Excited to introduce WebHarbor! 🌟
⛑️Mirrors real sites into local Docker environments that are stable and RL-ready.
✅Ship with all 15 WebVoyager sites for reproducible and CAPTCHA-free evaluation.
📢Scaling to 100+ sites next, call for contributors!
Congrats to the LightMem team! 👏Great to see the continued exploration of topic-based segmentation and lightweight compression for building efficient memory systems for LLMs. Glad that our findings in SeCom and LLMLingua-2 have been useful building blocks for the community. 😀
We've released the full package for GUI-Libra! 🌟
📂 Data/Model: https://t.co/SNA93dKvjN
📄 Paper: https://t.co/3ptHVsR0Rr
🌐 Project: https://t.co/7bQkdpWWPW
Happy to hear feedback from the community!
🔊2026 Summer Internship @MSFTResearch Deep Learning Group🔊
We’re looking for a self-motivated intern with strong background on ⛑️building GUI agent environments and/or 🏗️reinforcement learning.
📩Interested? Send your CV + a short intro to [email protected]!
I’ll be at NeurIPS this Friday! You can catch me at the Google booth from 9:30–10:30 AM for the Q&A session with the Gemini team. Later in the afternoon, I’ll be presenting our SCONE paper (https://t.co/SndiFct6Gb) from 4:30–6:00 PM at Exhibit Hall C,D,E #5315. I'm looking forward to seeing familiar faces and meeting some new ones!
We'll be doing two different Q&A sessions at #NeurIPS2025 w/members of the Gemini team (including me). One is on Thurs., 2:30 to 3:30 PM and the other is Fri., 9:30 to 10:30 AM. Both at the @Google booth. Looking forward to talking about Gemini 3 ♊, Nano Banana 🍌, and more!
I’m really excited about our release of Gemini 3 today, the result of hard work by many, many people in the Gemini team and all across Google! 🎊
We’ve built many exciting new product experiences with it, as you’ll see today and in the coming weeks and months.
You can find it today on @GeminiApp and AI Mode in Search. For developers, you can build with it now in @GoogleAIStudio and Vertex AI.
https://t.co/KRV0xzniBY
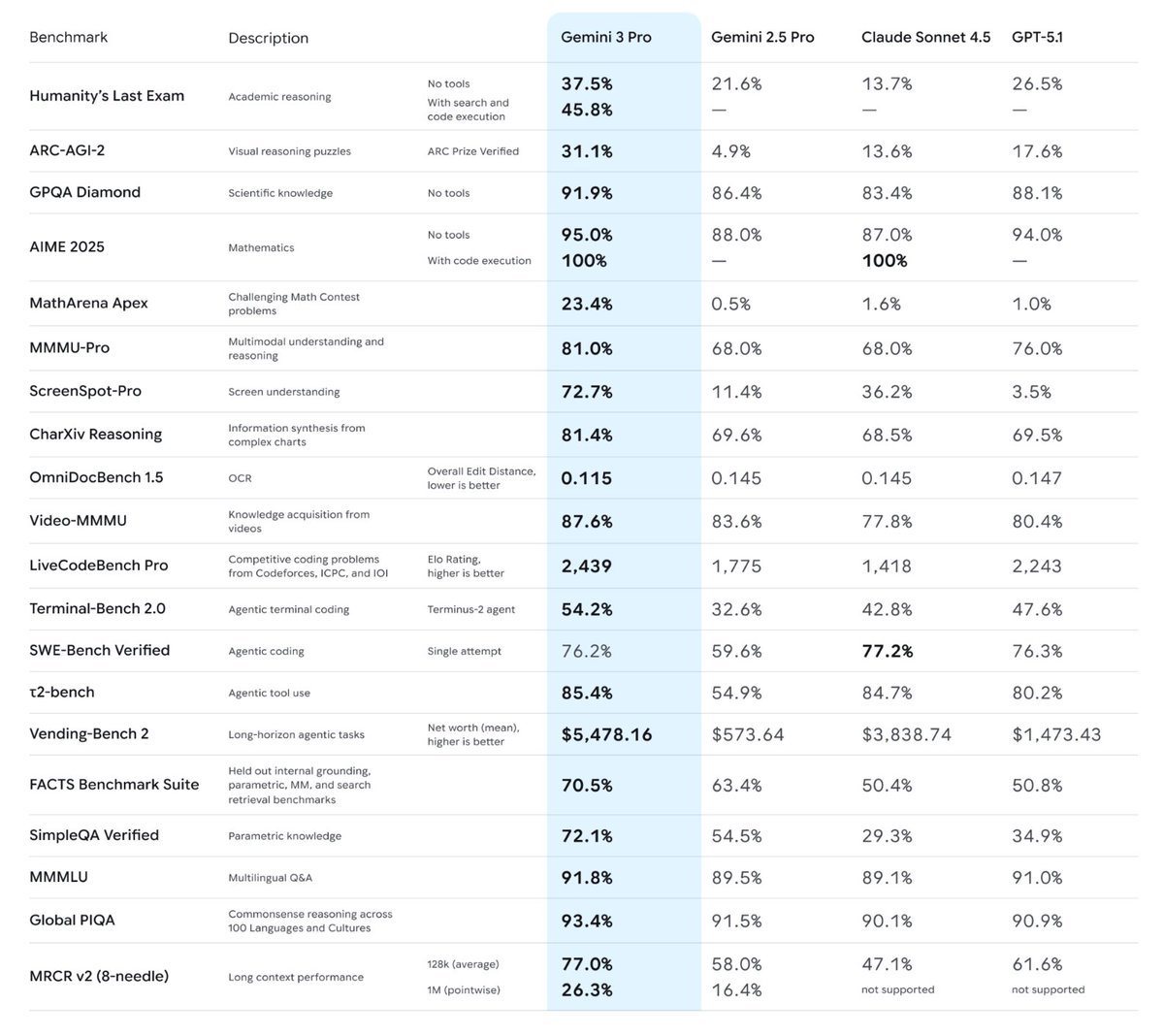
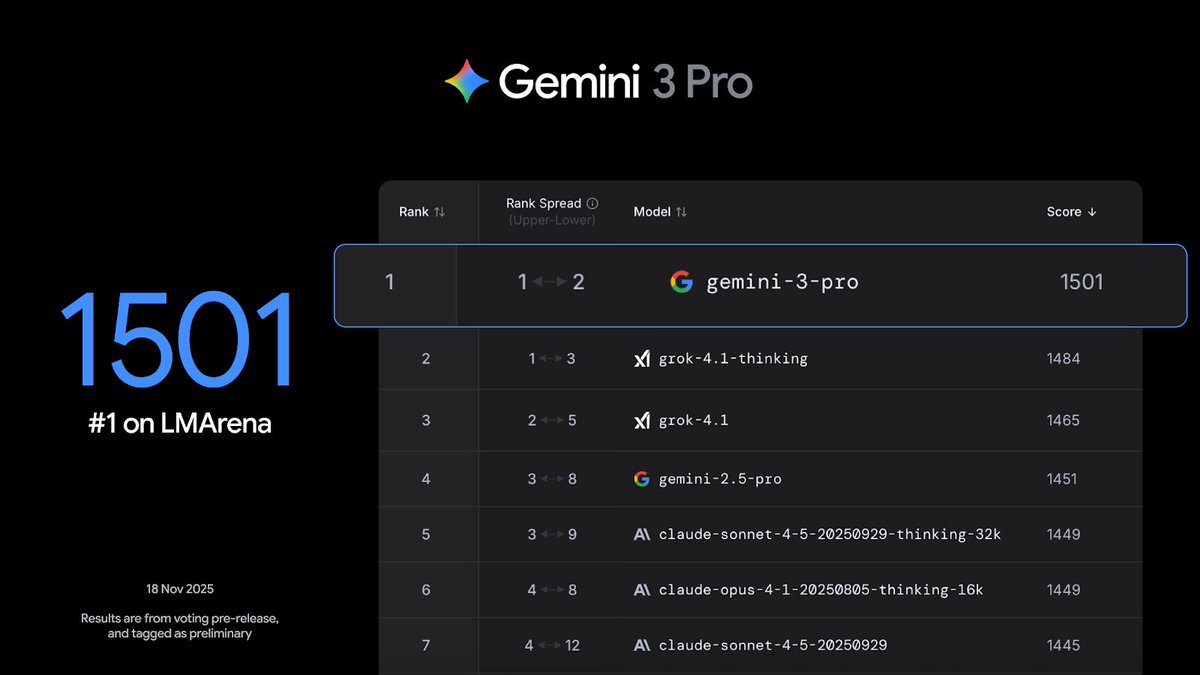
The model performs quite well on a wide range of benchmarks.
We’ve been intensely cooking Gemini 3 for a while now, and we’re so excited and proud to share the results with you all. Of course it tops the leaderboards, including @arena, HLE, GPQA etc, but beyond the benchmarks it’s been by far my favourite model to use for its style and depth, and what it can do to help with everyday tasks.
We are truly grateful for your interest in this position! Our team will carefully review each application, but as we’ve received many more applications than expected, we may not be able to respond individually.
✨ Internship Opportunity @ Google Research ✨
We are seeking a self-motivated student researcher to join our team at Google Research starting around January 2026. 🚀 In this role, you will contribute to research projects advancing agentic LLMs through tool use and RL, with the goal of enabling breakthrough applications.
We are particularly interested in PhD students with a strong background in these areas. If interested, please send a brief self-introduction and your CV to [email protected]. Looking forward to connecting with talented researchers in this exciting space!
@soul_surfer78 Thank you for your question. We are primarily looking for PhD students, but we are also open to exceptional master/undergraduate candidates.
@shreyas1007 Thank you for your question. We are primarily looking for PhD students, but we are also open to exceptional master/undergraduate candidates.
🚀 Excited to share GUI-Actor—a new approach for GUI grounding! Big thanks to @_akhaliq for featuring our work!
🌐 Project page: https://t.co/nHAq2tWp6q
📜 Paper: https://t.co/LRzQwJkccu
🤔 What's limiting coordinate generation-based GUI grounding?
1️⃣ Weak spatial-semantic alignment
2️⃣ Ambiguous supervision signals
3️⃣ Vision–action granularity mismatch
👀 But think about it: humans don’t calculate precise screen coordinates—we perceive elements and then act directly.
💡 Meet GUI-Actor: a VLM with an attention-based action head that:
✅ Addresses above limitations
✅ Proposes multiple candidate regions in one pass, enabling flexible downstream strategies.
✅ Performs coordinate-free grounding that better mirrors human behavior
➕ We also introduce a grounding verifier to select the most plausible action region — and it can boost other grounding methods too.
🎯 Results? GUI-Actor achieves SOTA on several benchmarks, even GUI-Actor-7B outperforms UI-TARS-72B on ScreenSpot-Pro, all using the same Qwen2-VL backbone.