Part 1: How does gradient descent work?
https://t.co/avsScLLuDF
Part 2: A simple adaptive optimizer
https://t.co/KehSb1Wu20
Part 3: How does RMSProp work?
https://t.co/t2Cqe67f1M
@roydanroy Could the average person get (somewhat diluted) equity in OpenAI/Anthropic by buying MSFT/Google stock? Genuine question - I’m not a personal finance expert
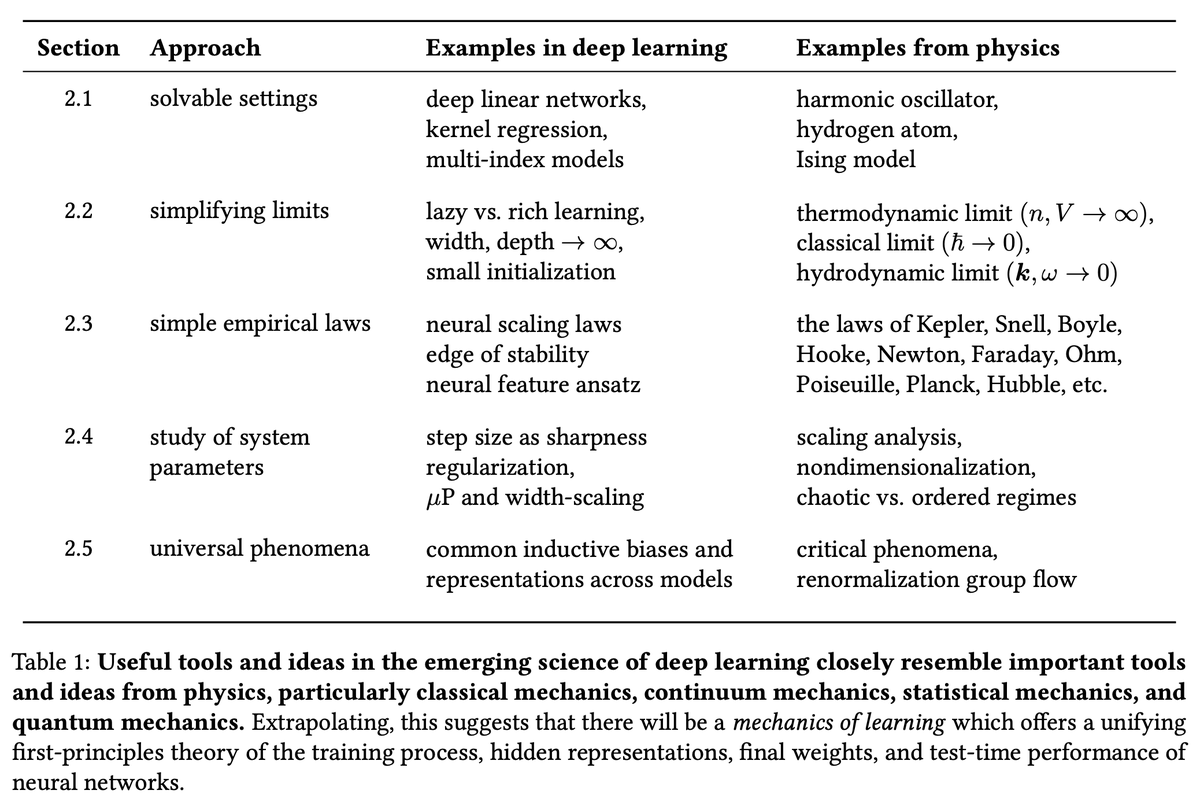
1/ Deep learning is going to have a scientific theory. We can see the pieces starting to come together, and it's looking a lot like physics!
We're releasing a paper pulling together these emerging threads and giving them a name: learning mechanics.
🔨 https://t.co/92nSIHameW 🔧
Looking forward to attending ICLR and giving a talk on Sunday at 9am at the Science of Deep Learning workshop: https://t.co/yTSelQxRzb. Message me if you want to chat about deep learning optimizer dynamics at the conference!
@kalomaze found out i needed a visa from this tweet. applied last night, and went to brazil NYC consulate today (on advice of @marikgoldstein), even though the internet says they don't help with this. it worked - the person at the desk approved my visa. YMMV, but hope this helps someone!
I have spent 4 years making LLMs generalize better without more data or compute. I'm looking for a Research role in industry. Here's what I've built:
1/ Early Weight Averaging → First paper (2023) to apply weight averaging during LM pre-training. Now widely used in many pre-training pipelines. https://t.co/tjVfBIlBHg
2/ Attention Collapse → Diagnosed attention collapse in LLMs and proposed a training fix.https://t.co/eTcmMzMYfd
3/ Curriculum Finetuning → Upweight easy samples and downweight hard ones during finetuning to reduce forgetting. https://t.co/tLhqzUh7nY
I am a PhD student at UT Austin. I have interned at DeepMind, LightningAI, and Amazon Alexa.
If you're hiring or know someone who is, please DM or email ([email protected]).
Web: https://t.co/S6UKjulcyW
#MachineLearning #LLM #NLP #PhD #AIJobs #OpenToWork
AMI Labs founder Yann LeCun on why LLMs are fooling us the same way AI has for decades:
He argues that every generation of AI scientists has made the same mistake: confusing task performance with real intelligence.
LeCun's core challenge to the current hype:
"We're fooled into thinking those machines are intelligent because they can manipulate language. And we're used to the fact that people who can manipulate language very well are implicitly smart."
He's clear that LLMs are useful, but being a useful tool and being intelligent are two very different things.
The real insight is the historical pattern he's lived through.
Since the 1950s, wave after wave of AI researchers have claimed their breakthrough was the path to human-level intelligence.
Marvin Minsky. Herbert Simon. Frank Rosenblatt — who invented the perceptron, the first learning machine, in the 1950s — all predicted machines as smart as humans within a decade.
"They were all wrong."
LeCun has personally witnessed three of these cycles of hype and disappointment. And his verdict on the current one is blunt:
"This generation with LLMs is also wrong. It's just another example of being fooled."
The pattern: A new technique emerges → machines get good at specific tasks → we assume general intelligence
The question worth asking: are we impressed by these tools because they're intelligent, or because they sound like they are?
Introducing Q Labs, a research lab focused on solving generalization.
Alongside others (SSI, Flapping Airplanes), we see data efficiency as the key problem, but we're taking an unconventional approach to solve it: a new learning algorithm approximating Solomonoff induction.
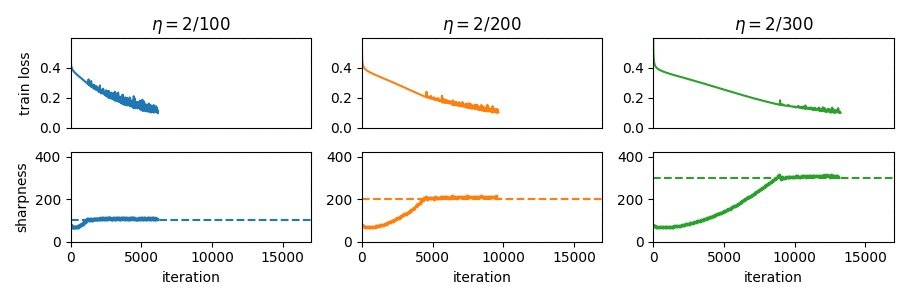
Sharing our recent work on understanding the mechanisms underlying the empirical success of hyperparameter transfer using μP! (1/11)
with Denny Wu and @albertobietti
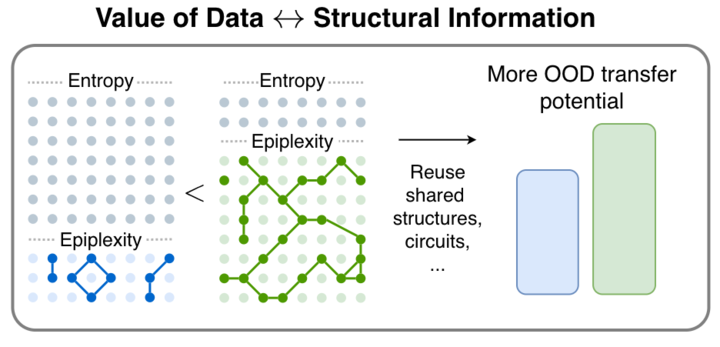
1/🧵 We are very excited to release our new paper! From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence
https://t.co/M8ETQk9gHz
with amazing team @ShikaiQiu@yidingjiang@Pavel_Izmailov@zicokolter@andrewgwils
@cjmaddison@tylerfarghly I agree that theory will probably never give us a closed form expression for the test error of resnet-50 on ImageNet, or eliminate all hyperpameters from deep learning, if that’s what is meant by “the big things”
The goal of deep learning theory/science is to guide practice. But most practical questions are >1 paper away from being legitimately answered by theory. How, then, can we make progress, without access to the ideal reward signal of “does this theory give us a SOTA algorithm?” …
@cjmaddison@tylerfarghly IMO, theory could give us a *language for reasoning* about deep learning. Even with good theory, you’d probably still have to run some experiments, but much fewer than we do now, since you’d learn much more from each one.
So, we should focus on theories that can reliably predict “the small things” about deep learning, and gradually broaden the scope of what we can predict, until we have theory that can reliably predict “the big things” about deep learning too.
A lot of DL theory work gets rightfully criticized for being “postdictive” — always giving an elegant retroactive explanation for SOTA, while somehow never anticipating it. But the real issue isn’t that such theories can’t predict SOTA, it’s that they can’t predict anything.