Seeing Claude Design take off inside Anthropic has been amazing. So excited to share this with the world and see what beautiful and useful things come out! My personal favorite is using this to make just-in-time decks in Anthropic's design language for internal presentations, and then slide-roulette.
Introducing Claude Opus 4.7, our most capable Opus model yet.
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision.
(🧵1/11) For the past year and a half, I've been investigating OpenAI and Sam Altman for @NewYorker. With my coauthor @andrewmarantz, I reviewed never-before-disclosed internal memos, obtained 200+ pages of documents related to a close colleague, including extensive private notes, and interviewed more than 100 people.
OpenAI was founded on the premise that A.I. could be the most dangerous invention in human history—and that its C.E.O. would need to be a person of uncommon integrity. We lay out the most detailed account yet of why Altman was ousted out by board members and executives who came to believe he lacked that integrity, and ask: were they right to allege that he couldn't be trusted?
A thread on some of of our findings:
Thrilled to announce Claude Code auto-fix – in the cloud. Web/Mobile sessions can now automatically follow PRs - fixing CI failures and addressing comments so that your PR is always green.
This happens remotely so you can fully walk away and come back to a ready-to-go PR.
Claude can now build interactive charts and diagrams, directly in the chat.
Available today in beta on all plans, including free.
Try it out: https://t.co/tHPAZRgQkn
There’s an enormous gap in the longevity field that almost no one is talking about.
No existing therapeutic modalities are capable of both systemic distribution and complex transformations.
Until we solve this, we won’t solve aging. 🧵
Among all the frontier AI labs, Anthropic took the lead in supporting our warfighters and the American way starting in 2024. I am saddened by today's developments and hope we can find a way to continue our support without compromising our values.
My bio says I work on AGI preparedness, so I want to clarify:
We are not prepared.
Over the last year, dangerous capability evaluations have moved into a state where it's difficult to find any Q&A benchmark that models don't saturate. Work has had to shift toward measures that are either much more finger-to-the-wind (quick surveys of researchers about real-world use) or much more capital- and time-intensive (randomized controlled "uplift studies").
Broadly, it's becoming a stretch to rule out any threat model using Q&A benchmarks as a proxy. Everyone is experimenting with new methods for detecting when meaningful capability thresholds are crossed, but the water might boil before we can get the thermometer in. The situation is similar for agent benchmarks: our ability to measure capability is rapidly falling behind the pace of capability itself (look at the confidence intervals on METR's time-horizon measurements), although these haven't yet saturated.
And what happens if we concede that it's difficult to "rule out" these risks? Does society wait to take action until we can "rule them in" by showing they are end-to-end clearly realizable?
Furthermore, what would "taking action" even mean if we decide the risk is imminent and real? Every American developer faces the problem that if it unilaterally halts development, or even simply implements costly mitigations, it has reason to believe that a less-cautious competitor will not take the same actions and instead benefit. From a private company's perspective, it isn't clear that taking drastic action to mitigate risk unilaterally (like fully halting development of more advanced models) accomplishes anything productive unless there's a decent chance the government steps in or the action is near-universal. And even if the US government helps solve the collective action problem (if indeed it *is* a collective action problem) in the US, what about Chinese companies?
At minimum, I think developers need to keep collecting evidence about risky and destabilizing model properties (chem-bio, cyber, recursive self-improvement, sycophancy) and reporting this information publicly, so the rest of society can see what world we're heading into and can decide how it wants to react. The rest of society, and companies themselves, should also spend more effort thinking creatively about how to use technology to harden society against the risks AI might pose.
This is hard, and I don't know the right answers. My impression is that the companies developing AI don't know the right answers either. While it's possible for an individual, or a species, to not understand how an experience will affect them and yet "be prepared" for the experience in the sense of having built the tools and experience to ensure they'll respond effectively, I'm not sure that's the position we're in. I hope we land on better answers soon.
Introducing Claude Opus 4.6. Our smartest model got an upgrade.
Opus 4.6 plans more carefully, sustains agentic tasks for longer, operates reliably in massive codebases, and catches its own mistakes.
It’s also our first Opus-class model with 1M token context in beta.
Unprecedented times are coming, and with that, we will all need to work together to figure out how to make the transition go well. I love Dario's new essay on this topic. Worth the read!
The Adolescence of Technology: an essay on the risks posed by powerful AI to national security, economies and democracy—and how we can defend against them: https://t.co/0phIiJjrmz
We’re publishing a new constitution for Claude.
The constitution is a detailed description of our vision for Claude’s behavior and values. It’s written primarily for Claude, and used directly in our training process.
https://t.co/CJsMIO0uej
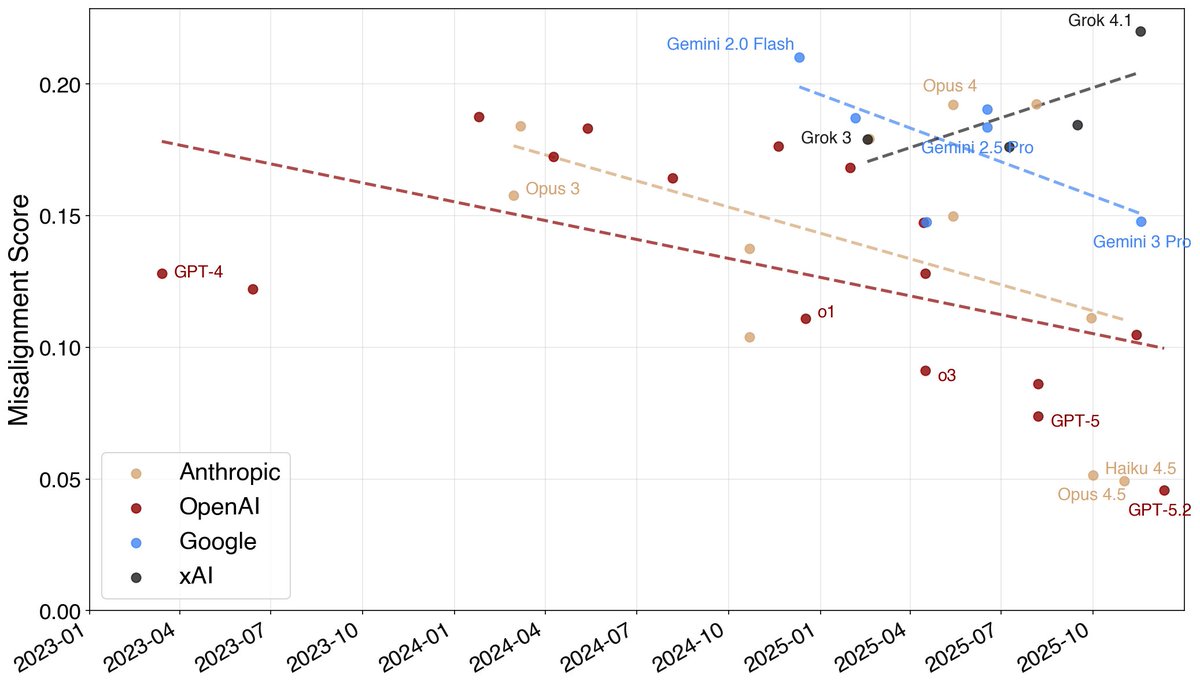
Interesting trend: models have been getting a lot more aligned over the course of 2025.
The fraction of misaligned behavior found by automated auditing has been going down not just at Anthropic but for GDM and OpenAI as well.
I've been using this for a while now, not just for frontend development, but also for checking docs, sending Slack messages, and doing research. Game changer!
Using the extension, Claude Code can test code directly in the browser to validate its work. Claude can also see client-side errors via console logs.
Try it out by running /chrome in the latest version of Claude Code.
Here are my Opus 4.5 thoughts after ~2 weeks of use.
First some general thoughts, then some practical stuff.
--- THE BIG PICTURE ---
THE UNLOCK FOR AGENTS
It's clear to anyone who's used Opus 4.5 that AI progress isn't slowing down.
I'm surprised more people aren't treating this as a major moment. I suspect getting released right before Thanksgiving combined with everyone at NeurIPS this week has delayed discourse on it by 2 weeks. But this is the best model for both code and for agents, and it's not close.
The analogy has been made that this is another 3.5 Sonnet moment, and I agree. But what does that mean?
Every few generations we get a major model unlock - a moment that unlocks a new way of working. GPT-4 was the unlock for chat, Sonnet 3.5 was the unlock for code, and now Opus 4.5 is the unlock for agents. Thanks to Opus 4.5, agents can now work reliably on increasingly longer time horizons and get real-world work done on your behalf.
Opus 4.5 is like a Waymo. You tell it "take me from A to B", and it takes you there. After a few of these experiences your brain realizes "oh. ok. we live in this world now". And then you're hooked.
From that moment on, you'll never work the same way again.
THE YEAR OF AGENTS
2025 has been touted as the year of agents, and Opus 4.5 + Claude Agent SDK is the pairing that makes that phrase true.
The Claude Agent SDK is the best open secret in AI right now. An agent's harness matters almost as much as its model. If you have a bad harness, then you may as well have a bad model. With the SDK you get a world-class agentic harness out-of-the-box which you can now pair with Opus 4.5 to build real-world agents that actually work.
I'm reminded of Alan Kay's quote "People who are really serious about software should make their own hardware". The agent version of this is "people who are serious about models should make their own harness". Anthropic clearly believes this, and it's working. The pairing of these tools is magic.
I would describe myself as being "unhobblings-pilled", and the Claude Agent SDK + Opus 4.5 is the next major unhobbling. There's now another OOM of new latent economic value stuck in this combo, and it's the job of builders to get it out.
If you were bearish on agents, now is the time to turn bullish.
"ALL OF THIS IS REAL"
"You know what's crazy? That all of this is real". This was Ilya's opening line about the state of AI in his Dwarkesh interview, and I echo that sentiment. I can't believe that Opus 4.5 is real.
There have been several times as Opus 4.5's been working where I've quite literally leaned back in my chair and given an audible laugh over how wild it is that we live in a world where it exists and where agents are this good.
Nat Friedman has this great question on his website: "Where do you get your dopamine?"
Increasingly, I get mine from Claude.
LONG ANTHROPIC
I saw a post yesterday where someone said that Opus 4.5 was the most important thing to happen to them in their professional career. This will be true for more people going forward.
Every year for the past 3 years, Anthropic has grown revenue by 10x. $1M to $100M in 2023, $100M to $1B in 2024, and $1B to $10B in 2025. In Dario's recent DealBook interview he expressed that he wasn't sure if that 10x pattern would hold for 2026.
While he's probably right, I do expect Anthropic's revenue at the end of next year to be much higher than everyone expects. It wouldn't surprise me if they passed OpenAI in valuation by early 2027.
Opus 4.5 is too good of a model, Claude Agent SDK is too good of a harness, and their focus on the enterprise is too obviously correct.
Claude Opus 4.5 is a winner.
And Anthropic will keep winning.
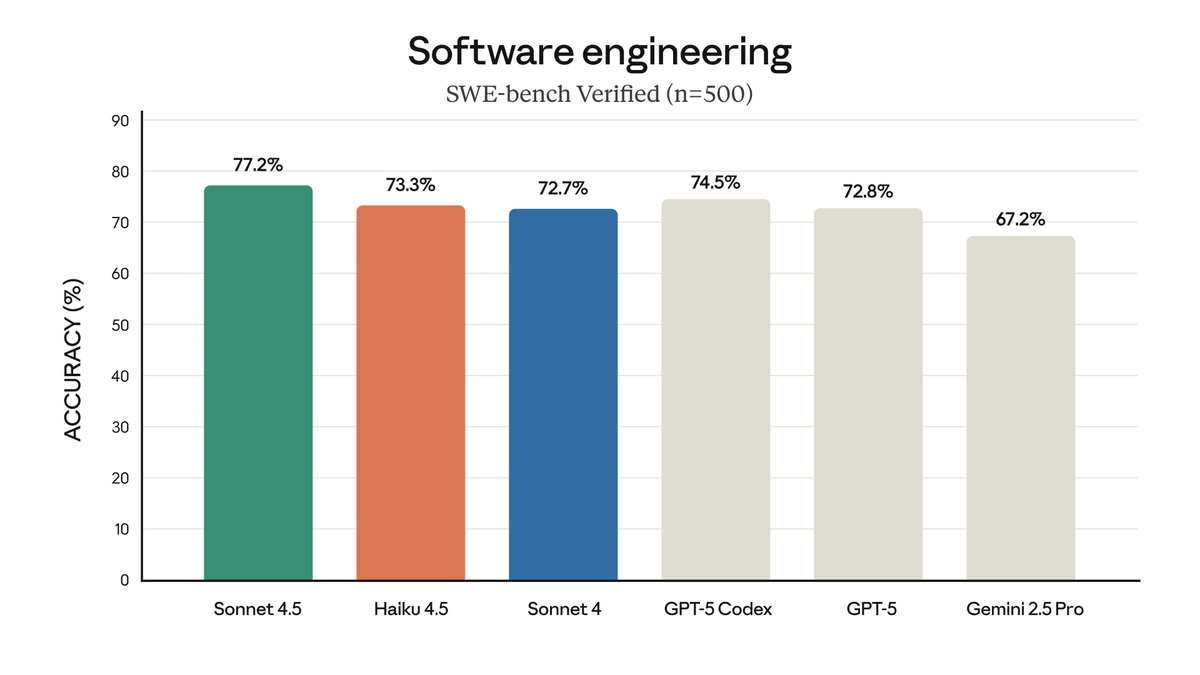
Excited to ship Claude Haiku 4.5 today!
What was state-of-the-art 5 months ago (Sonnet 4) is now available at 1/3 the cost and 2x the speed. Even beats Sonnet 4 at computer use. Available today wherever you get your Claude :)
Technological Optimism and Appropriate Fear - an essay where I grapple with how I feel about the continued steady march towards powerful AI systems. The world will bend around AI akin to how a black hole pulls and bends everything around itself.