work!
🌐 Project page: https://t.co/nHAq2tWp6q
📜 Paper: https://t.co/LRzQwJkccu
🤔 What's limiting coordinate generation-based GUI grounding?
1️⃣ Weak spatial-semantic alignment
2️⃣ Ambiguous supervision signals
3️⃣ Vision–action granularity mismatch
👀 But think about it: humans don’t calculate precise screen coordinates—we perceive elements and then act directly.
💡 Meet GUI-Actor: a VLM with an attention-based action head that:
✅ Addresses above limitations
✅ Proposes multiple candidate regions in one pass, enabling flexible downstream strategies.
✅ Performs coordinate-free grounding that better mirrors human behavior
➕ We also introduce a grounding verifier to select the most plausible action region — and it can boost other grounding methods too.
🎯 Results? GUI-Actor achieves SOTA on several benchmarks, even GUI-Actor-7B outperforms UI-TARS-72B on ScreenSpot-Pro, all using the same Qwen2-VL backbone.
🚀 Excited to announce our 4th Workshop on Computer Vision in the Wild (CVinW) at @CVPR 2025!
🔗 https://t.co/BolazSxgTb
⭐We have invinted a great lineup of speakers: Prof. Kaiming He, Prof. @BoqingGo, Prof. @CordeliaSchmid, Prof. @RanjayKrishna, Prof. @sainingxie, Prof. @YunzhuLiYZ, Prof. @furongh to talk about the exciting researches to bring vision to the wild!
🌎Join top researchers tackling real-world vision challenges — from dynamic environments to embodied agents! See you all at #CVPR2025!
#CVPR2025 #ComputerVision #AI
In this issue of Research Focus, we examine a new conversation segmentation method that delivers more coherent and personalized agent conversation, and we review efforts to improve MLLMs’ understanding of geologic maps. Check out the latest research: https://t.co/XuYK1ChxBg
🚀 Excited to introduce our latest work: Magma - A Foundation Model for Multimodal AI Agents! 🔥
🌐 Project: https://t.co/UgqapTmoOM
📄 Paper: https://t.co/ydIM2wHuGl
Check it out and let us know what you think! #AIAgents#Multimodal
Thanks for featuring our work! @arankomatsuzaki.
🔥Today we are thrilled to announce our MSR flagship project Magma! This is a fully open-sourced project. We will roll out all the stuff: code, model and training data through the following days. Check out our full work here: https://t.co/GL22DQYqLA !
To the best of our knowledge, Magma is the first-ever foundation model for multimodal AI agents designed to handle complex interactions for agentic tasks. With a single suite of parameters, Magma achieves state-of-the-art UI navigation and robotics manipulation across both digital and physical environments, as well as excelling on generic image and video understandings!
Thrilled to share that RegMix has been accepted by #ICLR2025! 🎉 Massive shoutout to the incredible co-authors @xszheng2020@Muennighoff@GuangtaoZ@LongxuDou@TianyuPang1 Jing Jiang @mavenlin!
🙏 Huge thanks to ICLR reviewers for helping us improve RegMix! 🌟 some key Improvements from v1 :
1️⃣ Expanded experiments to 100 domains, and Regression still works extremely well 📈
2️⃣ Conducted 7B model performance over 100B tokens and RegMix beats Human consistently🚀
3️⃣ More results on the confirmation of the rank invariance hypothesis across model scales 📉
4️⃣ New insights at using 1B proxy model level, and it does not show significant advantage than 1M proxy models actually🧠
Code: https://t.co/xqJ8FUNWjf
Paper: https://t.co/KcRhKvQsYa






























![xy2437's tweet photo. Why can (V)LMs agents ace coding and math, yet struggle so badly in more complex environments like computer or phone use? 🤔
We find that one key factor lies in models' ability to understand and *simulate* the environment’s dynamics — and propose **Dyna-Mind** to address this!
🧵[1/n]](https://pbs.twimg.com/media/G3Qu2QsW4AEYcYl.png)
























