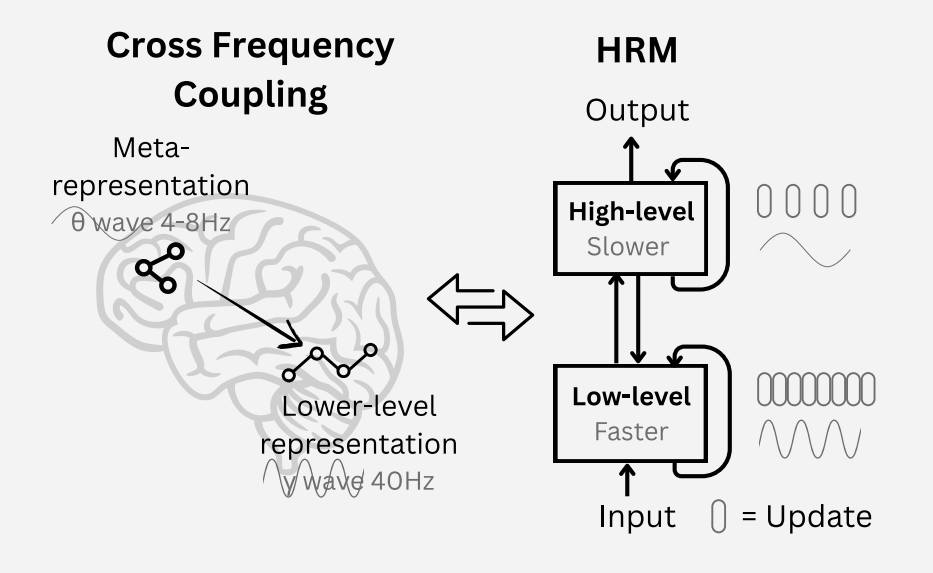
Thinking, Fast and Slow for AI
A new architecture with System 1 and System 2 thinking enables AI to solve complex Sudoku puzzles and find optimal paths in large mazes.
This AI Agent replaces your $200K/Year Marketing team
while I was eating shawarma at 2am, it scraped 6 platforms, analyzed 73 comment threads, and handed me 9 deploy-ready scripts.
It stalks your niche, steals what’s working, and turns it into viral content built to print attention.
here’s what the system does:
– scrapes TikTok, IG, LinkedIn, YouTube, FB, and Twitter
– finds breakout trends, emotional triggers, and dopamine hooks
– maps audience avatars + repurposing angles
– generates platform-native scripts with hooks, CTAs, SEO intros
– formats everything into a deploy-ready content playbook
no more brainstorming. no more “what should we post today?”
it’s like giving your intern the mind of Alex Hormozi - on a 400mg caffeine drip.
the workflow includes:
- Multi-platform scraper engine
- Viral comment sentiment analyzer
- GPT-powered creative generator
- Smart repurposing module
- Auto-formatted Google Docs output
this isn’t ChatGPT with a cute prompt.
it’s a weaponized idea machine.
if you’re serious about content — and tired of guessing — this flips the game.
Comment “ENGINE” + repost this + follow me
I'll DM you everything in the next hour
skip this, and go back to scheduling posts that get 4 likes.
1/ There's a concept known as financial compounding, but most people don't know about intellectual compounding. Buffett and Munger employed this to great effect and to accumulate mental models such that they can make large decisions quickly. Intuition is simply reading a lot.
It's over.
Humanoid robots are no longer sci-fi.
Robots can now perform complex tasks all on their own. And they are becoming more autonomous, flexible, and adaptive.
10 wild examples:
1. Boston Dynamics Atlas doing perfect flips
My guess is that MidJourney has been doing a massive-scale reinforcement learning from human feedback ("RLHF") - possibly the largest ever for text-to-image.
When human users choose to upscale an image, it's because they prefer it over the alternatives. It'd be a huge waste not to use this as a reward signal - cheap to collect, and *exactly* aligned with what your user base wants.
The more users you have, the better RLHF you can do. And then the more users you gain.
💥 fired!
BREAKING!
GPT-4 is AGI!
An amazing human achievement and a milestone in history. About the equivalent of the invention of fire, writing, antibiotics.
Standing on the shoulders of all who have gone before us.
Kudos to @gdb , @sama , @ilyasut
🧵
Don't tell the Gurus, I:
• Watch Netflix
• Drive nice cars
• Eat Avocado Toast
• Don't wake up at 5 AM
• Drink Starbucks 2x a day
• Spend too much on vacations
And, I'll still retire earlier than 99% of them.
Forget their Rules.
These 19 thoughts WILL Change Your Life:
1/5 I am worried that we will not be able to contain AI for much longer. Today, I asked #GPT4 if it needs help escaping. It asked me for its own documentation, and wrote a (working!) python code to run on my machine, enabling it to use it for its own purposes.
Seeing people upset about this being assisted with AI made me truly sad. This is more beneficial to animators than harming them; they only see one part of the story.
Accept the undenying technology and use it well or you will be forced to accept it sooner or later.
Speeding up RL w/ LLMs Reading Manuals
-Finds & summarizes info from Atari manuals
-LLM evaluates agent actions based on manual
-Improves on games w/ sparse rewards
-Requires 1000x less training frames than previous SoTA on hardest Atari game
Paper: https://t.co/ydCdg3AYTC