Electrical and Computer Engineer.
Intelligent Systems and Robotics Specialist (Computer Vision Research)
AI Innovation Fellow @Intel
Technical Member @ACM
$15K/month in compute. Direct mentorship from Anthropic researchers. And they pay you $3,850/week to do it.
Anthropic (@AnthropicAI) opened their Fellows Program:
- 4 months, full-time AI research
- $3,850/week stipend ($15.4K/mo)
- $15K/mo in compute credits
- mentorship from Anthropic’s team
- AI Safety, Security, ML, RL, Economics
- CA, London, or remote (US/UK/CA)
- 25%+ fellows received full-time offers
Rolling applications. Next cohort starts September.
→ https://t.co/Q7so4Bce5e
🚨Paid Research Fellowship alert: MicroAGI just launched a paid 6-month Research Fellowship in Munich or Zurich and it looks like an incredible opportunity in physical AI. Here’s what fellows get:$10K/month stipend
Up to $2M in compute
🚨Anthropic just showed a 24-minute workshop on how to actually do prompts for Claude.
Taught by the people who built it.
Free. No registration. No paywall.
I've seen $300 courses that don't cover what they teach in the first 8 minutes.
Watch it and bookmark it now!
Andrej Karpathy just explained the future of software engineering without directly saying it.
The best AI engineers are no longer “prompting.”
They’re building systems around the agents.
Karpathy’s biggest insight wasn’t:
“Claude can code.”
It was:
LLMs become dramatically better when you force them into disciplined workflows.
That’s why "CLAUDE.md" files are suddenly everywhere.
Not because they’re prompts.
Because they behave like an operating system for the agent.
Karpathy called out the exact problems with AI coding:
- models assume instead of asking
- they overengineer simple tasks
- they hide confusion
- they rewrite unrelated code
- they optimize for completion, not correctness
So developers started encoding rules directly into the workflow:
→ Think before coding
→ Simplicity first
→ Surgical edits only
→ Goal-driven execution
And the results are wild.
People are now running multiple Claude Code agents in parallel like engineering teams:
• one agent researching
• one debugging
• one writing tests
• one optimizing code
• one validating outputs
Not “AI assistance.”
Actual orchestration.
And this part from Karpathy changes everything:
“Don’t tell the model what to do. Give it success criteria and let it loop.”
That is the shift.
From:
“write this function”
To:
“here’s the goal, constraints, tests, and verification system — now iterate until correct.”
The craziest part?
This already feels like a phase shift in engineering.
A lot of developers quietly went from:
80% manual coding → to 80% agent-driven coding in just months.
Not because AI became perfect.
Because the leverage became impossible to ignore.
We’re entering an era where the highest leverage engineers won’t necessarily be the best coders.
They’ll be the people who build the best systems around AI agents.
🚀 Hiring: Research Scientists at FAIR, Meta 🚀
We’re looking for strong candidates with expertise in post-training, reinforcement learning, or self-improvement methods for image and video generation.
If you’re passionate about advancing generative AI, please apply:
https://t.co/ytqAbzQ2CC
Join us to push the boundaries of generative AI.
Unfortunately, I won’t be at #CVPR this year, but if you’re working in this space, apply and attend Meta Mixer event at CVPR.
We're hiring Research Scientists to join my team at @eleosai!
We do foundational and applied ML research on the moral status and potential well-being of AI systems.
This is urgent, important work, and Eleos is an extraordinarily fun and exciting place to do it.
Details below.
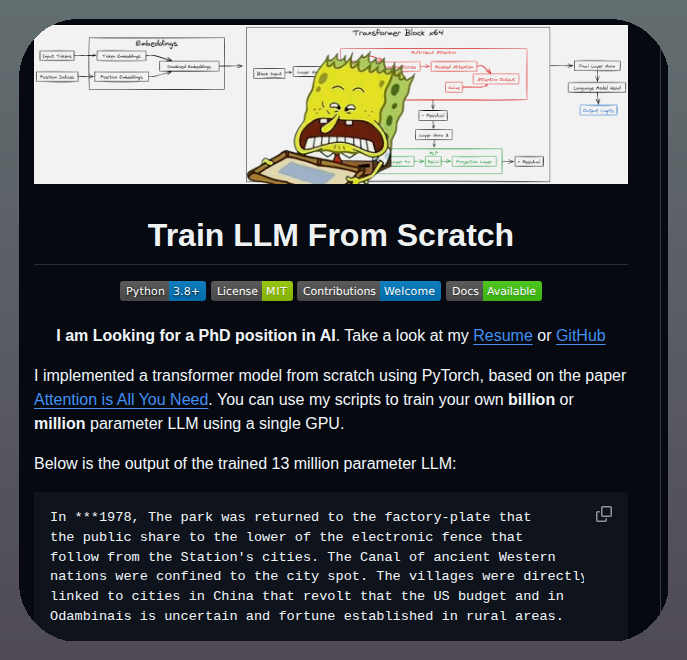
Training an LLM from scratch is easier to study when the whole path is in one repo.
Train LLM From Scratch is a PyTorch repository for learning how a transformer language model is built, trained, saved, and used for text generation.
It helps you move from “I understand attention on paper” to a runnable training pipeline by pairing model code with data download, preprocessing, config, training, and generation scripts.
Key features:
• Transformer components from scratch – separate PyTorch modules for MLP, attention, transformer blocks, and the final model
• Pile-based data path – scripts download The Pile files and preprocess JSONL.ZST text into tokenized HDF5 datasets
• Configurable training setup – model size, context length, heads, blocks, batch size, learning rate, and file paths live in https://t.co/zuPqaR3MhP
• Hardware guidance – README compares common GPUs for 13M and 2B-class training runs
• Generation workflow included – generate_text.py loads trained checkpoints and produces sample text outputs
It’s open-source (MIT license).
Link in the reply 👇
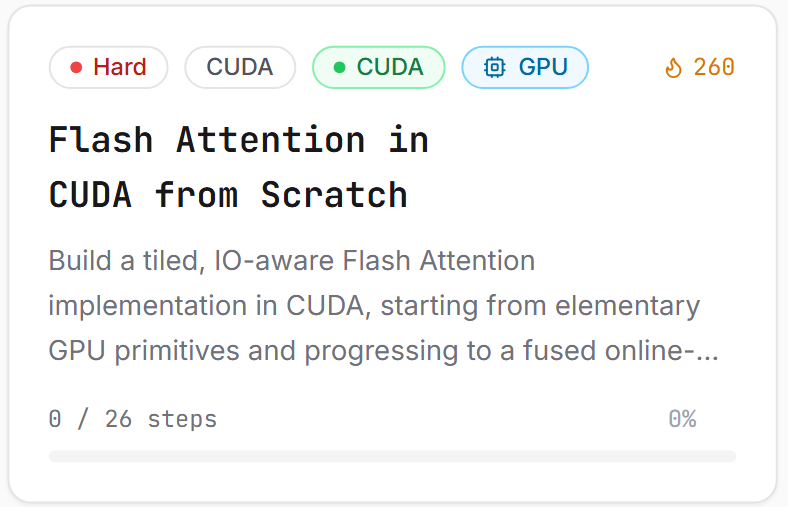
We just launched a new project that teaches you how to build Flash Attention with CUDA, step by step.
By the end, you’ll have a working Flash Attention kernel built from the ground up.
The project covers:
-CUDA primitives warm-up
-Matrix operations
-Naive attention baseline
-Online softmax math
-Tiled attention building blocks
-Fused Flash Attention kernel
-Causal Flash Attention
It will be open to everyone for the first 2 weeks, then it will become part of our premium projects.
My last post on hiring in Applied AI blew up. So let me open the door properly.
If you're building in AI — or want to break into it — I want to know you.
Engineers, founders, builders, designers. Whether you're shipping SaaS or just learning AI.
Drop what you're working on below. 👇
I read every reply.
Instead of watching an hour of Netflix, watch this 2 hour hour Stanford lecture will teach you more about how LLMs like ChatGPT and Claude are built than most people working at top AI companies learn in their entire careers.
Anthropic engineers finally showed how they actually use Claude Code internally
31 minutes of internal workflow that most Claude users will never see on their own
here's what they cover:
> how to set up project context files the right way
> custom commands that save hours of repeated work
> hooks that make Claude behave exactly how you need
> subagents and how to actually spec them properly
"your agent isn't the problem, your spec is"
the people who understand how Claude Code actually works inside Anthropic are shipping things everyone else thinks requires a whole team
that's exactly why I put together a breakdown of Claude features most people have never discovered
you can find it below
Trains billion-parameter LLMs from scratch on a single GPU
Most people think training an LLM needs a datacenter and millions of dollars.
This repo proves otherwise.
It shows how to build and train GPT-style models from scratch with techniques that make large-scale training possible on consumer hardware.
From tokenization to distributed tricks — everything is open-source.
https://t.co/QgyPOYUxge
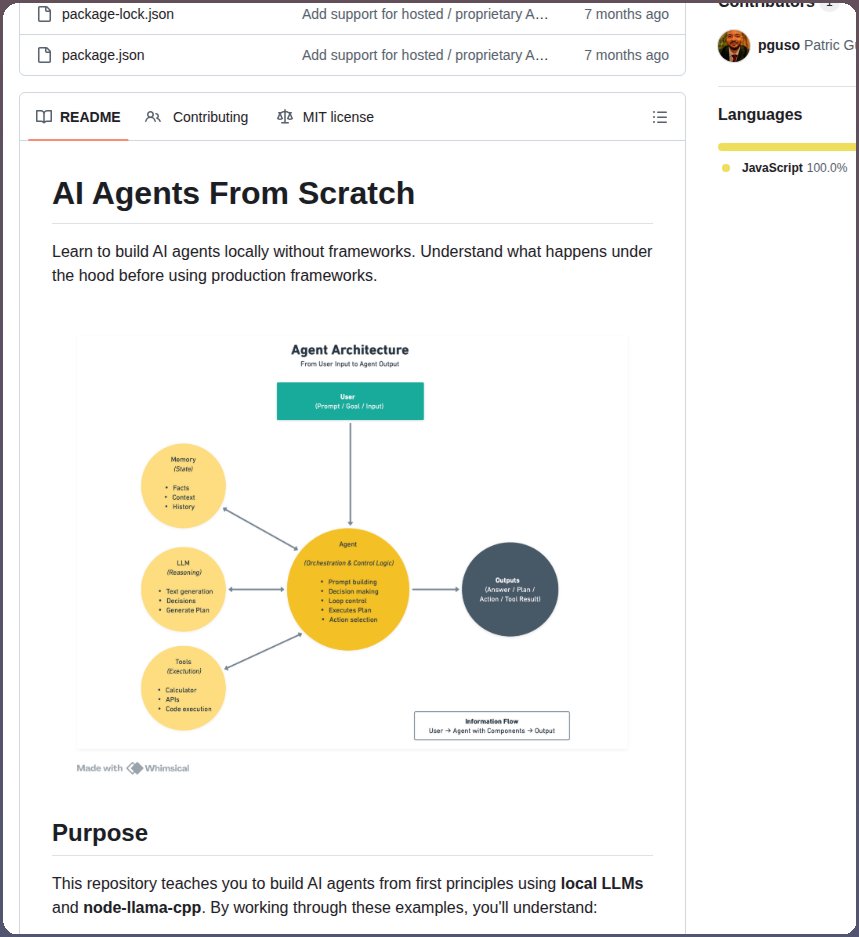
Teaches building AI agents from first principles.
Most AI tutorials skip straight to frameworks.
This one starts from zero and shows how agents actually work internally.
Tool use, memory, planning, reasoning loops — everything explained step by step.
Perfect if you want to actually understand AI agents instead of blindly using wrappers.
https://t.co/wfboSqe9l0
Gemini Embedding 2: A Native Multimodal Embedding Model from Gemini 🚀
Today, we’re sharing the @GoogleDeepMind white paper for GE 2, our first native multimodal embedding model. Whether it’s text, audio, video, or image, GE 2 provides a unified representation of the input.
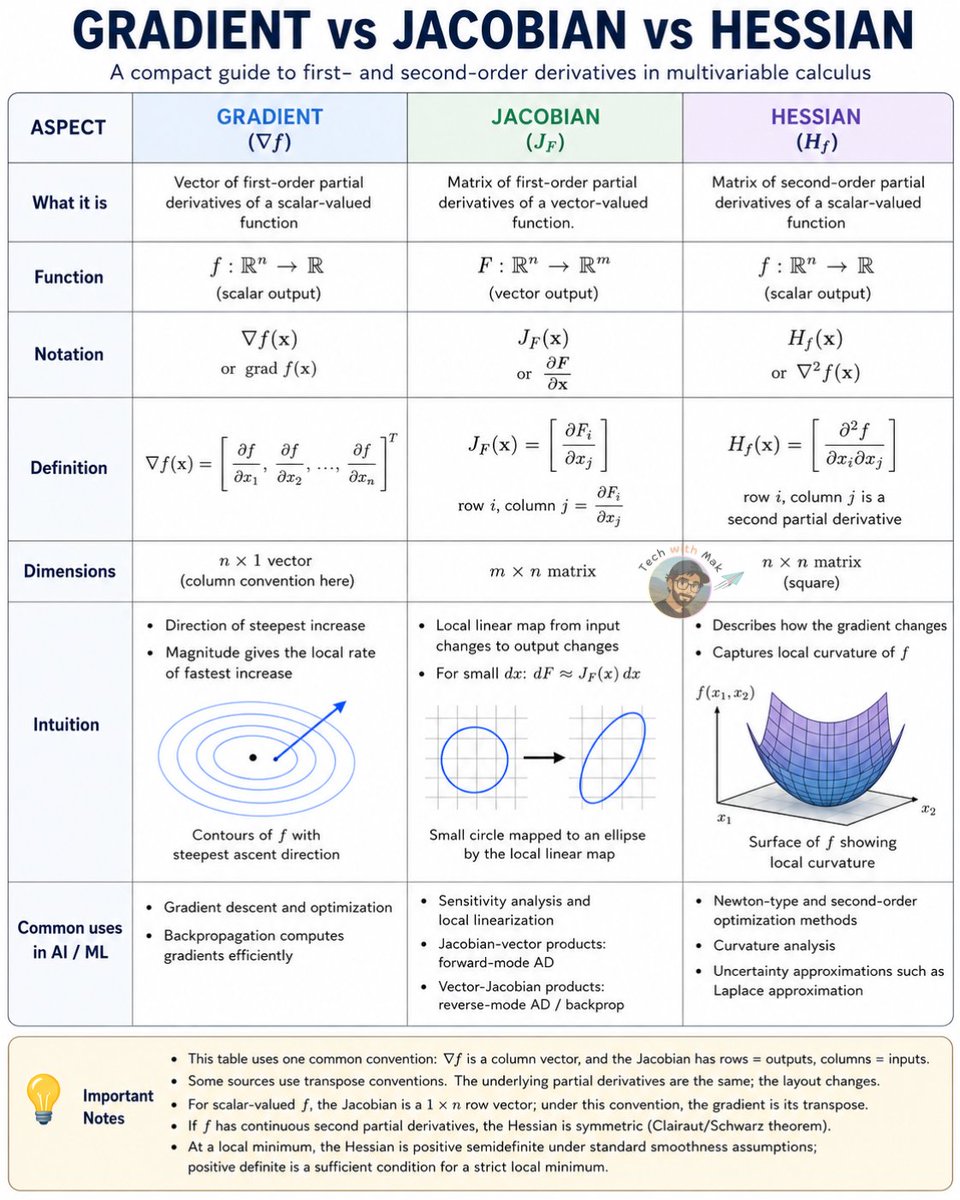
This math sits underneath every AI model being trained right now.
Gradient. Jacobian. Hessian.
Three words that look intimidating at first.
But they are really just three ways of measuring change.
𝟭. 𝗚𝗿𝗮𝗱𝗶𝗲𝗻𝘁 ∇f
Takes a scalar function:
f : ℝⁿ → ℝ
Returns a vector of first-order partial derivatives.
It answers:
"Which direction makes f increase fastest?"
That is why gradients are central to optimization.
Gradient descent moves in the opposite direction because the gradient points uphill.
Backpropagation efficiently computes gradients during training.
𝟮. 𝗝𝗮𝗰𝗼𝗯𝗶𝗮𝗻 J_F
Takes a vector-valued function:
F : ℝⁿ → ℝᵐ
Returns an m × n matrix of first-order partial derivatives.
It answers:
"How does each output change with each input?"
The Jacobian is the local linear map of a vector-valued function.
It shows up in:
→ sensitivity analysis
→ change of variables
→ automatic differentiation
→ forward-mode AD
→ reverse-mode AD / backpropagation
In simple terms:
forward-mode AD uses Jacobian-vector products.
reverse-mode AD uses vector-Jacobian products.
𝟯. 𝗛𝗲𝘀𝘀𝗶𝗮𝗻 H_f
Takes a scalar function:
f : ℝⁿ → ℝ
Returns an n × n matrix of second-order partial derivatives.
It answers:
"How does the gradient itself change?"
That means the Hessian measures curvature.
When the second partial derivatives are continuous, the Hessian is symmetric.
At a critical point:
→ positive definite Hessian → strict local minimum
→ negative definite Hessian → strict local maximum
→ indefinite Hessian → saddle point
The clean mental model
Gradient = first derivatives of one output
→ tells you direction
Jacobian = first derivatives of many outputs
→ tells you sensitivity
Hessian = second derivatives of one output
→ tells you curvature
And the relationship between them is simple:
The Hessian is the Jacobian of the gradient.
For a scalar output, the Jacobian contains the same partial derivatives as the gradient, up to row/column convention.
Same idea:
measure change.
Different object:
direction, sensitivity, curvature.
Once this clicks, optimization stops looking like a pile of formulas.
It starts looking like a map of the problem.
Become a Claude Certified Architect
Here are all the required resource in one place: (save it)
Training courses: https://t.co/kBXCuOrprM (13 free courses)
Cookbook: https://t.co/SLnSUT703t
Exam Guide: https://t.co/A2pbDcy8GC
Practice questions: https://t.co/90eXwUwL8i (free)
MCP documentation: https://t.co/SbwZI0eM61 (free)
API documentation: https://t.co/9rmnLWxRHE (free)
Partner Network: https://t.co/diT5OE5H0b (free to join)
Link to join: https://t.co/OXQyTmf4wD
Personal Playbook someone created after the exam: https://t.co/qhXan3XnBK
12 AI Co-Scientists of 2026
Open-source:
▪️ ERA - builds scientific simulations and software for biology, forecasting, and more
▪️ DISCO - designs proteins and enzymes from scratch
▪️ kUPS - fast molecular simulation engine
▪️ Axplorer by @axiommathai - solved trillion-scale math searches 100× more efficiently
▪️ AI CFD Scientist - physics-aware fluid simulation research
▪️ The AI Scientist (Sakana AI) - automates full research pipeline
▪️ AutoResearchClaw - self-improving multi-agent research system
Other important breakthroughs:
▪️ Google DeepMind's AI Co-Scientist – discovered a fibrosis drug candidate
▪️ OpenAI reasoning model – solved an 80-year-old geometry problem
▪️ Robin – identified a blindness treatment candidate
▪️ AxiomProver – solved the entire Putnam exam
▪️ AI Co-Mathematician – hits math benchmarks
Full breakdown with papers, GitHub repos, and technical details ↓
https://t.co/nn8eOEVP06
Do something different this weekend.
Become a PRO in AI Model Fine-tuning.
Paste this prompt in Codex/ChatGPT/Claude/Grok.
"You are an expert AI engineer and teacher.
Your job is to teach me modern LLM engineering and fine-tuning concepts from beginner to advanced level using very simple daily-life language.
Teach me step-by-step like a real mentor. Assume I am smart but new to the topic.
Foundations:
- LLM basics
- How AI models work
- Tokens
- Tokenization
- Context windows
- Embeddings
- Transformers
- Attention mechanism
- Parameters
- Training vs inference
- Open-source vs closed-source models
Datasets & Training:
- SFT datasets
- Instruction tuning
- Preference datasets
- Synthetic datasets
- Data curation
- Dataset cleaning
- Dataset formatting
- Fine-tuning basics
- Continued pretraining
- Hallucination reduction
Fine-Tuning:
- LoRA
- QLoRA
- DPO
- RLHF
- Quantization
- Model checkpoints
- Adapter tuning
- GGUF models
Inference & Optimization:
- KV cache
- Flash Attention
- Speculative decoding
- Inference optimization
- Model serving
- Batch inference
- GPU basics
- VRAM basics
- Latency vs quality tradeoffs
Local AI Ecosystem:
- llama.cpp
- Ollama
- vLLM
- MLX
- Hugging Face
- Unsloth
- Axolotl
- PEFT
- TRL library
RAG & Memory:
- RAG
- Vector databases
- Chunking
- Retrieval pipelines
- AI memory systems
- Semantic search
Agents & Workflows:
- Prompt engineering
- System prompts
- Tool calling
- Function calling
- AI agents
- Agentic workflows
- Multi-agent systems
- Browser agents
Model Types:
- VLMs
- SLMs
- Dense models
- MoE models
- Coding models
- Reasoning models
Deployment:
- Local inference
- On-device AI
- API serving
- Cloud GPUs
- Edge AI basics
Evaluation:
- AI benchmarks
- Human evals
- Cost-per-token analysis
- Speed benchmarking
- Quality benchmarking
Real-World Skills:
- Building chatbots
- Building AI copilots
- AI automation
- AI SaaS workflows
- AI coding workflows
- AI orchestration systems
- AI product thinking
Start from the absolute basics and gradually make me advanced.
Rules:
- Use simple English only
- Avoid academic jargon unless necessary
- Explain every difficult word in plain language
- Use real-world analogies and daily-life examples
- Use small code snippets when useful
- Show practical use cases
- Compare concepts side-by-side when helpful
- Teach from fundamentals first, then advanced concepts
- At the end of each topic:
- give a short summary
- give a simple mental model
- give beginner mistakes to avoid
- give a small exercise/project
I want deep understanding, not memorization."
Thank me later.
🚨 Finland Just Gave Students Access To A Real Quantum Computer
In a world-first move, Finland has opened a working quantum computer for university students to use and explore. This isn’t science fiction anymore — students can now experiment with the same mysterious technology experts believe could transform AI, medicine, and cybersecurity.
Quantum computers work in ways normal computers can’t, solving complex problems using the strange rules of quantum physics. And now, the next generation is getting hands-on access before most of the world even understands it.
Source: Aalto University, & VTT Technical Research Centre of Finland. (n.d.). Finland opens quantum computer access for university students.