Are EMA teachers commonly used in video SSL (👀V-JEPA family) actually necessary?
Hot take: your EMA teacher is a waste of compute
Introducing SALT. ICLR 2026 🇧🇷 | Led by @XianhangLi at Apple MLR.🧵
Things most Americans agree on:
Groceries cost too much.
Tariffs suck and make no sense.
Congress and Presidents shouldn’t trade stocks.
The debt is a mess.
The border should be secure, but legal immigration is good.
Endless wars are stupid, especially ones that nobody wants and have never been explained.
Americans are exhausted.
AI is like my new best friend that also might be trying to take my job, my ability to think for myself, and my humanity in the process. Yo like I love you, but WTF, but I still love you.
Diversity is actually awesome! The opposite is boring AF.
Canadians are super fucking cool.
Mexicans are chill.
Putin isn’t a good guy looking out for America’s best interest. Rocky IV and Miracle are great movies.
Good neighbors are a blessing.
Freedom of religion and coexistence without having to blow each other up is probably a good idea.
We all question, are we alone in the universe?
We all fuck up along the way.
Epstein didn’t hang himself.
The Trumps and Epstein were best friends for decades. It’s like Bert trying to tell us Ernie was just an acquaintance in the same social scene on Sesame Street back in the day.
The Cowboys suck. Go Birds!
Things we’re told to fight about:
Me.
Laptop.
Vaccines.
Transgenders in sports.
Pronouns.
That’s the joke.
Jürgen Schmidhuber (@SchmidhuberAI ) on The Information Bottleneck podcast 😱
We took a question from the audience about JEPA… and he traced it straight back to 1992
Full episode tomorrow 🧐
@gabriberton Funny to see this poll. I grew up in India and used to hear people pronounce the name with "nee" whereas I am now used to hearing locals say name that ends with "eye". The latter feels natural to me now.
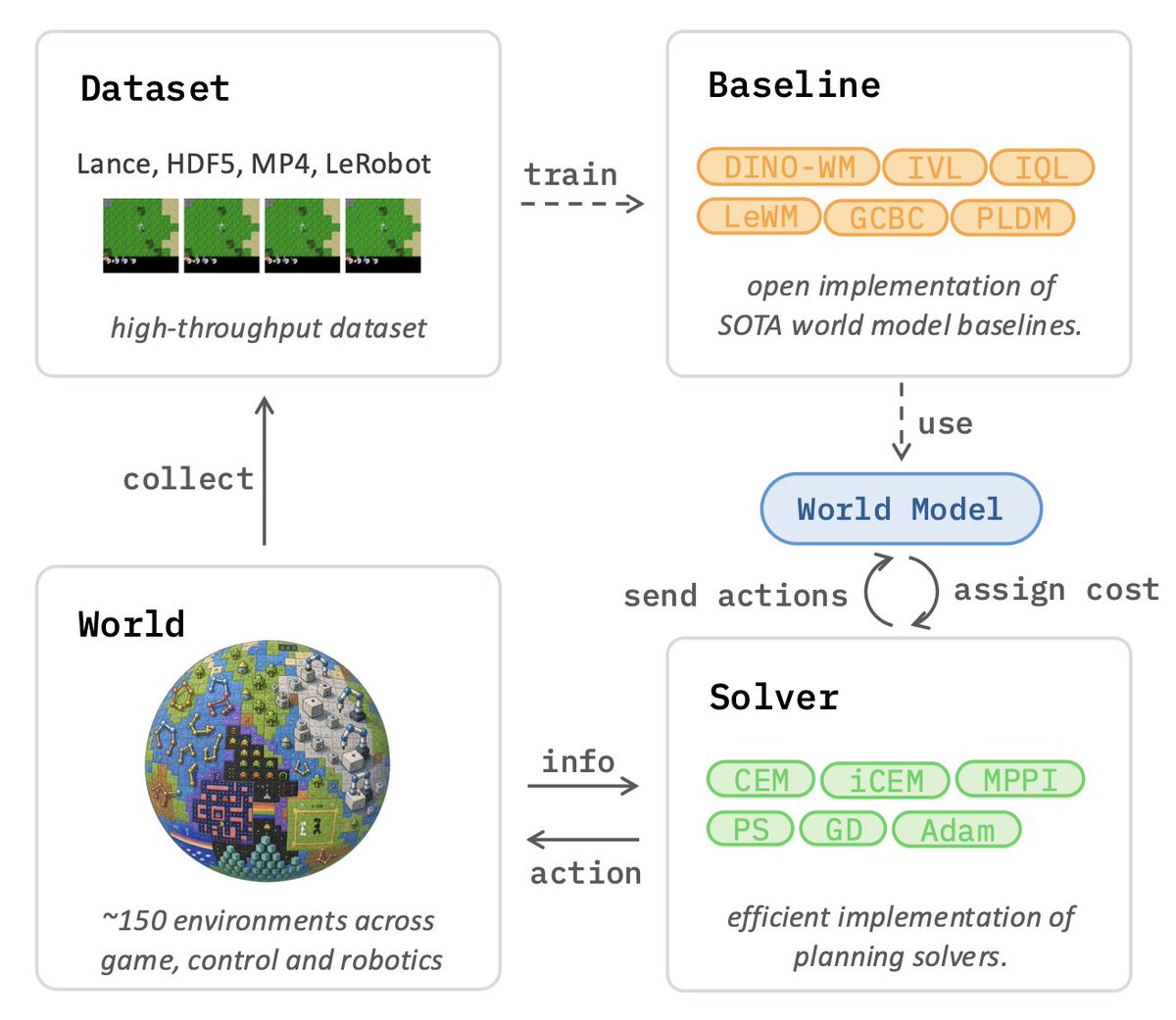
Would you like to join the research effort on JEPA and World Models easily?
After a full year of hard work, we’re excited to finally release stable-worldmodel:
an open-source, scalable platform built to accelerate JEPA & World Model research!
📄: https://t.co/gnxGvens5A
@liuzhuang1234@TaiMingLu Nice work. You might find our empirical work on video interesting especially with the conclusions/observations you make :)
https://t.co/3UWuPuhVO0
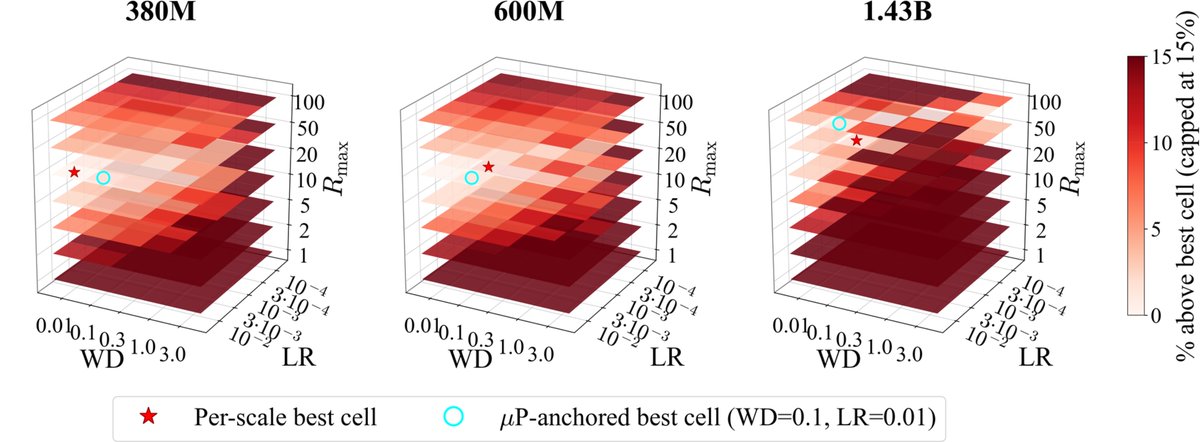
Pre-training is increasingly data-constrained: compute outruns text, models repeat tokens many times, and how much repetition you can afford is an open question. In "Mix, Don't Tune" 🎶 (my @Apple MLR internship), we run ~1000 pre-training runs from 150M to 1.43B params with full HP grids at every scale, to figure out what actually drives performance when target-language data is scarce, and land on a concrete recipe for the data-constrained regime. (1/3)
📃: https://t.co/n8IB4sVeGB
📢📢📢 Velox 🚀: Learning Representations of 4D Geometry and Appearance
In our #CVPR2026 paper, we introduce a method for learning a native 4D representation, useful for many downstream tasks, such as video-to-4D, 3D tracking, cloth simulation, and others!
🌐: https://t.co/MCkCMEftoJ
📝: https://t.co/iLKgrprXlO
Some new results I found surprising that I’m tweeting for Chris (who isnt on here). With enough compute, the best data filter for LMs (on DCLM) might be no filter. Why? Large models can tolerate a surprising amount of nominally 'low quality' data, and can sometimes even benefit.
Yep, they have been working with JEPA for a little while and now have a practical recipe to do even better than existing I/V-JEPAs :).
https://t.co/8UZ2Gk0Ryd
https://t.co/3UWuPuhVO0
Looks like Apple is very interested in JEPA!
What if your AI could “read” an image’s caption to solve visual puzzles?
Apple researchers present TC-JEPA: a new self-supervised method that uses image captions to guide masked patch predictions. By conditioning on text, the model reduces visual uncertainty and learns more semantically meaningful features.
Result: TC-JEPA outperforms contrastive approaches across diverse tasks—especially fine-grained visual understanding and reasoning—while improving training stability and scaling.
As reported in Grokking (arXiv:2201.02177) neural networks can exhibit sudden jumps in test accuracy late in training. We investigate this behavior and uncover an adaptive optimizer anomaly — The Slingshot Mechanism — that causes training instability but promotes generalization.
Slingshot might have been put to bed finally?
Watch out for Adam kiddos. Adam, our evergreen unstable genius :)
https://t.co/B4ZHYDkPnW
CC @deepcohen. I wonder if there are any works that have looked at EoS + finite precision numerics?