@sheriyuo Nice work! cool to see the field converging, we posted a related TRB angle just before, via rollout-behavior blending: https://t.co/ButztdPeoF
[1/7] OPD has a simple post-training loop: sample from the student, label with the teacher, repeat.
The awkward part is the start. The first rollouts come from the weakest version of the student, and training begins there.
TRB Paper: https://t.co/EPjiHZIE3s
@amit_1992 Fair. We don’t derive a universal teacher-size cutoff. Appendix C makes the tradeoff explicit: TRB adds co-residency (~teacher weights + KV) and swaps batched teacher scoring for online decoding. Break-even is hardware/batching/warmup-fraction dependent.
[1/7] OPD has a simple post-training loop: sample from the student, label with the teacher, repeat.
The awkward part is the start. The first rollouts come from the weakest version of the student, and training begins there.
TRB Paper: https://t.co/EPjiHZIE3s
[6/7] The diagnostics match that story.
During warmup, TRB reaches prefixes where the teacher's token-mean entropy is lower. After warmup, the distribution mostly matches vanilla OPD, but the benchmark curve stays higher.
The gain seems to come from the warm start.
@icmlconf ESSA #23562 was rejected, but the decision says “the paper’s strengths outweigh its weaknesses.” Reviewers raised scores after rebuttal; requested additions read like camera-ready changes. Possible inconsistency?
The biggest threat to the #ICML2026 AC discussion phase is these issues with Claude. I feel like the gap between the A and B cohorts in reviewing will become even larger, and the whole conference is going to be filled with LLM slop. The research we deserved.
🚀I built an interactive game to learn Claude Code extensions.
🙏 Built on top of @official_taches's excellent resource list: https://t.co/Kg6EdI1xGs
Try it: https://t.co/vz32hgHaJC
Source: https://t.co/SpTvzXLuI9
Happy to announce that our paper “Enhancing Vision-Language Model Training with Reinforcement Learning in Synthetic Worlds for Real-World Success” has been accepted to #AAMAS 🎉
We introduce VL-DAC, a framework that leverages synthetic environments + RL to improve real-world VLM performance.
🔧 Code: https://t.co/c9gX65o9Gn
🌐 Project page: https://t.co/iE9IassabN
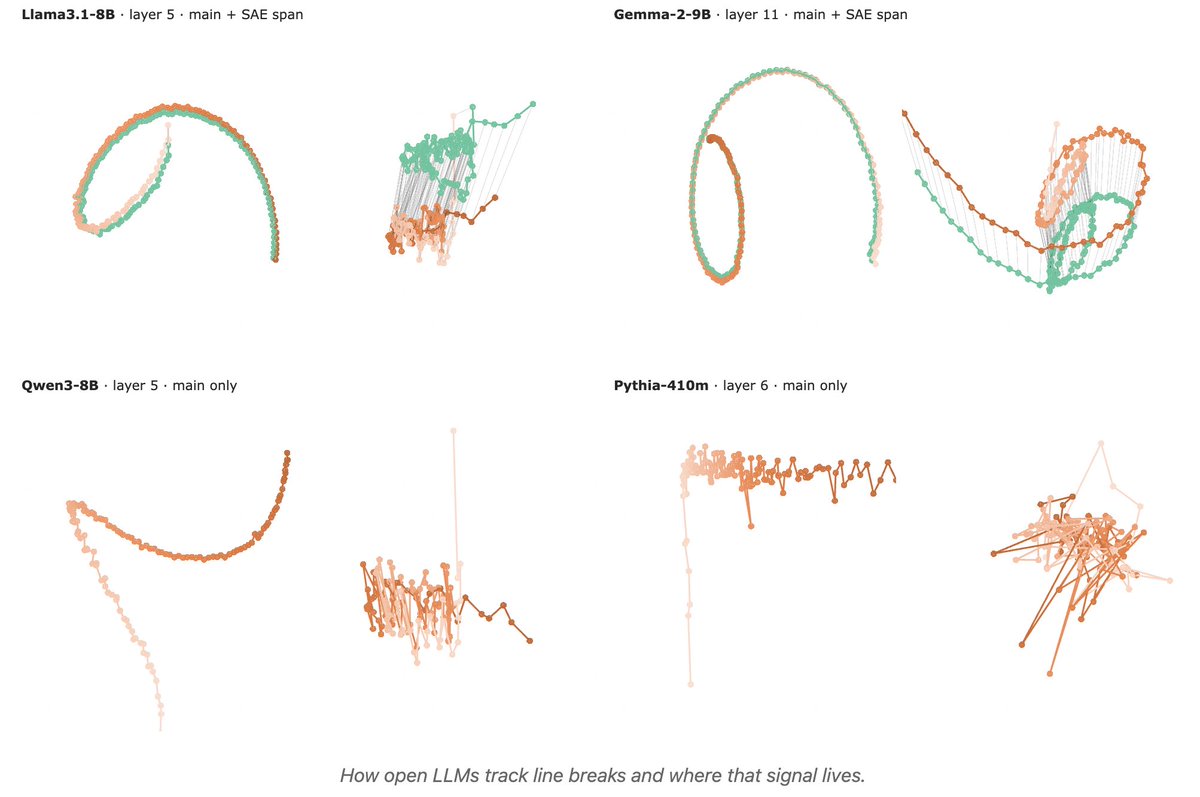
1/ 🧵 Reproducing Anthropic’s “counting manifold” result in open-weight LLMs: do they internally track “chars since last \n” to wrap text consistently?
https://t.co/me60hJfrxN
@HuggingPapers Appreciate the feature! I posted a short thread with 3 GIFs explaining the tail-miss mechanism + why risk peaks at intermediate N, and the 1-line fix (F-GRPO).
[1/8] RL with verifiable rewards often boosts pass@1 but hurts pass@256. In group-relative RL with binary rewards, this isn’t “mysterious collapse” — it’s a sampling effect. We analyze why + propose a 1-line fix: F-GRPO (focal weighting).
Paper: https://t.co/vEcKfJ9RKF
[7/8] Efficiency: F-GRPO at N=8 matches GRPO at N=32 on diversity with 4× fewer rollouts:
math pass@256: 70.3 vs 70.1
OOD pass@256: 63.3 vs 61.7
Also works as F-DAPO and F-CISPO (consistent pass@256 gains).






![AMyashka's tweet photo. [6/7] The diagnostics match that story.
During warmup, TRB reaches prefixes where the teacher's token-mean entropy is lower. After warmup, the distribution mostly matches vanilla OPD, but the benchmark curve stays higher.
The gain seems to come from the warm start. https://t.co/dAgu4ofzA0](https://pbs.twimg.com/media/HJutLd8XQAAXwzz.png)