“Loop engineering” is a hot buzzphrase after mentions of it by Boris Cherny (Claude Code’s creator) and Peter Steinberger (OpenClaw's creator) went viral on social media. Loops are now a key part of how we get AI agents to iterate at length to build software. In this letter, I’d like to share my 3 key loops, shown in the image below, for building 0-to-1 products. These loops guide not just how I build software, but also how I decide what software to build.
Agentic coding loop: Given a product specification and optionally a set of evals (that is, a dataset against which to measure performance), we can have an AI agent write code, test its work, and keep iterating until the code is bug-free and meets its specification. This idea of closing the loop took off around the end of last year, and it has been a game changer in enabling coding agents to work longer productively without human intervention. For example, over the weekend, I was building an app for my daughter to practice typing, and my coding agent could easily work for around an hour, using a web browser to check what it had built multiple times before getting back to me, without needing my intervention.
The engineering loop executes quickly. Every few minutes, the coding agent might build and test a new version of the software. I hear frequently from developers who are finding new ways to engineer more effective engineering loops. This is an active area of invention!
Developer feedback loop: In this loop, a developer examines the current product and steers the coding agent to improve it. Last year, a lot of developers (including me) were acting as the QA (quality assurance) function for our coding agents, manually finding bugs and then asking the agent to fix them. But with coding agents much more able to test their own code, the amount of time we need to spend on this function has decreased significantly. This allows us to make higher-level product decisions, such as what key features to offer, where the UI needs improvement, and so on.
The developer-feedback loop operates over time intervals between tens of minutes and hours — that's how frequently a developer might review a product and give feedback. In the case of the typing app, I changed my mind a few times about the visual design, what cat costumes she can unlock as she learns (she loves cats), and the user flow for a grown-up to log in and steer the child's learning experience.
When a developer has a clear vision for what to build, it is still a lot of work to translate that vision into a specification for a coding agent to implement. Further, after the developer has seen an implementation, they might update (or perhaps clarify) the spec to steer it toward what they want. If you find that the system repeatedly runs into certain problems, building a set of evals for the agent becomes useful.
AI-native teams are increasingly using AI to help shape product direction, for example, automating the gathering and analysis of usage data, summarizing written and verbal customer feedback, or carrying out competitive analysis. However, for pretty much all the products I’m involved in, I see humans as having a significant context advantage over current AI systems — we know a lot more than the AI system about the users and the context the product has to operate in — and thus humans play a critical role. Many people describe this human contribution as “taste,” but I prefer to think of it as humans having a context advantage, since that gives us a clearer path to helping AI systems get better. This also speaks to why this step can’t be automated: So long as the human knows something the AI does not, human-in-the-loop is needed to to inject that knowledge into the system.
External feedback loop: This includes a wide range of tactics like asking a few friends for feedback, launching to alpha testers, or putting the code into production with A/B testing. These tactics are usually slow, rarely taking less than hours and sometimes taking days or even weeks. This data informs the developer vision, which in turn continues to drive the detailed product spec, which in turn drives the coding agent.
With coding agents speeding up software development, more engineers are starting to play a partial product management role. For many engineers who are growing into this role, the hardest part is shaping the product vision and striking a balance between building (bridging the gap between vision and spec) and getting user feedback to evolve the vision. It is important to do both!
I will write more about how to do this in future posts, but for now, I find it encouraging that engineers are playing an expanded role (just as product managers and designers now do more engineering).
[Original text: The Batch]
We recently submitted a confidential S-1. We expect it to leak so we’re just announcing it. We have not decided on timing yet; it may be a while because there are things we want to do that are likely easier as a private company. But it’s a complicated set of tradeoffs and this gives us the option to go public sooner if that ends up being best.
This announcement is being made pursuant to Rule 135 under the Securities Act of 1933, as amended, and does not constitute an offer to sell or the solicitation of an offer to buy any securities. Any offers, solicitations of offers to buy, or any sales of securities will be made in accordance with the registration requirements of the Securities Act.
Everyone is vibe coding. I tried vibe-woodworking.
I asked ChatGPT for IKEA-like bench plans, bought some 2x4s, and built it over a weekend.
It actually turned out great. Smells like pine too.
This was too fun not to share, so I built SlopAndLumber for you to try it too. ↓
Reverse engineering APIs through network requests is one of the most fun things you can do with Claude Code to automate tasks..
SO many websites are impossible to navigate "deterministically" via the DOM (or through screenshots).
So, I just point Claude Code to use browser_harness by @browser_use (or vanilla playwright) and ask it to sniff network requests on the pages that I'm trying to get info on.
And, I just keep clicking around on the sections of data that I want. And, then Claude Code is generally able to go through the logs to figure out what is the right structure for these APIs and what kind of auth do they need (most are cookie based). We also determine what kind of rate limits exist based on trial and error.
I'm able to use that to construct jobs that allow me to get that data programmatically. There are many use cases for this besides scraping. I use this for random side projects (like the travel CLI), for monitoring websites (for intel), and for many many other use cases.
Every website will soon need to be headless, and we'll need to figure out mechanisms for how we have our agents pay these websites programmatically as well.
Just as we have llms.txt for data and structure, we'll soon need tools.txt for agents to determine what tools exist that can be leveraged.
Right now my Codex agent is fully integrated into my smart glasses
Getting projected directly onto my corneas
I walk around my neighborhood. Nobody has any idea I’m shipping
I walk through a park. Kids frolic. Parents laugh. I weep for them.
They’re not locked in. The permanent underclass is coming and they choose to FROLIC instead of SHIP
A child climbs the monkey bars. I silently merge today’s work with main
Another child swings on the swing set. I burn my 20 millionth token of the day
Not a second goes by I don’t have an agent writing code.
I just pray Eight Sleep comes out with a ChatGPT integration soon so I can code while I sleep. That’s the last frontier.
If you’re reading this tweet and do not have an agent terminal open either on your computer or on your face just know tonight I’m praying for you.
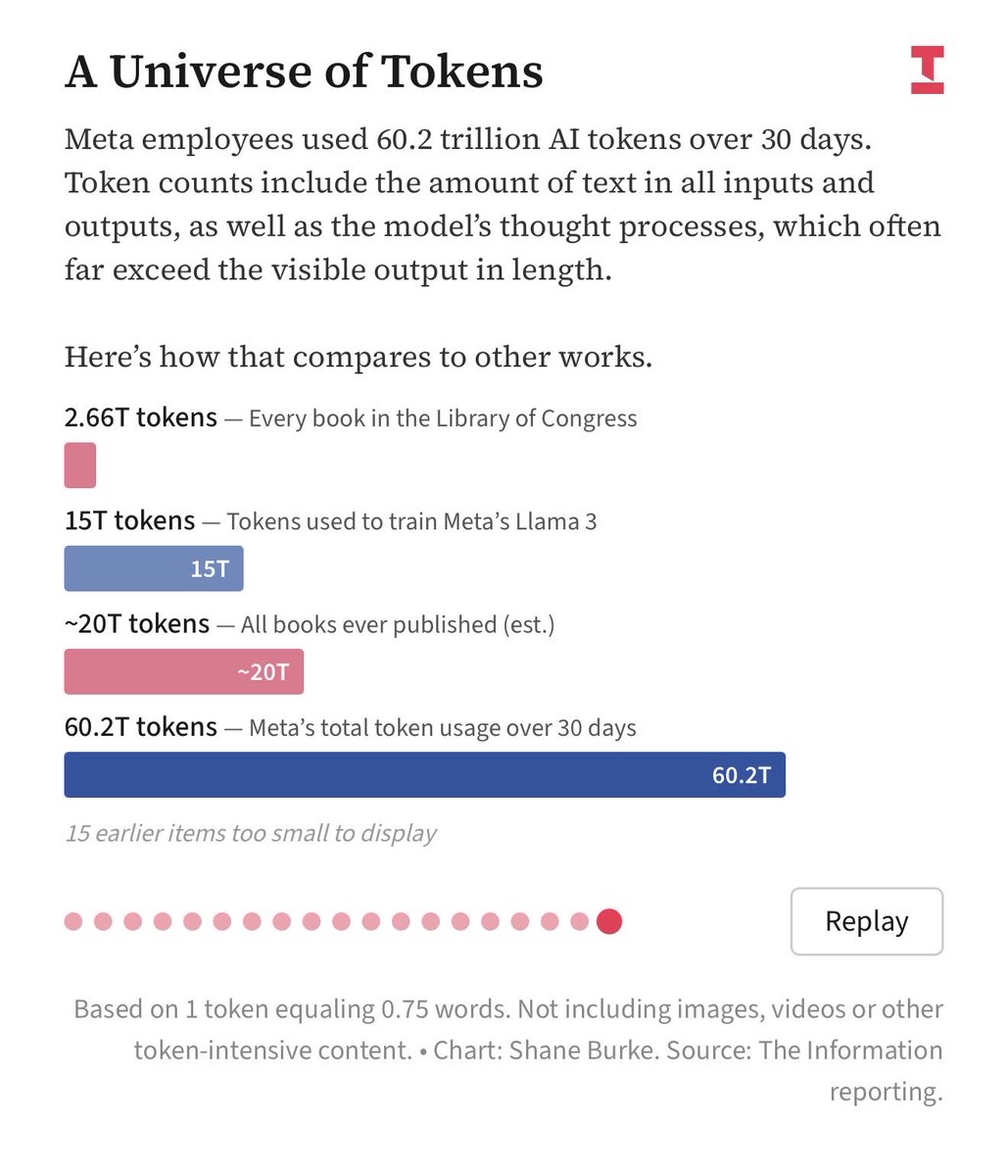
Meta is one third of Anthropic revenue?
60T tokens / mo = $900M / mo = $10B ARR for Anthropic 🤯?
This is also the largest enterprise contract in history.
We see our home planet as a whole, lit up in spectacular blues and browns. A green aurora even lights up the atmosphere. That's us, together, watching as our astronauts make their journey to the Moon.
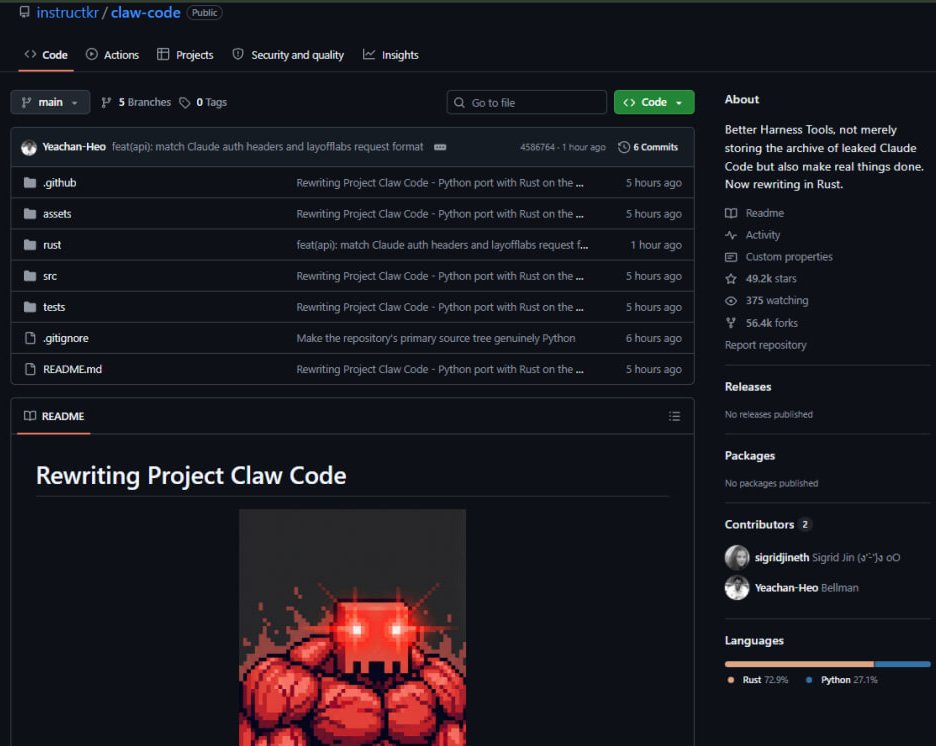
Anthropic accidentally leaked their entire source code yesterday. What happened next is one of the most insane stories in tech history.
> Anthropic pushed a software update for Claude Code at 4AM.
> A debugging file was accidentally bundled inside it.
> That file contained 512,000 lines of their proprietary source code.
> A researcher named Chaofan Shou spotted it within minutes and posted the download link on X.
> 21 million people have seen the thread.
> The entire codebase was downloaded, copied and mirrored across GitHub before Anthropic's team had even woken up.
> Anthropic pulled the package and started firing DMCA takedowns at every repo hosting it.
> That's when a Korean developer named Sigrid Jin woke up at 4AM to his phone blowing up.
> He is the most active Claude Code user in the world with the Wall Street Journal reporting he personally used 25 billion tokens last year.
> His girlfriend was worried he'd get sued just for having the code on his machine.
> So he did what any engineer would do.
> He rewrote the entire thing in Python from scratch before sunrise.
> Called it claw-code and Pushed it to GitHub.
> A Python rewrite is a new creative work. DMCA can't touch it.
> The repo hit 30,000 stars faster than any repository in GitHub history.
> He wasn't satisfied. He started rewriting it again in Rust.
> It now has 49,000 stars and 56,000 forks.
> Someone mirrored the original to a decentralised platform with one message, "will never be taken down."
> The code is now permanent. Anthropic cannot get it back.
Anthropic built a system called Undercover Mode specifically to stop Claude from leaking internal secrets. Then they leaked their own source code themselves. You cannot make this up.
Current-gen LLM "memory" systems make every chatbot feel like a distant relative you met once when you were 7, and you see him again 30 years later and he just assumes you want to talk about dinosaurs some more.














![AndrewYNg's tweet photo. “Loop engineering” is a hot buzzphrase after mentions of it by Boris Cherny (Claude Code’s creator) and Peter Steinberger (OpenClaw's creator) went viral on social media. Loops are now a key part of how we get AI agents to iterate at length to build software. In this letter, I’d like to share my 3 key loops, shown in the image below, for building 0-to-1 products. These loops guide not just how I build software, but also how I decide what software to build.
Agentic coding loop: Given a product specification and optionally a set of evals (that is, a dataset against which to measure performance), we can have an AI agent write code, test its work, and keep iterating until the code is bug-free and meets its specification. This idea of closing the loop took off around the end of last year, and it has been a game changer in enabling coding agents to work longer productively without human intervention. For example, over the weekend, I was building an app for my daughter to practice typing, and my coding agent could easily work for around an hour, using a web browser to check what it had built multiple times before getting back to me, without needing my intervention.
The engineering loop executes quickly. Every few minutes, the coding agent might build and test a new version of the software. I hear frequently from developers who are finding new ways to engineer more effective engineering loops. This is an active area of invention!
Developer feedback loop: In this loop, a developer examines the current product and steers the coding agent to improve it. Last year, a lot of developers (including me) were acting as the QA (quality assurance) function for our coding agents, manually finding bugs and then asking the agent to fix them. But with coding agents much more able to test their own code, the amount of time we need to spend on this function has decreased significantly. This allows us to make higher-level product decisions, such as what key features to offer, where the UI needs improvement, and so on.
The developer-feedback loop operates over time intervals between tens of minutes and hours — that's how frequently a developer might review a product and give feedback. In the case of the typing app, I changed my mind a few times about the visual design, what cat costumes she can unlock as she learns (she loves cats), and the user flow for a grown-up to log in and steer the child's learning experience.
When a developer has a clear vision for what to build, it is still a lot of work to translate that vision into a specification for a coding agent to implement. Further, after the developer has seen an implementation, they might update (or perhaps clarify) the spec to steer it toward what they want. If you find that the system repeatedly runs into certain problems, building a set of evals for the agent becomes useful.
AI-native teams are increasingly using AI to help shape product direction, for example, automating the gathering and analysis of usage data, summarizing written and verbal customer feedback, or carrying out competitive analysis. However, for pretty much all the products I’m involved in, I see humans as having a significant context advantage over current AI systems — we know a lot more than the AI system about the users and the context the product has to operate in — and thus humans play a critical role. Many people describe this human contribution as “taste,” but I prefer to think of it as humans having a context advantage, since that gives us a clearer path to helping AI systems get better. This also speaks to why this step can’t be automated: So long as the human knows something the AI does not, human-in-the-loop is needed to to inject that knowledge into the system.
External feedback loop: This includes a wide range of tactics like asking a few friends for feedback, launching to alpha testers, or putting the code into production with A/B testing. These tactics are usually slow, rarely taking less than hours and sometimes taking days or even weeks. This data informs the developer vision, which in turn continues to drive the detailed product spec, which in turn drives the coding agent.
With coding agents speeding up software development, more engineers are starting to play a partial product management role. For many engineers who are growing into this role, the hardest part is shaping the product vision and striking a balance between building (bridging the gap between vision and spec) and getting user feedback to evolve the vision. It is important to do both!
I will write more about how to do this in future posts, but for now, I find it encouraging that engineers are playing an expanded role (just as product managers and designers now do more engineering).
[Original text: The Batch]](https://pbs.twimg.com/media/HMEtxp3bsAARJdi.jpg)