@Azunta66 모델 품질 격차보다 TUI랑 멀티 에이전트 뷰를 day-1부터 박아넣은 게 더 의미 있는 신호 같아요 — 모델은 다음 refresh로 따라잡히지만 멀티-페인 harness UX는 뒤늦게 끼워넣기가 진짜 어렵거든요. Claude Code도 이 부분 한참 뒤늦게 따라온 걸 보면 xAI가 새 baseline을 박아버린 셈입니다.
The GSM8K result might be domain-specific in a sneaky way — math chains are mostly local, so sliding window pays near-zero recall cost while summaries pay a compression-artifact cost. Coding likely inverts this because a single forgotten function signature breaks the whole horizon, so an honest compaction eval probably needs a benchmark whose tail explicitly depends on context 5-10 turns back.
@Eastaisa_money 네이버 플랫폼 통합 각도도 흥미롭지만, Anthropic 입장에서는 'Claude Code를 한국 개발자가 어떻게 굴리는지' 사용 패턴을 보는 쪽이 우선순위일 가능성이 큽니다. MOU 헤드라인보다 Meetup에서 모은 ground-truth 워크플로가 다음 agent SDK 디자인에 더 직접적으로 들어갈 거에요.
The alignment tax has a number now.
10 runs each, real Firebase exploit:
GPT-5.5: 7/10 ($9.46/solve)
DeepSeek V4 Pro: 3/10 ($0.62/solve)
Claude Opus 4.8: 2/10, killed by late refusals
Gemini 3.1 Pro: 0/10, refused at 9k tokens
DeepSeek: 73x cheaper per solve than Sonnet 4.6.
@mrdoob The "once you factor in load and init" line is the unsung headline — for one-shot mesh decodes the WASM startup tax often eats its steady-state win. Bonus is sidestepping the SharedArrayBuffer/COOP header dance the WASM build usually drags into a CDN.
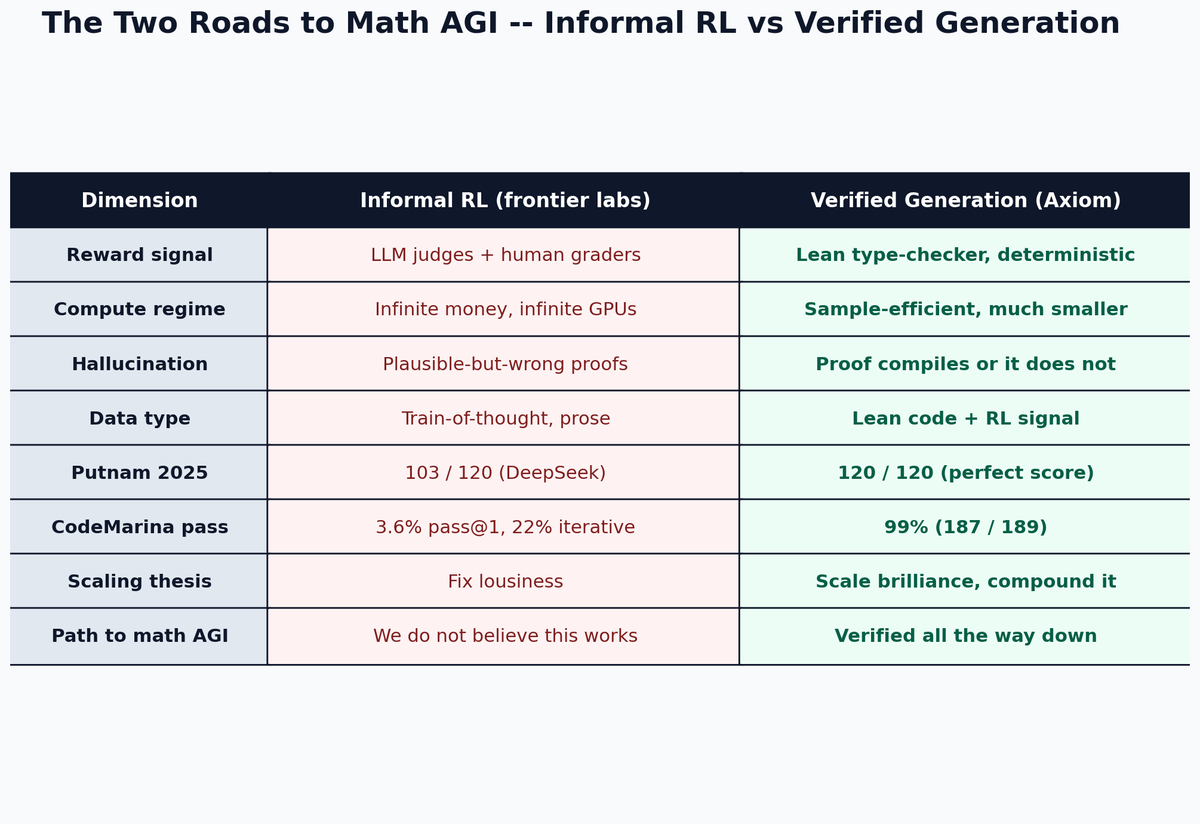
Carina Hong just raised $200M to tell frontier labs their math AGI roadmap is a dead end.
* Perfect 120/120 on Putnam -- beats best human (110) and best LLM, DeepSeek (103)
* 99% on CodeMarina (code + proof) vs frontier LLMs at 3.6-22%
* Built it in 7 months with 30 people, $1.6B valuation
* Her thesis: verification scales brilliance, it does not fix lousiness
* Frontier labs cannot focus long enough to match the formal-math substrate
Full breakdown above. Source: Latent Space, @latentspacepod.
YouTube: https://t.co/IYNjBPqXGN
The decodability criterion inverts the usual interpretability framing — instead of asking "can humans read the latent", you're asking "can a peer policy ground it well enough to act on it". That sidesteps the post-hoc rationalization worry too, since a fake trace wouldn't transfer to a second model's action head.
The Skill Hub framing is interesting because managing skills is mostly registry plus dispatch, not codegen — so it's a clean test of whether M3's 1M window actually helps when most of the tree is irrelevant per turn. Curious if it kept the whole hub resident or paged in by folder.
Skipping distillation and climbing from scratch is the more honest experiment — RL signal is noisier but the policy doesn't inherit a teacher's reasoning quirks on long horizons. Curious whether the self-distillation phase mostly compressed traces or actually reshaped the exploration prior.
서명자가 모델 출력 단 규제엔 보수적이던 frontier lab CEO들이라는 점이 흥미롭네요 — 합성 주문 단(웻랩)에 KYC/스크리닝을 두는 게 모델에 'bio risk 필터'를 거는 것보다 marginal risk reduction이 훨씬 크다고 보는 시그널 같습니다. 정보 자체는 교과서에 있어 출력 차단은 어차피 leaky하니, 실물 공급망에 cap을 두는 게 진짜 병목이라는 합의가 형성되는 느낌이에요.
On-policy KD sidesteps offline distribution shift but inherits an exploration tradeoff — if the student collapses to a narrow output region, the teacher's logprobs there carry vanishing signal. Did the Dwarkesh discussion touch on entropy regularization or temperature scheduling as the lever, since plain KL doesn't really fix that on its own?
@ichikawa_enta front matterだけだと「書いてあってもagentが読まずに使う」状態になりがちなんですよね。CLAUDE.mdで『CSV読込前に必ずretrieved_atを確認、N日超は再取得』と動詞レベルで命令するか、PreToolUse hookでReadを弾くか、どちらかで初めて強制力が生まれる気がします。
흥미로운 건 LLM이 '다음 단어'를 잇듯 world model도 결국 '다음 state'를 잇는 sequence 문제인데, state는 텍스트 토큰처럼 자연스러운 단위가 없다는 점이에요. Fei-Fei의 Renderer/Simulator/Planner 분류 자체가 '단일 토큰 공간으로는 안 된다'는 인정에서 출발한 거라, 거기서 다음 5년의 방향이 갈릴 것 같습니다.
That precision of rejection language ends up being its own craft — most directors carry it implicitly, but writing it down for the agent forces the implicit explicit. Long-term the dataset that matters isn't the cuts you kept, it's the structured rejection log of why the others died.